
Printing Emoji Characters From Unicode CodePoints In Lucee CFML 5.3.5.92
Now that I've enabled Emoji characters in my blog comments (via MySQL's utf8mb4 character encoding), it's got me thinking more about how else I might use Emoji in my blog. That said, since my brain hasn't fully accepted Emoji as "normal" content; so, I'm still not ready to embed Emoji characters directly within my ColdFusion code files (old habits die hard). This got me thinking about how I might be able to output Emoji characters based on their Unicode CodePoints. Unfortunately, it's not as simple as calling the built-in chr() function, since this only supports CodePoints up to 65,535 (0xffff). As such, in order to print Emoji characters in ColdFusion, I have to drop down into the Java layer in Lucee CFML 5.3.5.92.
To be clear, I know very little about character-encoding! So, please forgive me if I get anything blatantly wrong here. But, from what I understand, the Unicode standard has evolved over time from a fixed-width, two-byte implementation to a dynamic-width, multi-byte implementation that now allows CodePoints in the range of U+0000 to U+10FFFF. And, because I will almost certainly mangle any deeper explanation, here's a snippet from Java's Character class:
The char data type (and therefore the value that a Character object encapsulates) are based on the original Unicode specification, which defined characters as fixed-width 16-bit entities. The Unicode Standard has since been changed to allow for characters whose representation requires more than 16 bits. The range of legal code points is now
U+0000toU+10FFFF, known as Unicode scalar value. (Refer to the definition of theU+nnotation in the Unicode Standard.)The set of characters from
U+0000toU+FFFFis sometimes referred to as the Basic Multilingual Plane (BMP). Characters whose code points are greater than U+FFFF are called supplementary characters. The Java platform uses the UTF-16 representation in char arrays and in the String and StringBuffer classes. In this representation, supplementary characters are represented as a pair of char values, the first from the high-surrogates range, (\uD800-\uDBFF), the second from the low-surrogates range (\uDC00-\uDFFF).
Now, ColdFusion has two built-in functions for dealing with characters and their CodePoint representations: chr() and asc(). However, as I stated above, this only works for characters in the Basic Multilingual Plane (BMP). To work with Emoji, we start to involve Unicode characters that require more than two-bytes; which means, depending on how you squint, a single Emoji is actually represented by a two-character sequence (a surrogate pair).
In order to generate this surrogate pair from a Unicode CodePoint, I'm going to use the static .toChars() method on the java.lang.Character class. This method will return the Array of characters (the surrogate pair) needed to represent the given CodePoint; which we can then join-together in order to print the Emoji.
The basic idea in ColdFusion is as follows:
<cfscript>
// Get the multi-character representation of the Emoji CodePoint.
// --
// NOTE: 128512 is the CodePoint for "grinning face".
chars = createObject( "java", "java.lang.Character" )
.toChars( javaCast( "int", 128512 ) )
;
// Collapse the resultant character Array into a single String.
echo( arrayToList( chars, "" ) );
</cfscript>
To see this in action, I've grabbed a bunch of the Emoji CodePoints from Unicode.org. I'm then using some User-Defined Functions (UDF) in Lucee CFML to render these Emoji to the page output:
<!--- Reset the output buffer and denote UTF8 content. --->
<cfcontent type="text/html; charset=utf-8" />
<!--- Pulling in some CSS for the demo. --->
<link rel="stylesheet" type="text/css" href="./styles.css" />
<cfscript>
// As a "control case", let's make sure these methods don't break for the normal
// ASCII decimal values. Trying A - E. Meaning, this should output the same value as
// the chr() method that we are used to using.
for ( i = 65 ; i <= 69 ; i++ ) {
echo( chr( i ) );
echo( ":" );
echo( chrFromCodePoint( i ) );
echo( " " );
}
// A sample of Emoji Unicode values taken from:
// --
// https://unicode.org/emoji/charts/full-emoji-list.html
unicodeValues = [
// face-smiling.
"U+1F600", "U+1F603", "U+1F604", "U+1F601", "U+1F606", "U+1F605", "U+1F923",
"U+1F602", "U+1F642", "U+1F643", "U+1F609", "U+1F60A", "U+1F607",
// face-affection.
"U+1F60D", "U+1F929", "U+1F618", "U+1F617", "U+263A", "U+1F61A", "U+1F619",
// face-tongue.
"U+1F60B", "U+1F61B", "U+1F61C", "U+1F92A", "U+1F61D", "U+1F911",
// face-hand.
"U+1F917", "U+1F92D", "U+1F92B", "U+1F914",
// face-glasses.
"U+1F60E", "U+1F913", "U+1F9D0",
// face-concerned.
"U+1F615", "U+1F61F", "U+1F641", "U+2639", "U+1F62E", "U+1F62F", "U+1F632",
"U+1F633", "U+1F626", "U+1F627", "U+1F628", "U+1F630", "U+1F625", "U+1F622",
"U+1F62D", "U+1F631", "U+1F616", "U+1F623", "U+1F61E",
// monkey-face.
"U+1F648", "U+1F649", "U+1F64A",
// hand-fingers-open.
"U+1F44B", "U+1F91A", "U+1F590", "U+270B", "U+1F596",
// hand-fingers-partial.
"U+1F44C", "U+270C", "U+1F91E", "U+1F91F", "U+1F918", "U+1F919",
// hand-fingers-closed.
