
Ignoring Loopback WebSocket Events From Pusher In Lucee CFML 5.3.8.206
I've been using Pusher WebSockets with ColdFusion for over a decade now and I absolutely love the Pusher SaaS product. It removes all of the complexity around managing a WebSocket platform, allowing me to focus purely on the User Experience (UX) and near-realtime updates within our products. That said, one thing that I've struggled with from the start is dealing with "loopback events". That is, a browser reacting to WebSocket events that the browser itself triggered. To fix this problem, I'm going to start injecting a universally-unique browser ID (a ColdFusion UUID) into my AJAX calls using HTTP interceptors. Then, I'm going to echo that browser UUID in my WebSocket events on the Lucee CFML side of my application.
View this code in my Ignoring Loopback WebSocket Events From Pusher project on GitHub.
There's nothing inherently wrong with a browser receiving and reacting to the WebSocket events that were triggered by that same browser. The problem - for us - is that in almost all of our WebSocket-based workflows, we optimistically react to those same events locally, regardless of the WebSocket. What this means is that we end up doing more data-loading than we would like to:
- User performs action.
- Data is optimistically reloaded in response to that action.
- ColdFusion server makes HTTP API call to Pusher.
- Pusher emits a WebSocket event to all subscribed clients.
- Date is reloaded in response to that WebSocket event.
For all adjacent clients, there's only one data load: the one performed in response to the WebSocket event. However, for the client that emitted the event, we get two data loads: the local, optimistic one and the one triggered by the WebSocket event. This puts unnecessary load on the servers. But, more importantly, it puts unnecessary load on the client, causing data re-rendering and potential DOM-thrashing.
This can lead to "visual jank" and some funky "content flashes" depending on how a given User Interface (UI) has been wired together.
ASIDE: Why perform optimistic data loading in the first place? Why not just defer all re-rendering in reaction to the WebSocket events?
Simple: as much as I love WebSockets, I try to treat them as an "enhancement" to the given experience. Meaning, I try to build the client-side application as if the WebSockets didn't exist at all. This way, if the WebSocket connection is broken, or Pusher is having an incident (which basically never happens), the user experience will still respond to the current user's actions. I always build the application so that WebSockets are never a point of failure, only a potential improvement to the user experience.
To stop this extraneous (and potentially janky) data load from happening, I'm going to start having every instance of the client-side application ignore WebSocket events that the instance itself triggered. I've actually wanted to do this for a long time. However, I was forever blocked by my own dogmatic fears of the ColdFusion request scope.
See, in our ColdFusion applications, there are many layers between the incoming HTTP request and the code that actually makes the HTTP call to Pusher. As such, I envisioned having to retrofit all pathways within the ColdFusion application to pass-down this Browser UUID so that it could then be added to the WebSocket event.
I've finally come to realize (20-years into my career) that my thinking on this matter has been overly narrow and short-sighted. I now understand that, when abstracted properly with clean boundaries, the request scope can be a magical scope that unlocks a lot of helpful behavior. As such, my intention here - with our brownfield ColdFusion applications - is to pluck the Browser UUID out of the incoming HTTP Headers, store it in the request scope, and then have our "Realtime Service" consume that request scope value deep within our ColdFusion callstack.
