
Temporary Upload Files Are Duplicated And Persisted When A Request Uses CFThread In Lucee CFML 5.3.6.61
Earlier this week, Pablo Fredrikson from our Platform team was paged because one of the Kubernetes pods that runs one of our Lucee CFML containers was running out of disk space. Upon further investigation, he found that the server's temporary file directory was using over 160 Gigabytes of storage. To perform an immediate remediation, my team triggered a deployment for that ColdFusion service, which wiped all of the old data. But, once the "incident" was closed, I started trying to figure out why so much data was being stored. And, what I discovered is that the temporary files produced during a multipart/form-data POST are duplicated and persisted if the parent ColdFusion request uses CFThread to manage asynchronous processing.
Normally, when you upload a file to a ColdFusion server during a multipart/form-data POST, ColdFusion automatically deletes the temporary .upload file after the request completes. However, it turns out that if the parent ColdFusion request uses the CFThread tag, the server stops deleting the temporary file associated with the POST. And, in fact, the server creates a duplicate of the temporary file for every CFThread tag that is spawned.
This is not the first time that I've seen CFThread cause some unexpected behavior. As I discussed at a few months ago, Lucee CFML appears to incur some request-cloning overhead when spawning threads - a side-effect that I noticed when debugging performance problems with FusionReactor. I'm assuming that this temporary upload file duplication is related to that same behavior.
To isolate this behavior in a clear way, I created two ColdFusion files: one that outputs the contents of the temporary directory; and, one that accepts a file-upload. First, let's look at the temporary directory code:
<cfscript>
param name="url.clear" type="boolean" default="false";
if ( url.clear ) {
for ( record in directoryList( getTempDirectory() ) ) {
fileDelete( record );
}
location( url = "./list.cfm", addToken = false );
}
tempFiles = directoryList(
path = getTempDirectory(),
listInfo = "query",
filter = "*.upload"
);
tempFiles.sort( "dateLastModified", "desc" );
</cfscript>
<h1>
Lucee CFML Temp Files
</h1>
<cfdump var="#tempFiles#" />
<p>
<a href="./list.cfm">Refresh</a> ,
<a href="./list.cfm?clear=true">Clear Temp Directory</a>
</p>
As you can see, all this does it dump-out the contents of the getTempDirectory() directory; and, if prompted, clear the contents.
The other ColdFusion page creates a file-upload, but doesn't do anything with it; and, if prompted, will spawn several no-operation (noop) CFThreads:
<cfscript>
param name="form.data" type="string" default="";
param name="form.doSpawnThread" type="boolean" default="false";
if ( form.data.len() && form.doSpawnThread ) {
// Spawn a number of threads so that we can see how the thread-count affects the
// way that temporary upload files are handled.
for ( i = 1 ; i <= 10 ; i++ ) {
thread
name = "noopThread-#i#"
index = i
{
// No-op thread....
}
}
}
</cfscript>
<!doctype html>
<html lang="en">
<body>
<h1>
Upload A File To Lucee CFML
</h1>
<cfif form.data.len()>
<p>
<strong>Temp File:</strong> <cfoutput>#form.data#</cfoutput>
</p>
</cfif>
<form method="post" enctype="multipart/form-data">
<p>
<input type="file" name="data" />
<input type="submit" value="Upload" />
</p>
<p>
<input type="checkbox" name="doSpawnThread" value="true" />
Spawn <code>CFThread</code>
</p>
</form>
</body>
</html>
As you can see, there's basically nothing going on here.
