
Case Study: Removing Implicit Variable Access At Scale In Lucee CFML 5.3.7.47
In ColdFusion and Lucee CFML, when you refer to an unscoped variable, the runtime will "walk up" a series of scopes looking for said variable. The number of potential scopes to be inspected changes based on the calling context, application settings, and runtime version. In 99.99% of cases, I never worry about the performance of unscoped variable access, also known as "implicit variable access". But, this morning, I was running code that was being invoked with high, repetitive volume within a single request. And, it turns out that implicit variable access actually made a meaningful difference in the rendering speed of the request. As such, I thought it would be fun to share this particular case study in Lucee CFML 5.3.7.47.
As I mentioned last week, I'm creating a DSL (Domain Specific Language) for rendering HTML emails in Lucee CFML. Part of this approach entails creating ColdFusion Custom Tags to represent normal HTML elements. So, instead of just using the normal paragraph tag in an email:
<p>
... you would use a custom tag (in this case html is the prefix assigned to the custom tag library for "native elements"):
<html:p>
As you can imagine, a given email may have hundreds or even thousands of native HTML elements that now get represented as ColdFusion custom tags. And, inside each of these custom tags, there is logic that may refer to a variable. So, unlike a typical server request, which may have dozens of function calls, rendering an HTML email with custom tags may have hundreds of function calls.