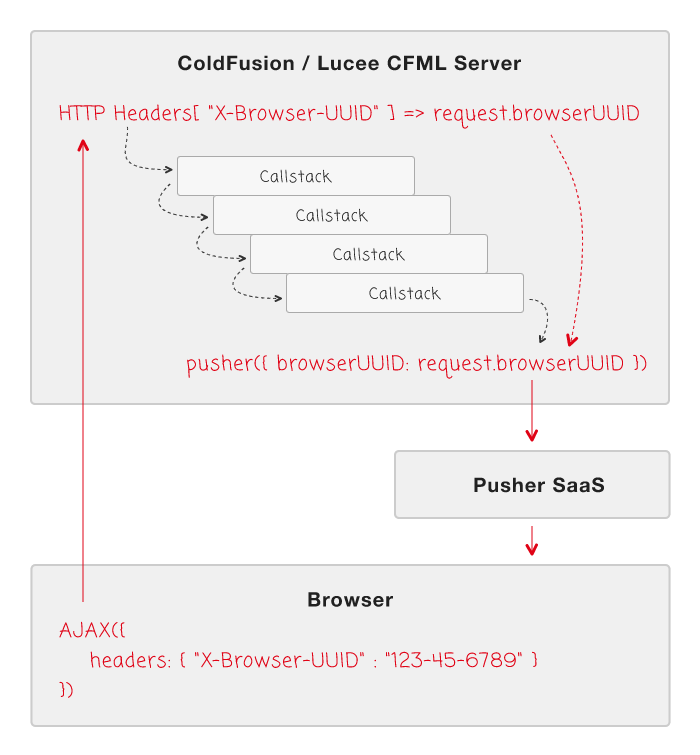
As you can see, the "Browser UUID" is being plucked out of the incoming HTTP Headers at the top of the ColdFusion callstack and getting stored in the request scope. Then, deep within the ColdFusion callstack, it's being pulled out of the request scope and included in the Pusher API call (which is then sent down to all subscribed browsers). All without the callstack itself having to be changed.
To explore this workflow, here's a super simple ColdFusion application component that uses the onRequestStart() life-cycle event handler to read the HTTP headers and augment the request scope:
component
output = false
hint = "I define the ColdFusion application settings and event-handlers."
{
// Define application settings.
this.name = "PusherClientIdRoundTrip";
this.applicationTimeout = createTimeSpan( 0, 1, 0, 0 );
this.sessionManagement = false;
this.directory = getDirectoryFromPath( getCurrentTemplatePath() );
this.root = "#this.directory#../";
// Define per-application mappings.
this.mappings = {
"/lib": "#this.root#lib"
};
// ---
// PUBLIC METHODS.
// ---
/**
* I get called once at the start of each incoming ColdFusion request.
*/
public void function onRequestStart() {
var httpHeaders = getHttpRequestData( false ).headers;
// When the browser is making AJAX calls to the API, it's going to inject a UUID
// for each client into the incoming HTTP Headers. Let's pluck that out and store
// it in the REQUEST scope where it can be globally-available across the
// processing of the current request.
request.browserUuid = ( httpHeaders[ "X-Browser-UUID" ] ?: "" );
}
}
As you can see, I'm taking the X-Browser-UUID HTTP header and I'm storing it in the request scope as browserUuid. Now, imagine that deep down inside the callstack of a ColdFusion API route we have to make a call to Pusher to publish the mutation of the system. For this demo, there is no "deep callstack"; but, use your imagination:
<cfscript>
config = deserializeJson( fileRead( "../config.json" ) );
// For the sake of simplicity, I'm just re-creating the Pusher ColdFusion component on
// every request. In a production context, I would cache this in the Application scope
// or a dependency-injection (DI) container.
pusher = new lib.Pusher(
appID = config.pusher.appID,
appKey = config.pusher.appKey,
appSecret = config.pusher.appSecret,
apiCluster = config.pusher.apiCluster
);
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
// This event will be pushed to ALL CLIENTS that are subscribed to the demo-channel,
// including the browser that made THIS API call in the first place. In order to help
// prevent the origin browser from responding to this event, let's echo the browser
// UUID in the event payload.
// --
// NOTE: The Pusher API provides a mechanism for ignoring a given SocketID when
// publishing events. However, the part of our client-side code that makes the AJAX
// calls doesn't know anything about Pusher (or the state of the connection). As such,
// there's no SocketID to be injected into the AJAX call.
pusher.trigger(
channels = "demo-channel",
eventType = "click",
message = {
browserUuid: ( request.browserUuid ?: "" )
}
);
</cfscript>
Here, I'm taking that request.browserUuid value and I'm including it within the outgoing Pusher API call. I didn't have to pass it down through all the method calls - I'm just using the globally available request scope as a magical bag that holds arbitrary request data.
