
Using COUNT(), COUNT(column), And COUNT(expression) Variations To Extract Row Metadata In MySQL 5.7.32
Yesterday, I was working with fellow InVisioneer, Josh Siok, to transform some MySQL data-tables into a common format. As we did this, we were using the COUNT() aggregation function to gather metadata about the records that we were transforming. COUNT() - and the other aggregation functions - are surprisingly flexible. As such, I thought it would be fun to take a quick look at the COUNT() variations in MySQL 5.7.32.
In MySQL 5.x, there are four COUNT() variations (depending on how you look at it):
COUNT( * )- This counts all of the rows in the given result-set orGROUP BYcohort. This variation does not care about the contents of the individual rows, only that they exist.COUNT( column )- This counts the number of non-NULLvalues that appear in the given column within the given result-set orGROUP BYcohort.COUNT( DISTINCT column )- This counts the number of unique, non-NULLvalues that appear in the given column within the given result-set orGROUP BYcohort.COUNT( expression )- This evaluates the given expression for each row within the given result-set orGROUP BYcohort; and, counts the number of rows in which the expression evaluates to a non-NULLresult. This variation is super flexible and you can jam just about anything you want into the "expression".
To explore this, I'm going to create a derived table of "friends". Then, we're going to use all four variations on COUNT() to gather metadata about the "friends" table:
SELECT
-- The most common form of COUNT() uses the '*' to count all of rows in the given
-- result-set or GROUP BY cohort. This version does not incur any special logic
-- surrounding NULL values - it counts all rows regardless.
COUNT( * ) AS total_friend_count,
-- The COUNT( column ) will return the number of rows in which the given column
-- contains a non-NULL value in the given result-set or GROUP BY cohort.
COUNT( isBFF ) AS bff_count,
-- The COUNT( DISTINCT column ) is like the COUNT( column ) in that it will only
-- count rows that contain a non-NULL value for the given column. However, it will
-- only count any given value ONCE, returning the UNIQUE count in the given result-
-- set or GROUP BY cohort.
COUNT( DISTINCT name ) AS unique_name_count,
-- The COUNT( expression ) is the most flexible incarnation, allowing us to evaluate
-- any arbitrary expression on each row in the given result-set or GROUP BY cohort.
-- As with the versions above, only non-NULL expression evaluations will be included
-- in the COUNT(). As such, we can exclude rows by returning a NULL value.
COUNT( ( name = 'Anne' ) OR NULL ) AS anne_count
FROM
(
-- Setup the DERIVED-TABLE for the demo.
( SELECT 'Anne' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Anne' AS name, TRUE AS isBFF ) UNION ALL
( SELECT 'Biff' AS name, TRUE AS isBFF ) UNION ALL
( SELECT 'Elle' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Jeff' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Lara' AS name, TRUE AS isBFF ) UNION ALL
( SELECT 'Lara' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Nina' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Todd' AS name, NULL AS isBFF )
) AS friends
;
As you can see, we can use multiple COUNT() variations on the same result-set or GROUP BY cohort! Notice that the last variation - COUNT(expression) - is using OR NULL. This is important because MySQL will count any non-NULL value, which includes the "falsy" values 0, FALSE, and ''. And now, when we run this SQL in MySQL 5.7, we get the following results (Note that I've removed the SQL comments in order to fit everything into the screen-shot):
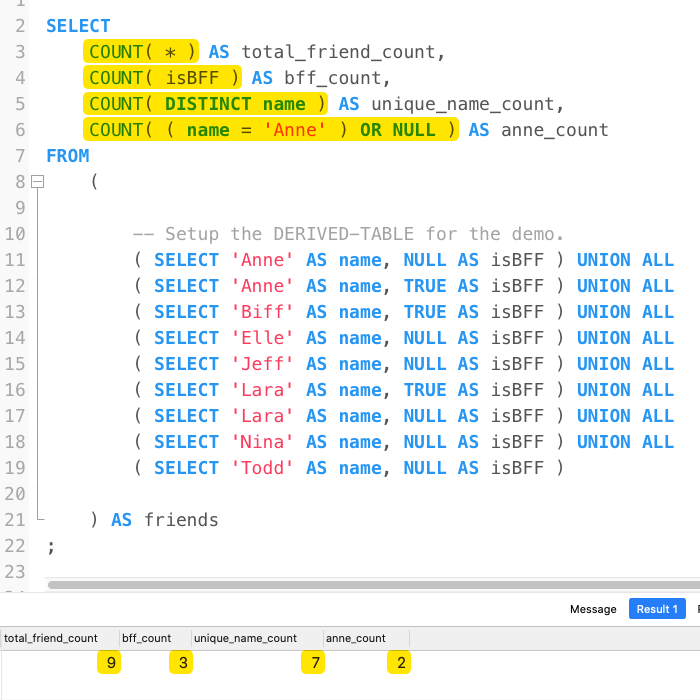
As you can see, we were able to extract different properties about the result-set by using all four different forms of COUNT().
