
Visualizing API Calls And Asset Loading During Rolling Deployments Of Horizontally Scaled Servers
NOTE: This post is primarily for my own reference and something that I can use as a visual aid when I'm thinking about breaking projects down into smaller steps and deployments.
All web development and deployment has a certain degree of complexity associated with it. But, when you move from a single server to a horizontally-scaled set of servers, the relationship between the client-side code and the server-side code becomes more complex. And, if you're working on a single-page application (SPA), this complexity increases even more. The crux of the problem is that deployments no longer update "all the code" at the same time. This inconsistent server state, coupled with the "random" routing of the load-balancer, means that client-side code from one deployment will often have to communicate with server-side code associated with a different deployment.
When this "rolling deployment" problem is discussed, it's often discussed in terms of backwards compatibility - that your new server-side code has to be compatible with both the new client-side code as well as being backwards compatible with older client-side code. But, I think this is only half the story. Really, what you need is for your server-side code to be both "backwards" and "forwards" compatible.
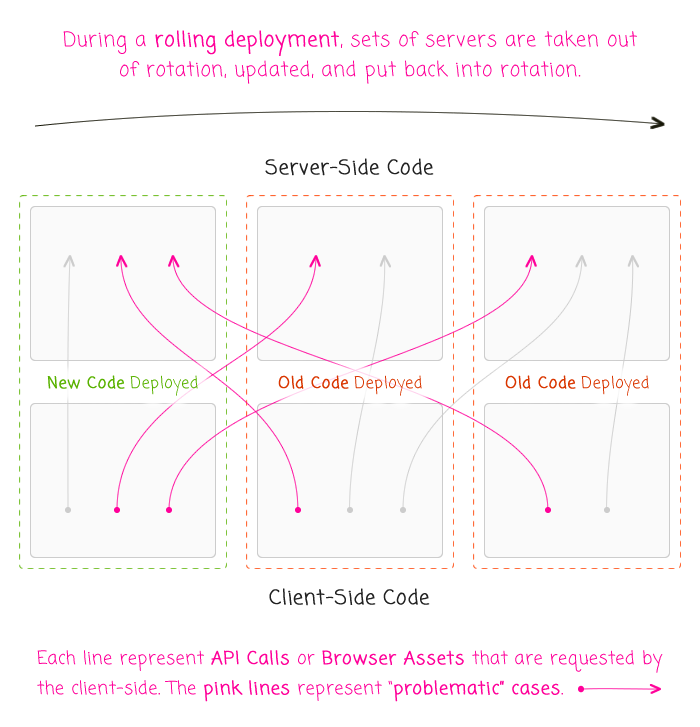
If you think about how a rolling deployment works (at least in my simplistic non-DevOps mental model), your farm of servers is broken up into sets. These sets are then removed from the load balancer in turn, updated, and returned to the load balancer. This means that during the lifetime of the deployment, you have both old and new client-side code communicating with both old and new server-side code:
| |
|
|
||
| |
 |
|
||
| |
|
|
As you can see, with a rolling deployment, the problem isn't just one of "backwards" compatibility - new servers being consumed by old clients. There is also a "forwards" compatibility problem - old servers being consumed by new clients.
Of course, "forward compatibility" isn't a real thing; old server-side code can't magically be compatible with client-side code that hasn't been written yet (assuming, of course, for the sake of the argument that the client-side code actually needs a new API). And, since we can't magically make code forwards compatible, it means that we sometimes have to take a single deployment and break it up into two serialized deployments: one that deploys the unconsumed server-side code first, followed by a second deploy that deals with the client-side code.
Working with a single-page application (SPA) makes this even more complicated because it increases the degree to which server-side code has to be backwards compatible. Instead of a single-version, in an application where client-side code is reloaded often, a single-page application means that the client-side may be several (if not many) versions older than the server-side code with which it communicates.
And, if you work with IFRAMES, things can get even more interesting! You could have old client-side code that loads a new IFRAME that, in turn, loads old assets (JavaScript, Image, and CSS files). With IFRAMES, the chance that you need to spread one logical deploy over separate physical deployments is even more likely.