And now that we have our ColdFusion application server accepting and propagating a unique ID for each browser, let's look at how we can provide and then consume this unique ID on the client-side.
To keep this as simple as possible, all I'm doing in this JavaScript demo is tracking click events and incrementing a locally-stored counter. You'll notice in my click-handler, I'm both updating the counter locally and making an AJAX call to my ColdFusion API to emit the "click" event globally. Then, in my Pusher WebSocket event-handler, I'm using that browser UUID to determine if I should ignore the event or use it to increment the counter:
<cfscript>
config = deserializeJson( fileRead( "../config.json" ) );
// In order to setup the Pusher client in the browser, we need to pass-down some of
// configuration data. DO NOT SEND DOWN APP SECRET!
clientConfig = serializeJson({
appKey: config.pusher.appKey,
apiCluster: config.pusher.apiCluster,
});
</cfscript>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>
Ignoring Loopback WebSocket Events From Pusher In Lucee CFML 5.3.8.206
</title>
</head>
<body style="user-select: none ;">
<h1>
Ignoring Loopback WebSocket Events From Pusher In Lucee CFML 5.3.8.206
</h1>
<!---
This counter value will be incremented both locally via click-handlers and
remotely via Pusher WebSockets. The goal is not to keep the counter in sync across
clients, only to emit events across clients (keeping the demo super simple).
--->
<div class="counter" style="font-size: 40px ;">
0
</div>
<script type="text/javascript" src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script type="text/javascript" src="https://js.pusher.com/7.0/pusher.min.js"></script>
<script type="text/javascript">
var config = JSON.parse( "<cfoutput>#encodeForJavaScript( clientConfig )#</cfoutput>" );
// Let's assign a universally-unique ID to every browser that the app renders.
// This UUID will be "injected" into each outgoing API AJAX request as an HTTP
// header. This is not specifically tied to the Pusher functionality; but, will be
// used to prevent "loopback" events.
var browserUuid = "browser-<cfoutput>#createUuid().lcase()#</cfoutput>";
// --------------------------------------------------------------------------- //
// --------------------------------------------------------------------------- //
var pusher = new Pusher(
config.appKey,
{
cluster: config.apiCluster
}
);
var channel = pusher.subscribe( "demo-channel" );
// Listen for all "click" WebSocket events on our demo channel.
channel.bind(
"click",
function handleEvent( data ) {
console.group( "Pusher Event" );
console.log( data );
// When the ColdFusion server sends a "click" event to the Pusher API,
// Pusher turns around and sends that event to every client that is
// subscribed on the channel, including THIS BROWSER. However, since we're
// OPTIMISTICALLY INCREMENTING THE COUNTER LOCALLY, we don't want to ALSO
// increment it based on the WebSocket event. As such, we want to ignore
// any events that were triggered by THIS browser.
if ( data.browserUuid === browserUuid ) {
console.info( "%cIgnoring loopback event from local click.", "background-color: red ; color: white ;" );
console.groupEnd();
return;
}
console.info( "%cAccepting event from other browser.", "background-color: green ; color: white ;");
console.groupEnd();
// ASIDE: Couldn't we just use a "User ID" to ignore loopback events? No.
// Even if we included the originating "user" in the event, that's still
// not sufficient. A single user may have MULTIPLE BROWSER TABS open. And,
// we don't want to ignore the event in all browser tabs for that user -
// we only want to ignore the event in the single browser tab that
// optimistically reacted to an event.