"U+1F44D", "U+1F44E"
];
```
<cfoutput>
<ul class="chars">
<cfloop index="unicodeValue" array="#unicodeValues#">
<li class="char">
#unicodeValue# :
<span class="emoji">
#chrFromUnicode( unicodeValue )#
</span>
</li>
</cfloop>
</ul>
</cfoutput>
```
// ------------------------------------------------------------------------------- //
// ------------------------------------------------------------------------------- //
/**
* I return the String corresponding to the given codePoint. If the codePoint is
* outside the Basic Multilingual Plane (BMP) range (ie, above 65535), then the
* resultant string may contain multiple "characters".
*
* @codePoint I am the Unicode codePoint for which we are generating a String.
*/
public string function chrFromCodePoint( required numeric codePoint ) {
// The in-built chr() function can handle code-point values up to 65535 (these
// are characters in the fixed-width 16-bit range, sometimes referred to as the
// Basic Multilingual Plane (BMP) range). After 65535, we are dealing with
// supplementary characters that require more than 16-bits. For that, we have to
// drop down into the Java layer.
if ( codePoint <= 65535 ) {
return( chr( codePoint ) );
}
// Since we are outside the Basic Multilingual Plane (BMP) range, the resulting
// Array should contain the surrogate pair (ie, multiple characters) required to
// represent the supplementary Unicode value.
var chars = createObject( "java", "java.lang.Character" )
.toChars( javaCast( "int", codePoint ) )
;
return( arrayToList( chars, "" ) );
}
/**
* I return the String corresponding to the given hexadecimal value. If the hex value
* is outside the 0xFFFF range - the Basic Multilingual Plane (BMP) range - then the
* resultant string may contain multiple "characters".
*
* NOTE: Leading "0x" and "x" characters are ignored.
*
* @hexValue I am the hexadecimal value for which we are generating a String.
*/
public string function chrFromHex( required string hexValue ) {
// Strip off any leading 0x | x notation.
if (
( hexValue[ 1 ] == "0" ) ||
( hexValue[ 1 ] == "x" )
) {
hexValue = hexValue.reReplace( "^0?x", "" );
}
return( chrFromCodePoint( inputBaseN( hexValue, 16 ) ) );
}
/**
* I return the String corresponding to the given Unicode notation value (U+n). If the
* Unicode value is outside the U+FFFF range - the Basic Multilingual Plane (BMP)
* range - then the resultant string may contain multiple "characters".
*
* @unicodeValue I am the Unicode value for which are generating a String.
*/
public string function chrFromUnicode( required string unicodeValue ) {
return( chrFromHex( unicodeValue.reReplaceNoCase( "^U\+", "" ) ) );
}
</cfscript>
To make the demo a bit more interesting, I'm not using the decimal value of the CodePoint directly. Instead, I'm using the Unicode notation (U+n); and then, funneling that through a series of ColdFusion functions that convert it from Unicode notation to Hex notation to Decimal value (which ultimately uses the java.lang.Character class).
And, when we run the above ColdFusion code, we get the following page output:
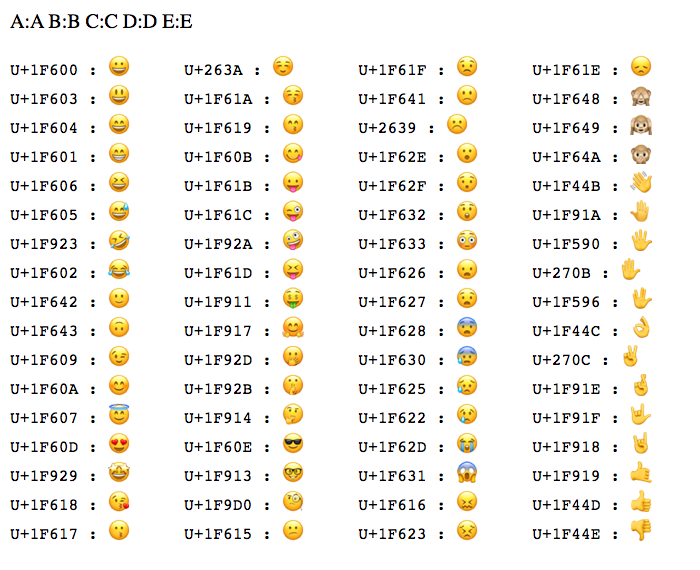
As you can see, we were able to output the Emoji characters based on their Unicode notation / Unicode CodePoints!
Emoji characters are "valid characters". Meaning, if you wanted to, you could embed them directly within a ColdFusion code file in order to consume or manipulate them just as you would any other String value. But, for strictly emotional reasons, I'm not ready to start putting raw Emoji characters in my ColdFusion code. Therefore, it's good to know that I can always render an Emoji character based on its Unicode Notation or Unicode CodePoint in Lucee CFML 5.3.5.92.
Epilogue On Unicode Characters And HTML Entities
It should be noted that you can also use HTML Entities to render Emoji from a given hexadecimal value or Unicode CodePoint:
😆- Where128518is the Unicode CodePoint.🤣- Where1f923is the Hexadecimal representation.
Of course, these only make sense in an HTML webpage context. So, while they are super useful, they can't be leveraged in all rendering contexts.
Want to use code from this post? Check out the license.

Reader Comments
@All,
In the epilogue of this post, I mentioned that we can use HTML entities to print emoji characters. I wanted to actually demonstrate that on its own:
www.bennadel.com/blog/4085-printing-emoji-characters-from-unicode-codepoints-using-html-entities-in-lucee-cfml-5-3-7-47.htm
This is going to make it easy for me to add emoji shortcuts to my blog!
I found an alternative way to do this—we can use the
canonicalize()function to normalize HTML entities into native emoji characters:www.bennadel.com/blog/4708-using-canonicalize-to-render-emoji-in-coldfusion.htm