
POC: Embedding Encryption Key-Version Within Encrypted Payload In Lucee CFML 5.3.8.201
Earlier this week, I mentioned how fascinating it was that password hashing algorithms like bCrypt, sCrypt, and Argon2 all generate opaque tokens in which metadata about the hashing algorithm is stored directly within the resultant hash. This makes it easy(ier) for the hashing algorithm to evolve over time, keeping step with the increasing power of computing. I thought it might be interesting to take this approach and apply it to encrypted values as well. That is, to store the encryption key-version within the encrypted payload itself. As a follow-up to that thought-experiment, I wanted to see what implementing such an approach could look like in Lucee CFML 5.3.8.201.
As a refresher on the concept, instead of storing just the encrypted message, I want to store an opaque token that is a composite of the following values:
- The encryption key version.
- The encryption algorithm (ex,
AES). - The encrypted message.
By storing all of this information in the encrypted payload, we can continue to evolve our encryption workflows over time. And, we can do so without having to run any database schema migrations - such as adding a new column to store the "key version" or the "algorithm".
What this means is that our persisted encrypted values will have a format like this:
v={ key_version },a={ algorithm },{ encrypted_message }
Of course, it's very likely that we didn't actually start out this way. As such, let's also assume that our older encrypted values are just the naked, encrypted message:
{ encrypted_message }
And, for the sake of exploration, let's also assume that in our naive, early days we used the default encryption algorithm in ColdFusion: CFMX_COMPAT. This is a relatively weak encryption algorithm; but, it's the default, so who knew any better, right? Over time, however, we learned that using AES (Advanced Encryption Standard) encryption was much preferred.
To look at how this might work, I'm going to encrypt a number of messages all using different versions of the encryption key and different versions of the encryption algorithm. Then, when I go to decrypt the message, all I have to do is pass-in the message and the metadata about the encryption will be extracted automatically.
CAUTION: In this demo, I have the encryption keys hard-coded in the source code. You never want to do this in production. Encryption keys should always be stored outside of the application for better security.
<cfscript>
encryptionKeys = [
// Let's assume that our very first implementation of encryption used the default
// algorithm, CFMX_COMPAT, the weakest of the algorithms.
1: "ThisIsTheOldCfmxCompatKey",
// Then, we changed our algorithm over to AES (Advanced Encryption Standard) and,
// over time, rotated our keys to have increasing complexity in order to keep pace
// with computer hardware processing power. The following keys were generated with
// the geneateSecretKey() function using 128, 192, and 256 bit sizes respectively.
2: "Aio9pV1k6f1RFM6oVniM8Q==",
3: "H1F6/7/tQfdMn/s5cjyOINK/VG6fkNrJ",
4: "DCdLfVh3bmA24jpUewrjj7trohJADZaJqx7mwfReTME="
];
messageEncrypter = new MessageEncrypter( encryptionKeys, 4 );
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
inputs = [
// Imagine that our first input here represents the very first implementation of
// the encrypted values when we were still using CFMX_COMPAT, before we even
// introduced the idea of key rotation and key versions. This payload will contain
// JUST THE ENCRYPTED MESSAGE, and will be ASSUMED to be using the oldest key.
encrypt( "That's kablamo!", encryptionKeys[ 1 ], "cfmx_compat", "hex" ),
// The rest of the inputs will be "properly versioned" payloads using the much
// more secure AES encryption algorithm.
messageEncrypter.encryptMessage( "That's kablamo!", 2 ),
messageEncrypter.encryptMessage( "That's kablamo!", 3 ),
messageEncrypter.encryptMessage( "That's kablamo!", 4 ),
messageEncrypter.encryptMessage( "That's kablamo!" )
];
// For each input, let's see if we can property decrypt the message.
for ( input in inputs ) {
dump( input );
dump( messageEncrypter.decryptMessage( input ) );
echo( "<br />" );
}
</cfscript>
As you can see, we're taking the string, That's kablamo!, and we're encrypting it using either the CFMX_COMPAT or the AES encryption algorithm. And, we're using different versions of the key. But, in every case, when we go to decrypt the payload, all we do is pass-in the encrypted value:
messageEncrypter.decryptMessage( input )
This is because all the metadata about the encryption key and algorithm is stored in the input itself. Which is why, when we run this ColdFusion code, we get the same decrypted value for all inputs:
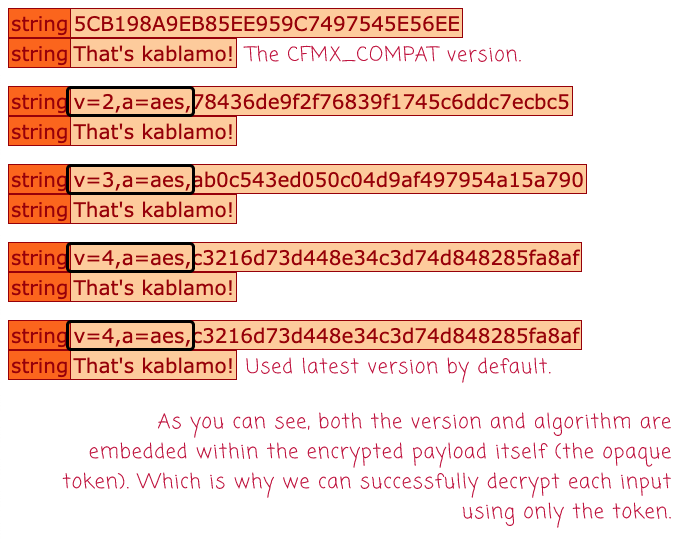
As you can see, we successfully decrypted all of the inputs, even the CFMX_COMPAT values. Notice also that the input isn't just the encrypted message - it's a multi-part opaque token.