// --
// If this event came from a DIFFERENT browser, then let's update our
// count locally to reflect the event.
incrementCounter();
}
);
// --------------------------------------------------------------------------- //
// --------------------------------------------------------------------------- //
// Each count will be locally-stored in the browser. The point of this demo isn't
// to synchronize the counts across browsers, it's to prevent loopback event
// processing for a single browser.
var counter = $( ".counter" );
var count = Number( counter.html().trim() ); // Initialize counter from DOM state.
jQuery( document ).click( handleDocumentClick );
/**
* I handle clicks on the document, using them to trigger click API calls.
*/
function handleDocumentClick( event ) {
// OPTIMISTICALLY increment the counter locally.
incrementCounter();
// Make an API call to trigger the click event on all Pusher-subscribed
// clients. We're including the browser's UUID so that we can later ignore
// loopback events for this client.
// --
// NOTE: In this demo, there's only one action. But, try to imagine that this
// headers{} object was being augmented in a central location using an API
// client or something like an HTTP Interceptor - some place that knows
// nothing about Pusher or WebSockets.
$.ajax({
method: "post",
url: "./api.cfm",
headers: {
"X-Browser-UUID": browserUuid
}
});
}
/**
* I increment the current count and render it to the DOM.
*/
function incrementCounter() {
counter.html( ++count );
}
</script>
</body>
</html>
Since the behaviors in this demo necessarily require more than one browser to illustrate, it can be hard to visualize in your head. To help, here's a GIF of the behavior when making click events across two different browsers:
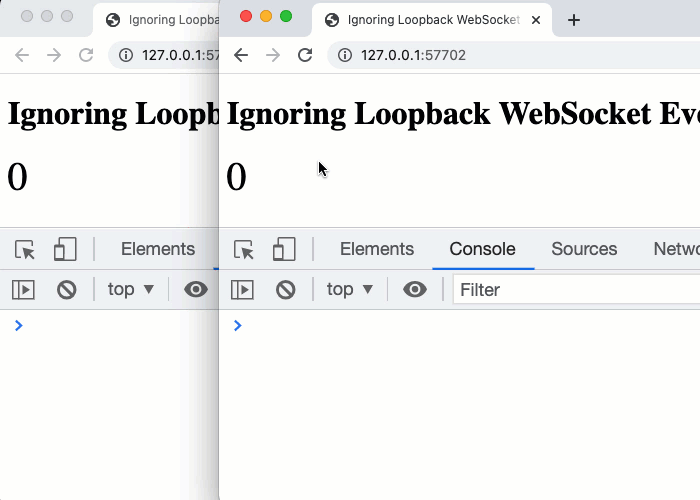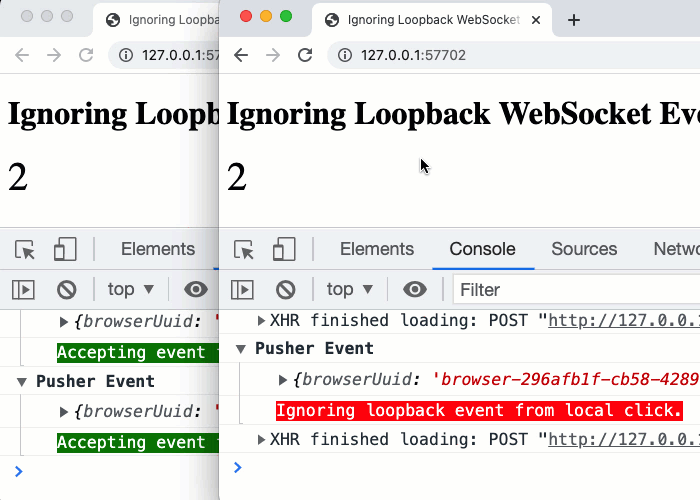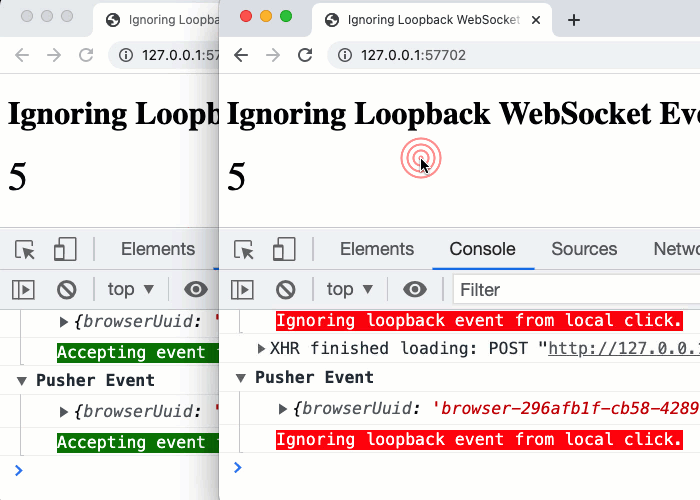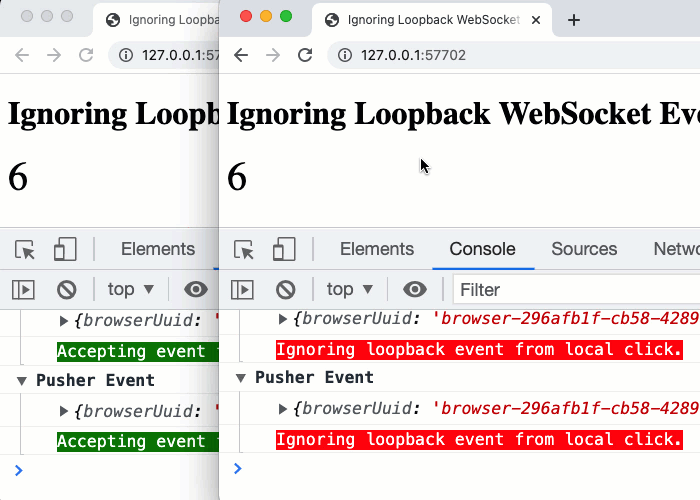
