
Using ObjectSave() And ObjectLoad() With Non-ColdFusion-Component Data Types
A few years ago, I took a quick look at the objectSave() and objectLoad() functions, introduced in ColdFusion 9. These functions serialize and deserialize ColdFusion data values using a binary format. When I first looked into these functions, I only tested them on ColdFusion components; and, found some interesting behavior. The other day, however, it occurred to me that I never tried using these functions with non-ColdFusion-component data types. So, I figured I'd give it a quick go.
For this exploration, I wanted to compare the binary serialization format objectSave() and objectLoad() to the serialization format that I think most of use: JavaScript Object Notation (JSON). How does the binary format compare in terms of speed and in terms of data-type integrity. The test is simplistic - I just serialize and deserialize some data a whole bunch of times:
<cfscript>
// Set up some non-Component data that will be serialized, saved,
// loaded, and then deserialized. Notice that we are including
// "ineresting" data types, including TimeStamps and Queries.
data = {
friends = [
{
name = "Tricia",
age = 47
},
{
name = "Joanna",
age = 52
}
],
enemies = [
{
name = "Amanda",
age = 38
}
],
createdAt = now(),
utc = dateConvert( "local2utc", now() ),
metaData = queryNew( "id, key, value" )
};
// ------------------------------------------------------ //
// JavaScript Object Notation Test.
// ------------------------------------------------------ //
startedAt = getTickCount();
jsonFile = expandPath( "./data.json" );
for ( i = 0 ; i <= 1000 ; i++ ) {
// Serialize and save.
fileWrite( jsonFile, serializeJson( data ) );
// Load and deserialize.
replicated = deserializeJson( fileRead( jsonFile ) );
}
writeDump( replicated );
writeOutput( "JSON: " & numberFormat( getTickCount() - startedAt ) );
// ------------------------------------------------------ //
// Binary Representation Test.
// ------------------------------------------------------ //
startedAt = getTickCount();
binFile = expandPath( "./data.bin" );
for ( i = 0 ; i <= 1000 ; i++ ) {
// Serialize and save.
objectSave( data, binFile );
// Load and deserialize.
replicated = objectLoad( binFile );
}
writeDump( replicated );
writeOutput( "Binary: " & numberFormat( getTickCount() - startedAt ) );
</cfscript>
The test uses a few different ColdFusion data types:
- String
- Number
- Struct
- Array
- Date/Time
- Query
And, when we run the above code, we get the following output:
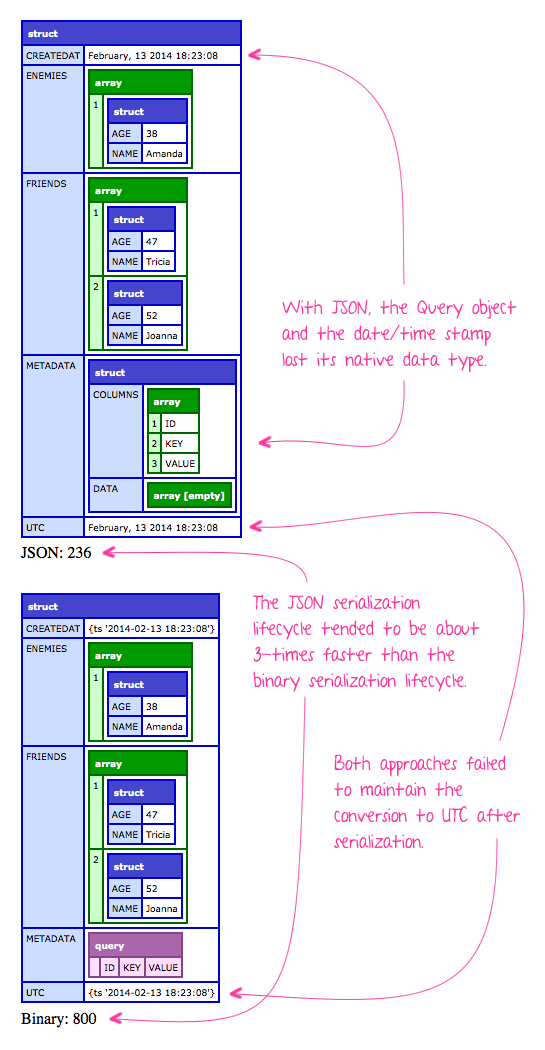
I was surprised to see that, on average, the JSON serialization lifecycle was about 3-to-4 times faster than the binary format. This was the oposite of what I (naively) expected. To me, the binary format seemed like it was going to be faster since, I assumed, it would be much less to process. I thought it was akin to taking a snapshot of memory and then just "reinserting" it into the heap. But, apparently, the binary format has more overhead, albeit, in a very simplistic test.
The benefit of the binary serialization lifecycle, in this case, is that it did maintain better integrity for some of the ColdFusion data types; namely, ColdFusion queries and ColdFusion date/time stamps. That said, both approaches appeared to lose the UTC-conversion (though, I am on ColdFusion 10 and I know the date/time stuff in ColdFusion 10 is junky-monkey).
NOTE: The objectSave() and objectLoad() functions kept the date/time object as an coldfusion.runtime.OleDateTime instance. The JSON approach kept it as a java.lang.String.
Four years after I first looked into it, I am still not sure what the best use-case for objectSave() and objectLoad() is. I wonder if this is how ColdFusion would interact with something like an out-of-process store like MemcacheD? I have read that using a binary protocol is faster than a text-based protocol; however, given this experiment, it seems that text parsing is actually faster? Who knows.
Want to use code from this post? Check out the license.

Reader Comments
For deserializeJSON() to give you queries back, you have to set the "strictMapping" parameter to false.
http://livedocs.adobe.com/coldfusion/8/htmldocs/help.html?content=functions_c-d_43.html
I've never understood why that wasn't the default since I would expect to get back what I put in unless otherwise specified.
@Brad,
Ah, right! I forgot that the JSON functions had the query flag. Good catch!
I would be interested to know if the results would be different with one large and complex json object, rather than many small and simple ones.
I have found a valid use case for objectSave/Load in unit testing. In those rare cases where we have a setup with session persistence turned on in either JRun/Tomcat, any data stored in the session scope gets serialized by Java on CF shutdown and deserialized on CF startup. If you have data in the session scope that is not serializable/deserializable, your users will be missing data post-restart. I found that using objectSave/Load in unit testing can test data you expect to be store in session scope to test whether it can serialize/deserialize without issue. This way if we modify, say a CFC, with something that fails the serialize/deserialize process, the unit test can tell us of the failure well before we go to production. I have this working in a few cases and has proved very valuable.
Truthfully, I would never recommend session persistence be turned on but I did not have a choice in this case.
@Damon,
Very interesting use-case.