So, let's start with a base test: using the multipart/form-data POST to upload a file, but without triggering any CFThread:
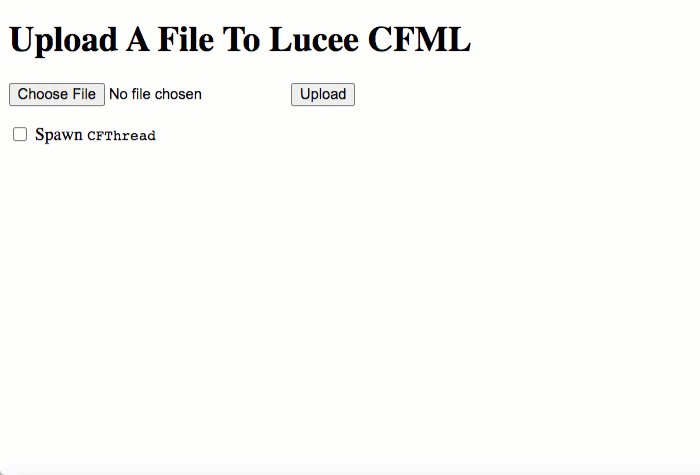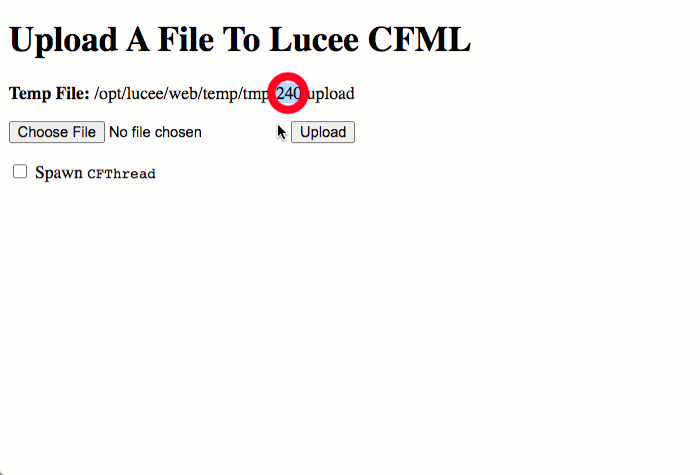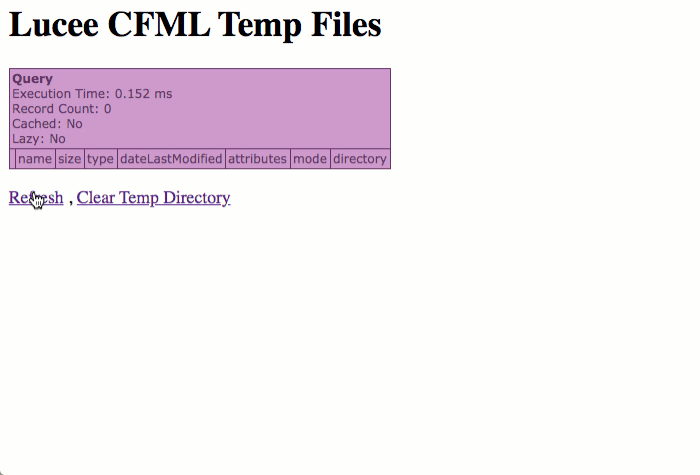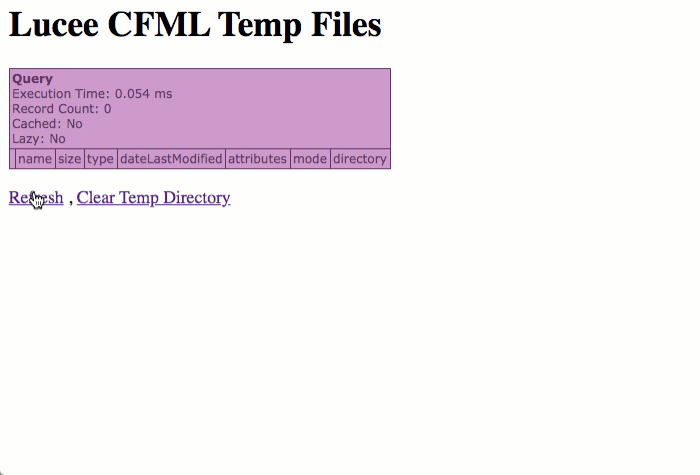
As you can see, when we upload the file using the multipart/form-data POST, Lucee CFML creates a temporary .upload file. Then, once the request is over, that temporary file is cleared-out automatically and our getTempDirectory() listing is left empty.
