
Loggly Derived Field RegEx Matching May Require A Newline In The Pattern
At InVision App, we currently use Loggly as our centralized log aggregation, analysis, and monitoring tool. Much of the log data that we send to Loggly is structured as JSON (JavaScript Object Notation); but, much of it is unstructured, space-delimited data (ex, nginx logs). One of the nice features of Loggly is that you can take this unstructured data and apply parsing rules - in Loggly - in order to derive searchable fields from the raw input. There are several ways to parse the unstructured data; but of course, I gravitate to anything powered by Regular Expressions (RegEx). One thing that tripped me up, however, is that our log data ended with an invisible new-line (\n) character that needed to be included in the RegEx pattern before Loggly would match it against any of the incoming log entries.
CAUTION: The new-line (\n) character may be a byproduct of the way we are logging data - writing it to the standard-out stream where it is being slurped up by fluentd. As such, this post may not be relevant for your approach to log aggregation.
When you choose the RegEx option for creating derived fields in Loggly, you have to match the target field's entire content. Meaning, your RegExp patten has to start with "^" and end with "$", which are the Regular Expression anchors that match the start-of-string and end-of-string, respectively:
REGEX: ^ ... $
Since Regular Expressions are complicated, unreadable beasts, I wanted to start simple and gradually get more complex. As such, I started by trying to match the entire line as one large glob:
REGEX: ^(.+)$
This is a valid pattern; but, Loggly kept telling me that it couldn't match it against any fields. In hindsight, this is because the "." character doesn't match new-lines by default in most Regular Expression engines; but, at the time, it didn't occur to me that the new-line was present. All I could tell was that if I made the pattern less restrictive, Loggly could finally match it:
REGEX: ^([\w\W]+)$
Here, since I'm using a "\w" (word) and "\W" (non-word) character-set, I'm essentially saying "match anything". And, with this pattern, Loggly was able to match the field content. From this, I was ultimately able to deduce that some sort of invisible white-space was present at the end of the line.
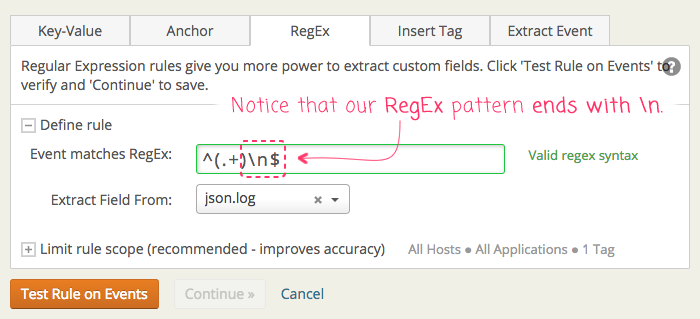
In retrospect, this should have been a fast discovery; but, I kid-you-not, this new-line had me stumped for several hours. I just didn't expect it to be there; so, I never considered patterns that would match it. But finally, after having an "ah-ha" moment, I added a new-line match to the end of the pattern:
| |
|
|
||
| |
 |
|
||
| |
|
|
And with this, Loggly was able to match the target field! At this point, I was able to take the "(.+)" portion of the Regular Expression pattern and begin breaking it down into more comprehensive capturing groups. While not necessarily relevant to this post, this is the pattern that I ended-up using to parse our nginx proxy logs:
^([a-z0-9-]+\.invisionapp\.com) [\d.:]+ - - \S+ \S+ "(GET|PUT|POST|PATCH|DELETE|OPTIONS) \S+ HTTP/1.1" (\d+) (\d+) "[^"]+" "[^"]+"\n$
Notice the "\n" at the end. This leaves me with the captured fields:
- Field 1: Domain
- Field 2: Method
- Field 3: HTTP Status Code
- Field 4: Bytes Returned
Of course, your nginx logs are likely to be different based on your configuration and setp; so, take this pattern with a grain of salt.
As an aside, one thing that was not obvious to me when I started looking into Regular Expression powered derived fields was that you could capture more than one field per log-entry. The documentation reads as if the pattern matching will stop running after the first capture. But, as you can see above, each captured group becomes its own derived field. Which is awesome.
Anyway, the new-line character represents a few hours of my life that I will never get back. So, hopefully this can help someone else who runs into the same Loggly problem and attempts to Google for an answer. Of course, depending on your platform, you may have a line-return (\r); or, both line-delimiters (\r\n). The point here is not necessarily to look for "\n" but, rather, to look for invisible, trailing white-space in your derived fields.

Reader Comments