The COUNT(expression) variation is super flexible. You can basically put anything you want into the "expression" as long as it evaluates to a NULL or a non-NULL value. You can even put sub-queries in their (if they weren't too expensive to run of course):
SELECT
-- Count all of the rows where the 'name' column exists in another table.
COUNT(
-- NOTE: This EXISTS() expression is going to be evaluated for EACH ROW in the
-- given result-set or GROUP BY cohort.
EXISTS (
SELECT
1
FROM
(
( SELECT 'Anne' AS name ) UNION ALL
( SELECT 'Lara' AS name )
) AS innerTable
WHERE
innerTable.name = friends.name
)
OR NULL
) AS demo_count
FROM
(
-- Setup the DERIVED-TABLE for the demo.
( SELECT 'Anne' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Anne' AS name, TRUE AS isBFF ) UNION ALL
( SELECT 'Biff' AS name, TRUE AS isBFF ) UNION ALL
( SELECT 'Elle' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Jeff' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Lara' AS name, TRUE AS isBFF ) UNION ALL
( SELECT 'Lara' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Nina' AS name, NULL AS isBFF ) UNION ALL
( SELECT 'Todd' AS name, NULL AS isBFF )
) AS friends
;
The COUNT() aggregation function is surprisingly flexible; and, it can be used in more ways than you might realize. It's good to have these variations in your back pocket for when you're performing data analysis, merging records, migrating tables, or creating derived tables in MySQL.
Epilogue on Other Aggregation Functions
In the above SQL demos, I'm using the COUNT() function; however, this same technique should work for most of the MySQL aggregate functions. As a quick demonstration, I'm going to use a few MIN(), MAX(), AVG(), and SUM() variations:
SELECT
MIN( value ) AS min_value,
MAX( value ) AS max_value,
AVG( value ) AS avg_value,
AVG( DISTINCT value ) AS distinct_avg_value,
SUM( value ) AS sum_value,
SUM( DISTINCT value ) AS distinct_sum_value,
SUM( IF( value IN ( 1, 2 ), value, NULL ) ) AS sum_expression
FROM
(
-- Setup the DERIVED-TABLE for the demo.
( SELECT 1 AS value ) UNION ALL
( SELECT NULL AS value ) UNION ALL
( SELECT 2 AS value ) UNION ALL
( SELECT 3 AS value ) UNION ALL
( SELECT 3 AS value ) UNION ALL
( SELECT 3 AS value ) UNION ALL
( SELECT NULL AS value ) UNION ALL
( SELECT 3 AS value ) UNION ALL
( SELECT 3 AS value )
) AS numbers
;
One minor difference between COUNT() and the other variations is that COUNT() will always return a number. However, aggregate functions like MIN() and MAX() may return NULL if there is no matching data to use in their relevant aggregation.
Want to use code from this post? Check out the license.

Reader Comments
Yesterday, I just used a
CASE/ENDstatement inside aCOUNT()block. Just another way to leverage the ability to evaluate statements inside the aggregate functions. I had a SQL statement that had severalLEFT OUTER JOINclauses; and, I had to find some counts based on a combination of values. It was something like this:You don't need to know what these columns mean, only that they were used in the
CASEfor the win!! 🙌