As you can see, with two browsers side-by-side, the browser that is initiating the click-event is ignoring the Pusher loopback events - the events that contain the browserUuid that matches its own UUID. And, the adjacent browser - the one that did not initiate the events - is happily consuming the Pusher events and using them to increment its local counter, keeping it in sync with the other browser.
What I really like about this approach is how easy it will be to layer into my existing ColdFusion and Pusher applications. Since I'm not updating the method signatures in the callstack, all I'll have to do is sprinkle in the code that you see in this demo: a little "ignore logic" in the browser, a little request scope population in the application routing, and a little request scope consumption in my low-level "realtime service" call. And, I'm hoping it should "just work."
My Pusher API Client Implementation in Lucee CFML
This is not terribly relevant for this post, but as part of this exploration, I took my decades-old implementation of Pusher.cfc for ColdFusion 10 and rewrote it for modern Lucee CFML. It's so nice that cryptographic hashing is now a core part of the ColdFusion platform and not something I have to build using the low-level Java interactions:
component
output = false
hint = "I provide methods for interacting with the Pusher App API."
{
/**
* I initialize the Pusher client with the given application settings.
*/
public void function init(
required string appID,
required string appKey,
required string appSecret,
required string apiCluster,
numeric defaultTimeout = 10
) {
variables.appID = arguments.appID;
variables.appKey = arguments.appKey;
variables.appSecret = arguments.appSecret;
variables.apiCluster = arguments.apiCluster;
variables.defaultTimeout = arguments.defaultTimeout;
// When sending an event to multiple channels at one time, the Pusher API only
// allows for up to 100 channels to be targeted within a single request. If an
// event needs to go to more channels, the groupings will be spread across
// multiple HTTP requests.
variables.maxChannelChunkSize = 100;
variables.newline = chr( 10 );
}
// ---
// PUBLIC METHODS.
// ---
/**
* I trigger the given event on the given channel (singular) or set of channels.