Deploying your front-end assets to a Content Delivery Network (CDN) as part of your build and deployment pipeline may help with some of these issues; but, it certainly doesn't address all of them. It won't do anything to prevent newly-deployed client-side code from making calls to old server-side code, that's for sure.
Each application has a unique set of constraints. And, each deployment within that application has different requirements. But, one thing that I see often overlooked by developers - myself included - is the complexity of rolling deployments across a horizontally-scaled set of servers. Hopefully, discussing this will help drill it into my head.

Reader Comments
Some web apps, like Pivotal Tracker, occasionally force the user to do a hard refresh in order to load new client code-presumably to avoid some of the problems you're talking about. I can't imagine it avoids the "new client speaking to old server" (due to rolling deploy) problem, though.
It definitely creates a gnarly UX, but I think it's a tool that most apps should have ready to go for special occasions, like when a horrible security issue is discovered and you want those old clients to refresh ASAP.
As far as the new-client-old-server problem, I do think that deploying the backend code first is probably the simplest solution. Ideally, when the rolling *server* deploy is done is when you'd deploy your new client to your CDN. My thoughts aren't quite cohesive, but I think GraphQL APIs avoid some of these problems. That's one of the benefits Facebook has talked about, because they actually support several year-old (mobile device) clients!
I'm in the mobile gaming industry so this is a bit different but what we do when we release new versions of our games is we split the release up into separate pieces which are then deployed individually. Our separate deployments consist of database scripts, servers, assets (deployed to CDN), configs, and finally the actual client builds. These pieces are deployed in this order and never done in parallel. Each piece when deployed needs to be able to support the future one version deployments of all the other pieces down the line as well as being backwards compatible with all existing systems. If the server has breaking API changes the endpoints get versioned for the new client. Each separate piece also goes through it's own QA cycle which verifies the new functionality as well as backward compatibility. This works pretty well for us. Our QA process for a major release is obviously longer but it's worth it when having to deal with releases that have to go through approval processes and that take days to propagate to our players.
@Adam,
At InVision, we actually have a "Please refresh your page" alert that we can trigger via WebSockets. Though, to be honest, I totally forgot it was even there until you just mentioned it. It may not be in use anymore, I'm not sure.
Sometimes, it's also just a judgement call. I admit that there are times when I push code that I know may cause a breaking change during the lifecycle of the deployment; but, it's not a critical problem so I will just eat that cost. Sometimes, though, I might get too cocky about it.
One of the tricky ones that keeps hitting me is deleting Feature-Flag code. Imagine you have a flag that starts out as False, and then is slowly rolled out to 100% of the users. Then, once the feature is saturated and working properly, you can delete the code for it. But, you have to keep in mind how the feature flag works on the client. Often, it looks something like this:
// Client side code preparing view-model.
var canShowFeatureX = config.featureFlags.showFeatureX;
If this is an OLD CLIENT gathering config data from a NEW SERVER, the new server won't even return that feature flag if its been removed form the server-side code. As such, the old client, which still depends on that feature flag, will assume the feature has been turned OFF for the current user (since config.featureFlags.UNDEFINED is "falsey").
So, in the cases of feature flag removal, I actually find I have to do the following:
* Delete feature-flag dependency from client.
* Deploy client-side code.
* Delete feature-flag from server.
* Deploy server-side code.
* Delete feature flag from LaunchDarkly (in our case).
All to say, deploying the server-side code *first* isn't always the way to do things. In cases like feature-flags, you actually have to deploy the client-side code first so that random users don't "lose" the feature.
Of course, you could also argue that a feature-flag based feature is OK to lose during a deploy since it was just that - a togglable feature. Really just depends on the use-case.
Web development is hard :D
@Ross,
At InVision, I think we *can* do similar phases - but, at this point in our internal workflow, it's left up to the discretion of the engineer. Meaning, for example, most engineers will deploy their database migration scripts first, but not because it's a distinct phase - more just because they know (or hopefully think about) the fact that deploying the code at the same time may make things go boom! .... which, has happened from time to time.
Your QA process sounds interesting. Are things generally developed together, but then broken apart and tested for deploys? For example, I find that database changes and code general co-evolve, since the DB requirements change as I get deeper into the development of a given feature. But, then, I'll go back and break out the database migration as a separate deployment once the overall feature is fleshed out. Are you guys doing similar things?