
You Can Include Delimiters In The Result Of JavaScript's String .split() Method When Using Capturing Groups
For years, I've used JavaScript's String.prototype.split() method to break a string value up into delimited tokens. This is great for parsing input values like query-strings or user names. But, after years of using this method, I only just discovered that the .split() method was capable of returning the actual delimiters in the result-set. If your .split() Regular Expression pattern uses a capturing group (or set of capturing groups), the resultant array will contain both the split tokens and the delimiters. This is an intriguing feature that I thought was worth a quick exploration.
To test this out, I wanted to try parsing something that looked like a query-string. A query-string is interesting because it contains two types of delimiters: the "&" as the field delimiter; and, the "=" as the key-value delimiter. In the following code, we're going to split the query-string on the following pattern:
/([&=])/g
In this Regular Expression pattern, we're defining a character set that contains both of our delimiters: the "&" and the "=". But, more importantly, we're wrapping this character set in parenthesis. These parenthesis represent a "capturing group" which means that our .split() method invocation will return the given delimiter in the results.
// Require the core not modules.
var chalk = require( "chalk" );
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// Let's use a string that contains two sets of delimiters: "=" and "&".
var input = "hello=world&submitted=true";
// Create the Regular Expression pattern oh which we're going to split the input.
// --
// NOTE: When we use a capturing group (ie, the parenthesis) in the RegEx pattern, the
// .split() method will return the matched delimiter as part of the returned tokens.
// --
// CAUTION: Using MULTIPLE capturing groups will returns multiple delimiters for each
// match. This may or may not be what you are expecting.
var delimiterPattern = /([&=])/g;
console.log( chalk.bold( "Input:" ), input );
console.log( chalk.bold( "Split:" ), delimiterPattern.source );
console.log( chalk.dim( "--------------------------" ) );
// Loop over the segments, including the delimiters.
for ( var token of input.split( delimiterPattern ) ) {
var outputs = [
chalk.dim( ">" ),
chalk.cyan.bold( token ),
chalk.dim( "-->" )
];
// Since our capturing group will cause all matched delimiters to be returned as
// part of the split() tokens, we can test to see which token is a delimiter and
// which is a segment.
if ( delimiterPattern.test( token ) ) {
outputs.push( chalk.red( "delimiter" ) );
} else {
outputs.push( chalk.green( "token" ) );
}
console.log( ...outputs );
}
Here, we're splitting the string and then looping over the tokens. Since we know that the .split() method will include the delimiters in the results (thanks to the capturing group), we can test to see if any given token matches our split RegEx pattern. And, when we run the above code through node.js, we get the following terminal output:

As you can see, the resultant array contains both the input tokens and the "&" and "=" delimiters. And, as we loop over the result, we can easily separate the delimiters from the inputs using the same Regular Expression pattern.
There's something about this that's fascinating. Perhaps it's just the novelty of this apparently-old feature. In any case, I wanted to see what I might be able to use this for. The first thing that springs to mind is CSV (Comma Separated Value) parsing. Now, I looked at parsing CSV values with Regular Expression patterns in JavaScript about 8 years ago. And, that approach is almost definitely more efficient and more elegant. But, I thought it would still be fun to try and parse a CSV value using .split().
A CSV payload contains field-delimiters, line-delimiters, and embedded delimiters (ie, delimiters that aren't really delimiters). It also contains field qualifiers and embedded qualifiers. Essentially, a CSV payload is a rather complicated delimited list. And, in this case, we're going to split that list on the set of known delimiters and then try to build the result set by iterating over the tokens and building up the fields.
CAUTION: I am not recommending you use this approach to parse CSV values. I am just doing this as a fun exploration.
// --
// CAUTION: This is not really an efficient way to parse CSV values. This is primarily
// an exploration in using the .split() method's capturing group behavior.
// --
// Let's create a fake CSV (comma separated value) payload. A CSV is essentially a
// string that contains several types of delimiters: field and line. Delimiters may
// also be embedded inside quoted fields. In this case, we using both commas and tabs
// for field delimiters and both double and single quotes for field qualifiers and
// both qualified and unqualified fields.
var input = String.prototype.trim.call(`
'id' 'name',isBB
1,"Kim",true
2,"""Sarah ""stubs"" Smith""","false"
3,Joanna,
4,'Tricia, Jr',false
`);
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// Our fields can be split by either the comma or the tab.
var fieldDelimiterPattern = /,|\t/;
// Our lines can be split using Windows or Unix line-break combinations.
var lineDelimiterPattern = /\r\n?|\n/;
// Our CSV payload will be split on BOTH the FIELD and LINE delimiters.
var delimiterPattern = new RegExp(
`(${ fieldDelimiterPattern.source }|${ lineDelimiterPattern.source })`,
"g"
);
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
// In this demo, a qualified field can be quoted with either double quotes or single
// quotes. As we split the payload up into tokens, we'll need to test to see if a given
// field is qualified and complete. These patterns will help us test to see if the token
// had leading and trailing quotes (taking into account embedded quotes).
var doubleQuoted = /^"(?:[^"]*|"")*"$/;
var singleQuoted = /^'(?:[^']*|'')*'$/;
// This pattern will tell us if the field does NOT start with a quote (which will
// indicate that it CANNOT contain embedded quotes or delimiters.
var notQuoted = /^[^'"]/;
var rows = [];
var row = null;
var field = "";
for ( var token of input.split( delimiterPattern ) ) {
// Ensure that we have an active row for our token.