*
* CAUTION: Since the API request may need to be split across multiple HTTP requests,
* based on the number of channels being targeted, the overall API request workflow
* should NOT be considered as atomic. One "chunk" of channels may work and then a
* subsequent "chunk" may fail. As such, it is recommended that each API request be
* kept under the max-channel limit.
*/
public void function trigger(
required any channels,
required string eventType,
required any message,
numeric timeout = defaultTimeout
) {
// When sending an event to multiple channels, there is a cap on how many channels
// can be designated in each request. As such, we have to chunk the channels up
// into consumable groups.
var channelChunks = isSimpleValue( channels )
? buildChannelChunks( [ channels ] )
: buildChannelChunks( channels )
;
var serializedMessage = serializeJson( message );
for ( var channelChunk in channelChunks ) {
makeApiRequest(
method = "POST",
path = "/apps/#appID#/events",
body = serializeJson({
name: eventType,
data: serializedMessage,
channels: channelChunk
}),
timeout = timeout
);
}
}
// ---
// PRIVATE METHODS.
// ---
/**
* I split the given collection of channels up into chunks that can fit into a single
* API request.
*/
private array function buildChannelChunks( required array channels ) {
var chunks = [];
var chunk = [];
for ( var channel in channels ) {
chunk.append( channel );
// If the current chunk has reached capacity, move onto the next chunk.
if ( chunk.len() == maxChannelChunkSize ) {
chunks.append( chunk );
chunk = [];
}
}
// Since chunks are appended only when a new chunk is being created, let's gather
// the last chunk if it has any channels in it.
if ( chunk.len() ) {
chunks.append( chunk );
}
return( chunks );
}
/**
* I generate the API request signature for the given request values.
*/
private string function generateSignature(
required string method,
required string path,
required string authKey,
required string authTimestamp,
required string authVersion,
required string bodyMd5,
) {
var parts = [
method, newline,
path, newline,
"auth_key=#authKey#&",
"auth_timestamp=#authTimestamp#&",
"auth_version=#authVersion#&",
"body_md5=#bodyMd5#"
];
// CAUTION: Signature MUST BE LOWER-CASE or it will be rejected by Pusher.
var signature = hmac( parts.toList( "" ), appSecret, "HmacSHA256", "utf-8" )
.lcase()
;
return( signature );
}
/**
* I make the HTTP request to the Pusher API. The parsed payload is returned; or, an
* error is thrown if the HTTP request was not successful.
*/
private struct function makeApiRequest(
required string method,
required string path,
required string body,
required numeric timeout
) {
var domain = ( apiCluster.len() )
? "https://api-#apiCluster#.pusher.com"
: "https://api.pusher.com"
;
var endpoint = "#domain##path#";
var bodyMd5 = hash( body, "md5" ).lcase();
var authKey = appKey;
// The authentication timestamp must be in Epoch SECONDS. Pusher will reject any
// request that is outside of 600-seconds from the current time.
var authTimestamp = fix( getTickCount() / 1000 );
var authVersion = "1.0";
var authSignature = generateSignature(
method = method,
path = path,
authKey = authKey,
authTimestamp = authTimestamp,
authVersion = authVersion,
bodyMd5 = bodyMd5
);
http
result = "local.httpResponse"
method = method
url = endpoint
charset = "utf-8"
timeout = timeout
getAsBinary = "yes"
{
httpParam
type = "header"
name = "Content-Type"
value = "application/json"
;
httpParam
type = "url"
name = "auth_key"
value = authKey
;
httpParam
type = "url"
name = "auth_signature"
value = authSignature
;
httpParam
type = "url"
name = "auth_timestamp"
value = authTimestamp
;
httpParam
type = "url"
name = "auth_version"
value = authVersion
;
httpParam
type = "url"
name = "body_md5"
value = bodyMd5
;
httpParam
type = "body"
value = body
;
}
// Even though we are asking the request to always return a Binary value, the type
// is only guaranteed if the request comes back successfully. If something goes
// wrong (such as a "Connection Failure"), the fileContent will still be returned
// as a simple string. As such, we have to normalize the extracted payload.