Now, we're going to perform the same workflow; only, this time, we're going to spawn 10 CFThread tags as well. Those CFThread tags don't do anything - it's their very existence that causes the change in behavior:
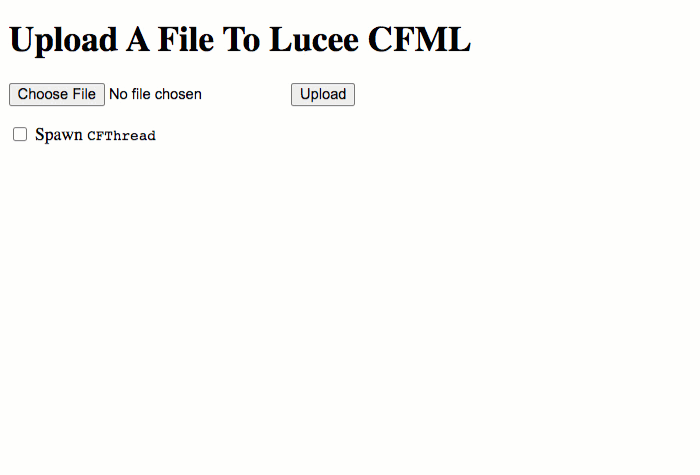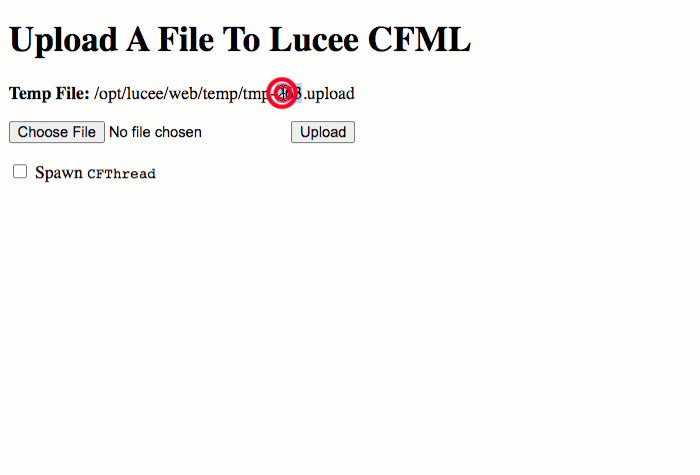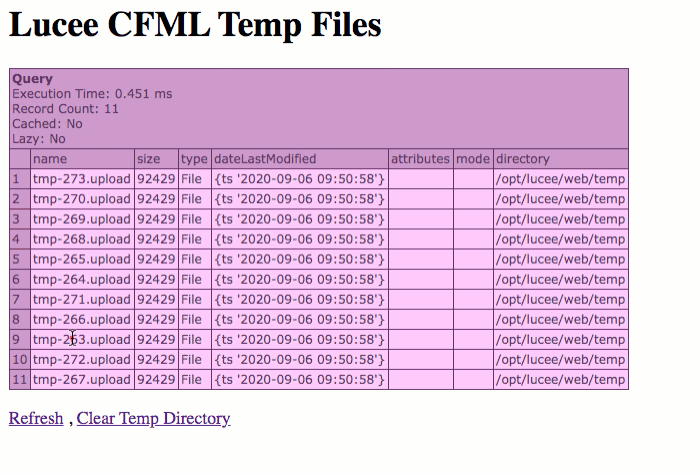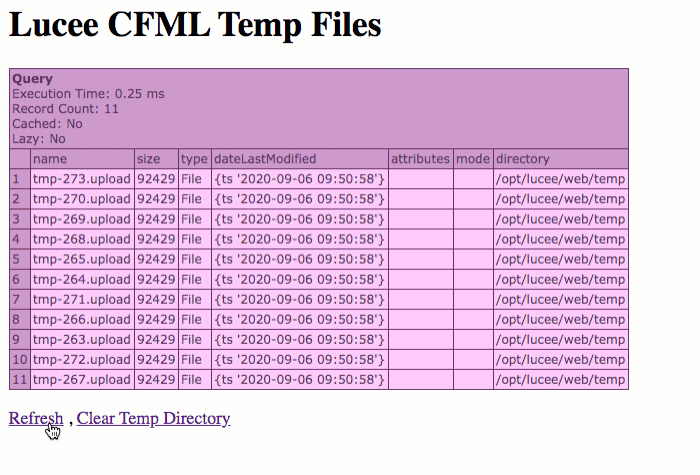
As you can see, when the parent request of a multipart/form-data POST spawns a CFThread tag, we get some very interesting behaviors:
The temporary
.uploadfile generated during the upload is no longer removed automatically after the parent request finishes processing.A new temporary
.uploadfile is generated for eachCFThreadtag that is spawned from the parent request. In this case, we spawned 10CFThreadtags, so we end up with 11.uploadfiles in thegetTempDirectory().The per-
CFThread.uploadfiles are all uniquely named; and, we don't have any idea what they are at runtime. I don't show it in the demo GIF, but all of theform.datareferences in theCFThreadtag bodies show the parent's version of the.uploadfile.
This clearly explains why some of our Lucee CFML pods were using over 160 Gigabytes of data! Consider that some of the requests that deal with file-uploads are also spawning asynchronous CFThread tags to do the following:
- Generating thumbnails.
- Generating version-history of assets.
- Logging analytics data.
... it's no wonder that duplicated bytes are adding up fast!