// --
// NOTE: Empty rows will have a single empty-string field.
row || rows.push( row = [] );
// The token matches one of our delimiters.
if ( delimiterPattern.test( token ) ) {
// If we're currently building up a qualified field with embedded delimiters,
// just add the delimiter to the buffer.
if ( field ) {
field += token;
// Otherwise, if we have a line delimiter, let's end the current row. A new row
// will be started if we re-enter the loop on a subsequent token.
} else if ( lineDelimiterPattern.test( token ) ) {
row = null;
}
// The token matches a non-delimiter value (ie, complete or partial field value).
} else {
// If we have a field buffer, then append the current token; otherwise, use the
// new token as the field buffer.
field = field.length
? ( field + token )
: token
;
// If the field is not quoted, then we don't have to worry about any embedded
// delimiters. This means that the current field buffer represents a complete
// value and can be appended to the row.
if ( notQuoted.test( field ) ) {
row.push( field );
field = "";
// If the field buffer is empty, append it as a whole empty-string value.
} else if ( ! field ) {
row.push( field );
// If the field is qualified with double-quotes, unwrap the field and un-escape
// any embedded quotes.
} else if ( doubleQuoted.test( field ) ) {
row.push( field.slice( 1, -1 ).replace( /""/g, "\"" ) );
field = "";
// If the field is qualified with single-quotes, unwrap the field and un-escape
// any embedded quotes.
} else if ( singleQuoted.test( field ) ) {
row.push( field.slice( 1, -1 ).replace( /''/g, "'" ) );
field = "";
}
// NOTE: If we have a field buffer that is qualified (ie quoted), but only
// contains a leading quote, then will have to continue building up the field
// buffer on the next loop iteration.
}
}
// At this point, we've looped over all the tokens. If we still have a field value, then
// it means that something was malformed.
if ( field ) {
console.log( "Unexpected value in field buffer:", field );
}
console.log( "Parsed Results:" );
console.log( "===============" );
console.log( rows );
When we run this code through node.js, we get the following output:
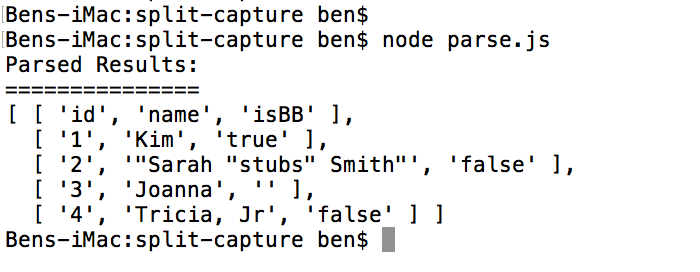
As you can see, we were able to successfully parse the CSV payload into a two-dimensional array of values. Again, I'm not recommending that you use .split() for this purpose. If you compare this approach to the RegEx-based approach, you'll see that this is significantly more complicated. But, this was just a fun exploration of what we can do if we return the delimiters in the result-set of the .split() invocation.
I'm always shocked when I come across something new in the foundational aspects of the JavaScript language. In this case, I've been using the String.prototype.split() method for ages; but, only just discovered that you could return the delimiters in the result-set. This opens up some new and fun ways to solve string-parsing problems.
Want to use code from this post? Check out the license.

Reader Comments
Another usefull application for splitting and keeping delimiter is for a look-and-say algorithm. The split parenthesis is key here. Thanks to you the prettiest implementation by far.
function see(value) {
return value
.split(/(1+|2+|3+|4+|5+|6+|7+|8+|9+)/)
.filter(x => x.length > 0)
.map(x => x.length + x[0])
.join('')
}
@Willem,
Interesting - I've not heard of the "Look and Say" algorithm before. I am looking it up now and am having trouble understanding the instructions. But, then again, it's 5:26 AM :D My brain needs time for the caffeine to kick in.
So, apparently I completely forgot about this post. 7-years later, I just ran into this behavior again; forgot that I wrote about it in 2017; and then just wrote about it again (2024):
www.bennadel.com/blog/4628-understanding-regexp-capture-groups-when-using-split-in-javascript.htm
I have a bad habit of double-checking stuff only after I publish an article 😆