var fileContent = isBinary( httpResponse.fileContent )
? charsetEncode( httpResponse.fileContent, "utf-8" )
: httpResponse.fileContent
;
if ( ! httpResponse.statusCode.reFind( "2\d\d" ) ) {
throw(
type = "Pusher.NonSuccessStatusCode",
message = "Pusher API returned with non-2xx status code.",
extendedInfo = serializeJson({
method: method,
endpoint: endpoint,
statusCode: httpResponse.statusCode,
fileContent: fileContent
})
);
}
try {
return( deserializeJson( fileContent ) );
} catch ( any error ) {
throw(
type = "Pusher.JsonParseError",
message = "Pusher API response could not be parsed as JSON.",
extendedInfo = serializeJson({
method: method,
endpoint: endpoint,
statusCode: httpResponse.statusCode,
fileContent: fileContent
})
);
}
}
}
If you haven't tried using Pusher for WebSockets, I highly recommend it. Imagine not having to worry about WebSocket infrastructure or horizontally scaling servers to manage load. Well, that's what Pusher gives you.
Want to use code from this post? Check out the license.

Reader Comments
For anyone implementing something similar, keep in mind that you can't use
X-Browser-UUIDfor any kind of authentication/verification. So you would not want to use a session ID or anything like that because you'd be announcing this value to all clients listening to the websocket.I'd suggest a more secure method would be to generate a random
X-Transaction-IDheader that's generated for each transaction and then just have the browser ignore transactions it initiated. While less secure, you could have theX-Transaction-IDcontain a signature which you could use to ignore the requests (instead of tracking each request within the client). A benefit to passing in a unique value for each transaction is you have something you could tie to logging.Just some ideas that came to mind listening to the video.
Have a great weekend!
@Dan,
That's a good callout - the UUID being passed around here is not intended to be secure and should be used for anything that has security implications. In this case, since I'm using it as a means to "debounce" the events, more or less, there's nothing to worry about.
That's an interesting idea about using some sort of Transaction-ID. On the ColdFusion side of the world, we actually do create UUID that is associated with the request that is used for logging (and gets propagated to other server-side calls made via
CFHttp). I'd never considered actually generating those UUIDs on the client and then passing them to the server. There could be some interesting stuff there.That said, the client would - at least temporarily - have to keep a list of transaction IDs to compare against future WebSocket events. Not hard to do - but, it does add some complexity (when compared to a static value comparison).
@All,
Over on Twitter, Hanna from Pusher asked me about why I didn't use their native Exclude event recipients feature:
https://pusher.com/docs/channels/server_api/excluding-event-recipients/
This feature works by passing-along the Socket ID of the Pusher WebSocket connection. So, essentially, instead of me passing around
browserUuid, I could have passed aroundconnection.socket_id. And, on the server-side, when calling the Pusher API, I could have included that socket ID so that Pusher wouldn't publish the event to that socket (ie, the initiating browser) when broadcasting the event.The reason I didn't do this probably has more to do with my client-side application architecture than anything else. I am using Angular(JS), which uses modular services and dependency-injection (DI) to wire everything together. And, in my case, the service that binds the app to the Pusher WebSockets is "far away from" the service that acts as the HTTP Client for our AJAX requests.
By creating a
browserUuidin the app bootstrapping process:... it gives me something that I can then inject into both the Pusher service as well as the HTTP Client:
This way, the HTTP client doesn't have to know anything about Pusher - or how its connection state may change over time. The two services just need to agree on the one shared token,
browserUuid.That said, I could probably just inject the
pusherServiceinto thehttpClient, and reference theconnection.socket_idthat way. It might be worth a follow-up exploration of this so that I can wrap my head around how the native Pusher functionality works.