So, what to do about this? Well, since each duplicated .upload file is given a unique name that neither the parent request nor the CFThread tags have access to, I think the safest approach will be to periodically purge the getTempDirectory() directory of any files that are older than X-minutes, where X is some reasonable threshold. Maybe 5-minutes?
Here's what that could look like (though, I have not tested this code) - it gathers all .upload files older than 5-minutes and then deletes them:
<cfscript>
purgeOldTempFiles();
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I delete ".upload" files from the getTempDirectory() that are older than the given
* age in minutes.
*
* @tempDirectory I am the web server's temporary directory.
* @ageInMinutes I am the age at which to consider a .upload file purgeable.
*/
private void function purgeOldTempFiles(
string tempDirectory = getTempDirectory(),
numeric ageInMinutes = 5
) {
var tempFiles = directoryList(
path = tempDirectory,
listInfo = "query",
filter = "*.upload"
);
var cutoffAt = now().add( "n", -ageInMinutes );
// Filter the temp-directory files down to those that were modified before the
// cutoff date. These are the files that are considered safe to delete.
var oldTempFiles = tempFiles.filter(
( tempFile ) => {
return( tempFile.dateLastModified < cutoffAt );
}
);
for ( var tempFile in oldTempFiles ) {
var tempFilePath = ( tempFile.directory & "/" & tempFile.name )
// Since files can be locked by a process, we don't want one "poison pill" to
// break this process. Each file operation should be wrapped in a try-catch
// so that if it fails, we can continue trying to delete other, old files.
try {
systemOutput( "Deleting temp file: #tempFilePath#", true, true );
fileDelete( tempFilePath );
} catch ( any error ) {
systemOutput( error, true, true );
}
}
}
</cfscript>
This could be triggered as part of a scheduled-task; or, in our case, as part of the Kubernetes (K8) health-check that runs every 10-seconds in every container in our distributed system.
Again, I assume that this behavior is related to the "request cloning" that seems to take place in Lucee CFML when a CFThread tag is spawned. I assume that part of that request cloning is the cloning any FORM data, complete with temporary files. So, hopefully my idea to purge old .upload files is a sufficient way to combat the storage growth.
Want to use code from this post? Check out the license.

Reader Comments
@All,
I filed this as a potential bug: https://luceeserver.atlassian.net/browse/LDEV-3041 , at least the file-duplication part of it.
Odd, there's actually an hourly task which checks the temp folder and purges if it gets to big? You see it's output if you set the log level for application.log to info
Already filed, though cfthread may handle this differently: https://luceeserver.atlassian.net/browse/LDEV-2903
@Daemach,
Ahhh, nice catch. I tried Googling for this issue, but I was searching specifically for
CFThread, so the parallel iteration didn't come up. Though, I also think that JIRA doesn't get much "Google love" cause JIRA tickets almost never come up for me when I am searching for anything (ColdFusion related or not).@Zachary,
Oh interesting. I do see that kind of stuff in the logs a lot (at least locally). I had no idea what it was doing or what it was for. If I look in my local dev environment, I see one for
tempand one corcache:Looks like the temp folder can get to be 1Gb in size (if my Google-fu is right on that byte-count). Maybe something is going wrong in production. Let me search the production logs.
I think from memory it's a proportion of available freespace.
Actually it's hardwired. So that's a bug / regression
I'd like these all to be configurable
https://luceeserver.atlassian.net/browse/LDEV-2418
@Zach,
So, I am seeing those logs in production (Loggly). And, going back to just before the incident when we had to trigger a deploy, here's some samples:
Adding some commas:
Yeah, they are definitely ballooning out of control!
I'm also seeing some errors logs like:
And, looking at the Lucee source code, it looks like it may bail-out of the delete-loop if it encounters an error:
https://github.com/lucee/Lucee/blob/6d14fc715cfc0629d101a099a8f0980ea7a5814e/core/src/main/java/lucee/runtime/engine/Controler.java#L517
... so, maybe something got messed up by just a few poison pills and the temp folders couldn't be emptied.
That said, it looks like this happened really suddenly. Also, none of those numbers above comes close to the 160-Gigabytes that our Platform people reported (though, we do have multiple containers running on a single Kubernetes pod).
Definitely something very curious.
How many files were in the 160Gb?
https://github.com/lucee/Lucee/blob/5.3/core/src/main/java/lucee/runtime/engine/Controler.java#L500
@Zach,
So, I tried to narrow the logs down to a single Lucee container using the following query:
( "check size of directory" OR "cannot remove resource" ) AND "cfprojectsapi-deployment-d48b6fc76-gj79r"This gives me logs that interleave the "checking" and the "cannot remove" - you can see that the size of the directory just keeps going up steadily. So, maybe Lucee doesn't have permissions to delete the files?