These function calls add up; and, the the variable-access that they require adds up as well. Which is why, when I turned on Application Debugging for a given email, I was surprised/not-surprised to see that it was taking over a second (which is "forever" in request processing time):
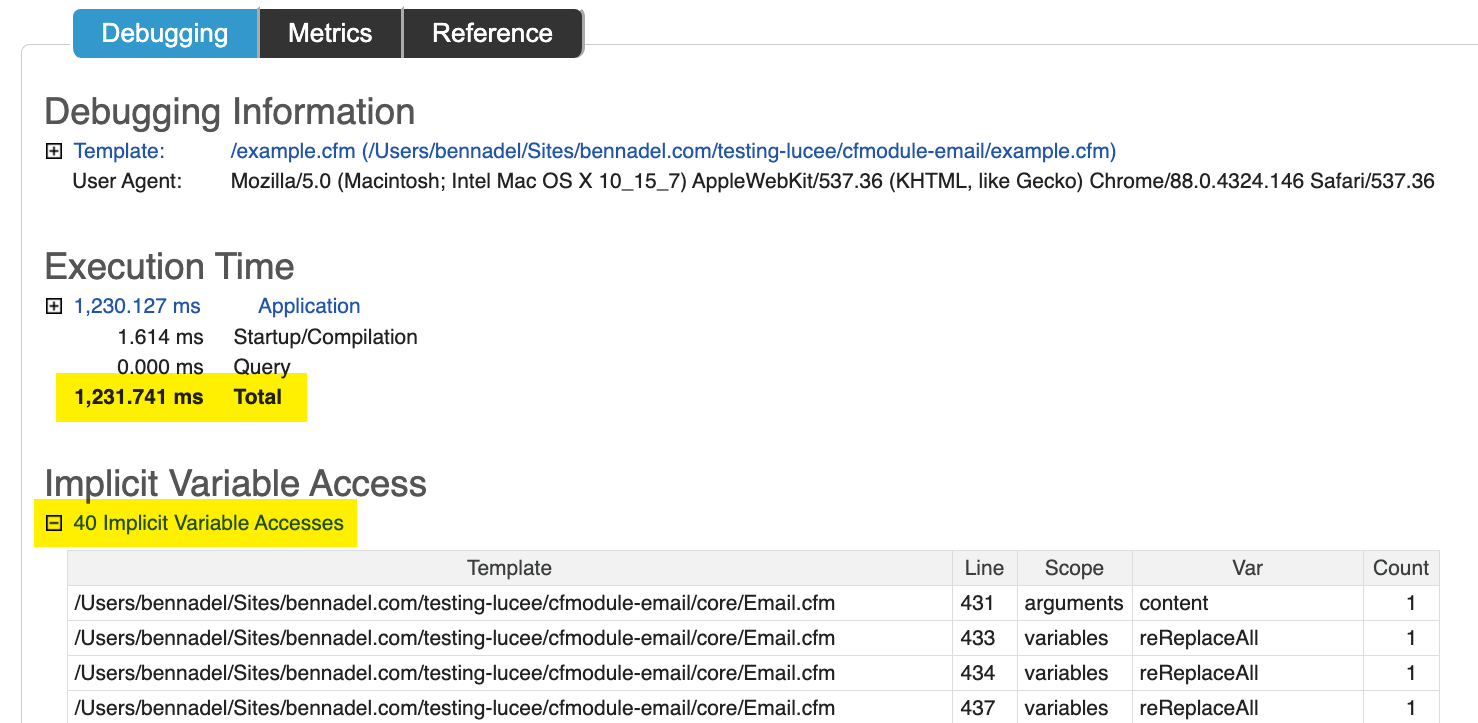
This CFML page was taking 1.2s just to render HTML. No database calls. No remote API calls. Just ColdFusion custom tags. And, as you can see, it had 40 implicit variable access points. And, some of those access points were being executed hundreds of times. All in all, the page request was walking scopes thousands of times looking for unscoped variables.
So, I went into the ColdFusion custom tags and I made sure to add the arguments prefix to all function argument references. I also refactored one .each() loop to be a for-in loop in order to eliminate one scope lookup in which ColdFusion was calling variables an implicit variable access.
And, when I did this - drum roll - the page processing time dropped from about 1.2s to 34ms:
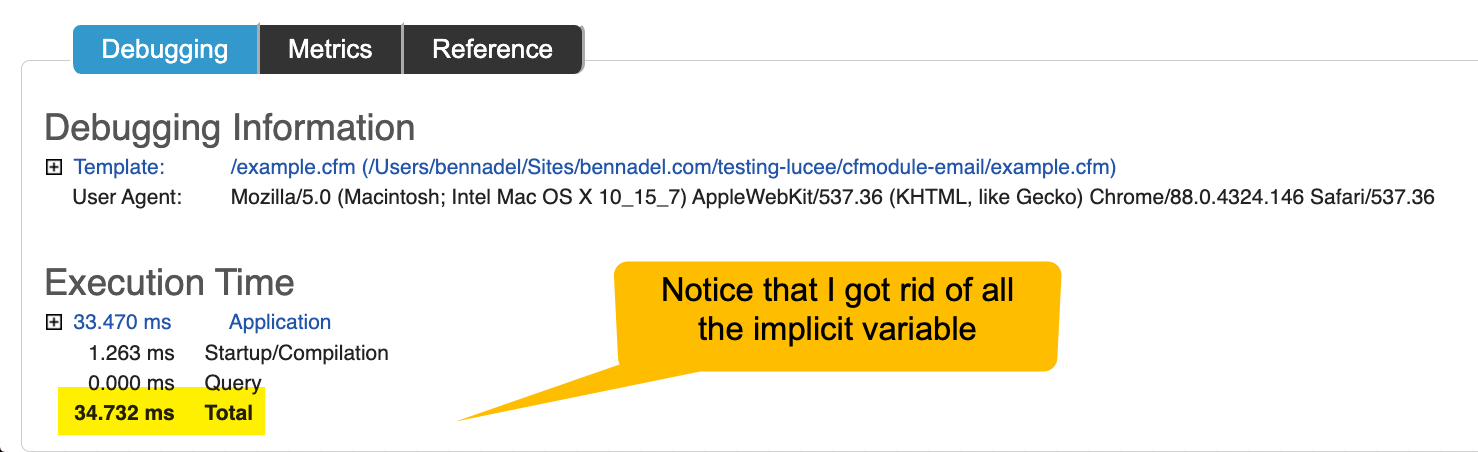
That's a 35x performance improvement. Just from adding arguments. to all my function arguments references. Not too shabby.
Make It Work. Make It Right. Make It Fast.