And, here what our MessageEncrypter.cfc ColdFusion component looks like - you'll notice that, by default, the encryptMessage() method assumes the most current encryption algorithm metadata:
component
output = false
hint = "I provide methods for encrypting and decrypting messages using key versioning."
{
/**
* I initialize the encrypter with the given keys and the preferred key version.
*/
public void function init(
required struct encryptionKeys,
required numeric desiredKeyVersion,
string desiredAlgorithm = "aes"
) {
variables.encryptionKeys = arguments.encryptionKeys;
variables.desiredKeyVersion = arguments.desiredKeyVersion;
variables.desiredAlgorithm = arguments.desiredAlgorithm.lcase();
// For now, we're hard-coding the encoding for all messages.
variables.desiredEncoding = "hex";
if ( ! encryptionKeys.keyExists( desiredKeyVersion ) ) {
throwVersionNotFoundError( desiredKeyVersion );
}
}
// ---
// PUBLIC METHODS.
// ---
/**
* I decrypt the following input and return the unencrypted message.
*/
public string function decryptMessage( required string input ) {
var segments = parseInput( input );
return( decrypt( segments.message, segments.key, segments.algorithm, segments.encoding ) );
}
/**
* I encrypt the following input using the desired parameters and return the encrypted
* payload.
*/
public string function encryptMessage(
required string message,
numeric keyVersion = desiredKeyVersion,
string algorithm = desiredAlgorithm
) {
var key = encryptionKeys[ keyVersion ];
var algorithm = algorithm.lcase();
var encoding = desiredEncoding;
// The encrypted payload is actually a multi-part opaque token in which the
// encrypted message is last segment. The encrypted payload also includes the key
// version and algorithm used to encrypt the message.
var segments = [
"v=#keyVersion#",
"a=#algorithm#",
encrypt( message, key, algorithm, encoding )
];
return( segments.toList().lcase() );
}
// ---
// PRIVATE METHODS.
// ---
/**
* I parse the opaque token input into the individually addressable segments.
*/
private struct function parseInput( required string input ) {
var segments = input.listToArray();
// Versioned payloads will have a proper list-length.
if ( segments.len() == 3 ) {
var keyVersion = segments[ 1 ].listRest( "=" );
var algorithm = segments[ 2 ].listRest( "=" );
var message = segments[ 3 ];
// Any non-versioned payload is assumed to be using the old CFMX_COMPAT algorithm
// before we changed over to AES and started to version our encryption keys.
} else {
var keyVersion = 1;
var algorithm = "cfmx_compat";
var message = segments[ 1 ];
}
if ( ! encryptionKeys.keyExists( keyVersion ) ) {
throwVersionNotFoundError( keyVersion );
}
return({
message: message,
key: encryptionKeys[ keyVersion ],
algorithm: algorithm,
encoding: desiredEncoding
});
}
/**
* I throw a version not found error when the desired version is not in the list of
* available keys.
*/
private void function throwVersionNotFoundError( required numeric version ) {
throw(
type = "MessageEncrypter.VersionNotFound",
message = "The desired encryption key version was not found in the set of available keys.",
detail = "Desired version: #version#",
extendedInfo = "Available versions: #encryptionKeys.keyList()#"
);
}
}
Anyway, this was just a fun Proof-of-Concept (POC) of what it might look like to embed encryption metadata directly within the encrypted payload itself. I haven't actually done anything like this in production. But, I find it very intriguing.
Want to use code from this post? Check out the license.

Reader Comments
compelling for sure! I've always just embedded the logic in try-retry logic in the code. I first try to decrypt v1, if that fails, I try to decrypt using v2 method. That's as deep as I've gotten so far, so it's not been a huge issue. But I can see the value (and freedom) this approach would offer.
@Chris,
It's funny you mention that because that's exactly how I was doing it during one migration. Basically, I had the old, the new key, and then I had a background task that was running over the table and swapping in the new encrypted value. But, since the background task was going to take a while, the "read" of the value did what you're talking about:
But, the thing I was never sure of was, "Does trying to decrypt with the wrong key throw an error?"
When I tried to decrypt with the wrong key, I was always getting an error - having to do with block padding not being right. But, after hours of Googling (it felt like - not an easy answer to find), articles seemed to indicate that throwing an error was only coincidental and not guaranteed. That, it would be reasonable for the decryption to just return "garbage" if you use the wrong key.
One article even said that the only reason there was an error was because the decryption algorithm did "block validation". And that if you used an algorithm that didn't do any block validation, no error would be thrown.
I'm just trying to remember what I read - and this was months ago so I am sure I am not getting the terminology correct. Honestly, I should have just asked one of the people on the Security team here .... but you know how it goes, always fast fast fast, no time to think sometimes.
Anyway, long-story-short, I think "throwing an error" is not always guaranteed - depends on what type of algorithm you have. This is why I like the explicit version being included.
But, huge caveat, I am not a security expert 😨
Here's one of the articles that I read when I was Googling:
From Is it possible to incorrectly decrypt using the wrong key?
I don't even know if this ^^ context applies to me. But, the problem is that I also don't know enough to know if it doesn't apply to me :D
That's interesting. I actually didn't go the try/catch route at all. I'm basically decrypting a hashed password, so I would first try to decrypt using the OLD hash/salt method. Then, if that failed to match, I would try the NEW hash/salt. If that also failed, only then would I fail the auth attempt.
@Chris,
Ahhh, gotcha. Sorry, I totally misunderstood what you were saying. I didn't realize you had a user input to compare to the decrypted value. In my case, I need to decrypt the value in order to show it to the user. As such, I didn't have anything to compare it to (to validate correctness).