@Zach,
Unfortunately, we didn't gather any more statistics prior to our deployment to clear all the containers :( I suspect it would have been many small files; but, I am not entirely sure. I may start collecting some information about this in our operation's health probes to see if I can get any more insight.
When u file a bug, can you ask for the cannot remove resource error to include the actual exception?
No, something even more odd is happening. If I look at a single pod's logs for a 24-hours period, I see 27 log entries:
check size of directorycannot remove resourceAnd, over that 24-hours period, that temp file storage on that pod has gone from 40Gb to 41Gb. Now, if it were simply a permissions issue, I'd expect to see a
cannot remove resourceerror following every singlecheck size of directory... but that's not the case.Maybe this is a Kubernetes issue - like maybe Kubernetes won't release disk space?
OK. I had a similar problem, but it turned out that I hadn't given the application server permission to delete files in a particular directory. This was on my new VPS, which is Windows 2012R2. On my previous VPS, which was Windows 2008R2, I didn't need to mess with any permissions?
The next thing, is why do you need to divert this process into a thread? Why can't users upload their files without using CFTHREAD? That would solve your problem without having to resort to a schedule task, until the Lucee engineers fix this bug.
@Charles,
Yeah, I need to learn more about why the files cannot be deleted. I am not sure if it is all files; or just a few of them, which are errorring-out and short-circuiting the clean-up script? Unfortunately, I don't have good insight into the why yet. That said, since the ColdFusion process has permission to write files to the
getTempDirectory(), I would assume it has permissions to delete. But, to be honest, I don't really understand how permissions work in a multi-user environment - that's always been a bit outside my mental model.Re: threading, we don't actually need to the
CFThreadto handle the file upload, we do other things in theCFThread. For example, we might post an analytics event to SegmentIO. And, we don't want that HTTP call to potentially hang the overall request, so we'll do that in an asynchronous thread. And, the very existence of thatCFThreadcauses the temp files to be duplicated and persisted.So, it could be a thread that is entirely unrelated to the top-level request. In fact, the file-handling part of the request may not even know that any threading is being used.
@All,
Ok, so I think I have some more evidence of what is going on. Yesterday, I took one of the "could not remove file" errors and shared with our Platform engineers (Pablo). He then remoted into that pod and checked to see if said file was being locked by a process. However, by the time he got there, the file was gone.
So, here's what I think is happening:
The background task in Lucee that cleans-up the old files has two characteristics:
It doesn't attempt to delete the files in any particular order.
It completely bails-out of the clean-up routine when it encounters an error.
It only tries the clean-up task at most once per hour.
So, based on that, I think it is "working", so to speak. But, I think what's happening is that as it starts cleaning up old files, it hits one that is still in use, probably because it isn't doing it by time-stamp or anything of that nature. Then, when it hits that error, it bails-out of the process. And, it won't try again for an hour.
I believe that our servers are generating files faster than the clean-up task can try to delete them.
Of course that still doesn't explain why we're not seeing "couldn't remove file" errors every hour. That still doesn't make sense. But, I'm still trying to dig into this.
I know this sounds a bit obvious and it maybe against your work ethos, but you could try using:
Put it inside the clean up loop, so that if it encounters an error in one file, it will just continue to the next.
I would also add:
Around any file operation. You are probably already doing this?
Then, you will only have to clear up a few manually, each time. Obviously, the files that remain are the ones that were locked.
And by the way, I found out that I had to explicitly add delete permissions on files on my new Windows 2012R2 Server. On my previous Windows 2008R2 Server, I didn't need to do this.
Allowing write permissions is not enough.
@Charles,
Since I was / am still investigating, I was hesitant to put in a
try/catchfor each file since I sort of wanted it to blow-up and then log the error. This way, I wouldn't start dumping thousands of errors in my logs (one per file) if something went catastrophically wrong) :D That said, I've deployed my version and it's been keeping the temp-files at bay at around 2-3 thousand files at any one time. So, I think we're in the clear.I'll share my code tomorrow, and add some notes to my ticket.
@All,
I've written a follow-up post with the details about how I've dealt with this problem:
www.bennadel.com/blog/3891-deleting-temporary-upload-files-in-our-k8-operational-readiness-probe-in-lucee-cfml-5-3-6-61.htm
Essentially, we are hooking into our Kubernetes (K8) readiness probe to delete the files in the
getTempDirectory().