Looking at 35x performance improvement, one could easily conclude that you should always include the arguments. prefix. But, I would argue that doing so could just as easily be considered premature optimization. Adding arguments. is not a "pure victory" - doing so adds additional tokens to the code, making it more wordy and slightly harder to read as your brain now has more information that is has to parse.
Keep in mind that this request was making thousands of function calls. This is not normal. This is not how the vast majority of requests get processed. This is a special case.
Kent Beck - original signer of the Agile Manifesto and author of the Extreme Programming book series - is know to say:
Make it work. Make it right. Make it fast.
If you follow this order, and omit the arguments. prefix, you've already "made it fast" in the vast majority of cases. Then, if you measure something and find it to actually be slow, that is the great time to go in and make it fast using additional means and refactoring.
There's a good discussion of this concept on Episode 6 of the Weekly Dev Tips podcast with Steve Smith.
That said, I thought this was a wonderful case study of how a relatively small change, like removing implicit variable access, can have a rather substantial affect on your page request performance in Lucee CFML 5.3.7.47. It's definitely a good trick to have in your back pocket. Also, how bad-ass is it that the Lucee CFML debugging template includes implicit variable access in its output. I'll be honest - I haven't enabled debug-output in years. Seeing this was quite a pleasant surprise.

Reader Comments
It certainly pays off for hot functions!
Setting this in your Application.cfc also improves performance, see Settings, scope in the Lucee admin.
this.scopeCascading = "strict";
You need to compare with debugging disabled, as the logging of implicit access does tend to impact out performance a lot, hence the 35x :)
also, a quick plug for my Lucee Performance Analyzer admin plugin (available under extensions in the Lucee admin)
https://github.com/zspitzer/lucee-performance-analyzer
It provides you with aggregate views (queries, scopes) over all your current debug logs, rather than just viewing logs individually by request.
@Zac,
Good point re: overhead of the debugging itself. So, yeah, the perf gain is likely over-stated. But still, I think it works as some kind of indication of improvement.
I'll take a look at your plugin, groovy!
Funnily enough I have always preferred to list scopes explicitly. My personal preference has always been that when I read arguments.something I know I look at an argument.
Personally I have always found code easier to read with explicit scoping (and indeed it's something I sometimes miss in other languages).
@All,
When I moved development of the DSL out of CommandBox and into Docker for Mac (for my InVision hackathon project), I ran into another performance issue:
www.bennadel.com/blog/3994-coldfusion-custom-tag-performance-differences-between-cfmodule-and-cfimport-in-lucee-cfml-5-3-7-47.htm
Docker for Mac is notoriously bad for File-IO. And, as it turns out, when you invoke a ColdFusion custom tag using
<CFImport>, Lucee CFML performs a file-exists check on every invocation, not caching the results. As such, the DSL ends up performing a crap-ton of File IO, which is less-than-awesome in Docker.To mitigate this, I moved low-level usage to
<CFModule>, which doesn't look as pretty. But, I'm leaving the high-level, developer-facing stuff as<CFImport>with the hope that:Lucee CFML will eventually just "fix" this issue (I've filed a performance enhancement ticket).
Production performance, which runs on dedicated machines and Kubernetes (K8) will not suffer from the same file-IO performance that Docker for Mac does.
Regardless, there's lots of interesting insights coming to the surface as I try to apply this DSL to a real-world scenario.
I got sidetracked a few days ago when I read in the Lucee Dev Forum that IsDefined() was deprecated. Researching that led me to several of your articles, this one being the most recent. I posted a new topic that I'll hope you'll read and maybe comment on and/or like, and not just because I quoted you. 😉
It's relevant to your topic of scope traversal for implicit variable access. I pondered reasons for why IsDefined maybe should be undeprecated (is that a word? 🧐) and how most of its alternatives appear to be less performant. Taking the performance argument to the extreme just to make a silly/serious point, I also questioned whether Lucee should be deprecated and we all go back to Assembly Language. 😝
https://dev.lucee.org/t/why-was-isdefined-deprecated-and-less-performant-alternatives-not/10480
@Lionel,
Very cool -- taking a look 👍