
Aggregating XML Node Text In A ColdFusion XML Document
The other day, I was working with XML data that represented HTML markup coming back from a Yahoo! Query Language (YQL) request. By default, ColdFusion XML documents consider the XmlText value of an XML node to only be the aggregate of the text nodes that are the direct descendant of a given node. In general, this is not a problem since text nodes and element nodes are rarely combined in the same set of children. However, in an HTML-as-XML document, this kind of heterogeneity is common as there are many inline HTML elements designed to decorate a string of text. And, if you wanted to extract text from an HTML-as-XML document, you need to apply a little more elbow grease.
Consider the following XML document:
<data>
<message>
You are <em>wicked</em> sexy!
</message>
</data>
Here, you can see that the message node has three children: two text nodes and an element node. If we were to try and reference the xmlText of the message node (messageNode.xmlText), ColdFusion would give us:
You are sexy!
As you can see, it concatenated the two child text nodes on either side of the element node - em.
Like I said before, this typically isn't a problem since we don't often mix text and element nodes at the same level - at least not in a meaningful way. However, if we wanted to extract the text-only portions of the message including all of its descendant nodes, the default ColdFusion XML structure presents a bit of a problem. We can't simply "walk" the XML tree, gathering text values, since the xmlText attributes are automatically concatenated.
Luckily, we have a few options. For one, I've been sort of misleading you (sorry, I'm very naughty sometimes)! I keep referring to the "default structure" of ColdFusion XML documents; but, the truth is, the default structure does have a way to handle this natively - you just can't see it in any CFDump output. In addition to the standard xmlChildren attribute, ColdFusion XML element nodes also have an xmlNodes attribute.
See, ColdFusion wants to make our lives easier, so it creates an xmlChildren attribute that gets the job done in 99% of cases; however, in the 1% of cases that don't quite fit into the typical element node structure, the xmlNodes attribute allows us to access the raw XML architecture without any built-in efficiencies.
To see what I'm talking about, take a look at the following code. We are going to output the child nodes of the message node (from our previous XML document) - first with the xmlChildren attribute and then with the xmlNodes attribute:
<!--- Get our Message node. --->
<cfset messageNode = data.xmlRoot.message[ 1 ] />
<!--- Output with xmlChildren. --->
<cfdump
var="#messageNode.xmlChildren#"
label="xmlChildren"
/>
<br />
<!--- Output with xmlNodes. --->
<cfdump
var="#messageNode.xmlNodes#"
label="xmlNodes"
/>
Running this code gives us the following CFDump output:

As you can see, the xmlChildren attribute provides access to all the element nodes - what we want in most cases. The xmlNodes attribute, on the other hand, provides us with access to all the child nodes, element or otherwise.
With this xmlNodes attribute, we now have the ability to walk the actual XML tree and gather up our text values. But, honestly, tree traversal is a lot of work and requires a good deal of recursion and string concatenation; and, as you have probably heard a few times from many people, string concatenation is the worst when it comes to performance.
So, rather than manually walking the tree, let's use ColdFusion's xmlSearch() function to execute all the heavy lifting. Rather than walking the tree to find to the text nodes, we can simply search a branch of the XML tree (ie. a node) and get an array of all the text nodes in depth-first order. This way, we can get all the benefits of recursion without any of the overhead.
To demonstrate this approach, I have put together a ColdFusion user defined function (UDF) - xmlGetText(). This UDF takes an XML node and returns an aggregation of all the text nodes in the given XML branch.
<cffunction
name="xmlGetText"
access="public"
returntype="string"
output="false"
hint="I aggregate the text value in the given node and all of its child nodes.">
<!--- Define arguments. --->
<cfargument
name="node"
type="any"
required="true"
hint="I am the XML node for which we are aggregating the XML Text."
/>
<cfargument
name="delimiter"
type="string"
required="false"
default=" "
hint="I am the delimiter used when concatenating all of the aggreated text value."
/>
<cfargument
name="trimValues"
type="boolean"
required="false"
default="true"
hint="I flag whether or not to trim the XML text value before adding them to the buffer. More often than not, this is what we want to do."
/>
<!--- Define the local scope. --->
<cfset var local = {} />
<!---
Create our string buffer. We are going to concatenate all
of the string values; but, we don't want to perform any
concatenation until necessary.
--->
<cfset local.buffer = [] />
<!---
Query the node for all descendant text nodes. XmlSearch()
will return an array of text nodes in a depth-first
traversal of the XML tree. This allows us to make sure that
the text nodes are returned in the natural, expected order.
--->
<cfset local.textNodes = xmlSearch(
arguments.node,
".//text()"
) />
<!---
Loop over the text nodes to add non-zero-length values to
our text buffer.
--->
<cfloop
index="local.textNode"
array="#local.textNodes#">
<!--- Get the current value. --->
<cfset local.textValue = local.textNode.xmlValue />
<!--- Check to see if we are trimming the value. --->
<cfif arguments.trimValues>
<!---
Remove any leading or trailing white space that may
have been an unintended side-effect of the structure
nature of XML documents.
--->
<cfset local.textValue = trim( local.textValue ) />
</cfif>
<!--- Check to make sure we have a valid length. --->
<cfif len( local.textValue )>
<!--- Add this value to our buffer. --->
<cfset arrayAppend( local.buffer, local.textValue ) />
</cfif>
</cfloop>
<!---
At this point, we have populated our text buffer with any
valid text nodes. Now, join the buffer on our delimiter and
return the value.
--->
<cfreturn arrayToList( local.buffer, arguments.delimiter ) />
</cffunction>
<!--- ----------------------------------------------------- --->
<!--- ----------------------------------------------------- --->
<!--- ----------------------------------------------------- --->
<!--- ----------------------------------------------------- --->
<!--- Define our XML document. --->
<cfxml variable="data">
<data>
<message>
You are <em>wicked</em> sexy!
</message>
</data>
</cfxml>
<!--- Get our Message node. --->
<cfset messageNode = data.xmlRoot.message[ 1 ] />
<!--- Output the structure of our message node. --->
<cfdump
var="#messageNode#"
label="Message Node"
/>
<cfoutput>
<br />
<!--- Output the default text value of the message node. --->
Message.xmlText: #messageNode.xmlText#<br />
<br />
<!---
Now, let's gather the text of the message node (in aggregate
with all of its child nodes).
--->
xmlGetText( message ): #xmlGetText( messageNode )#<br />
</cfoutput>
As you can see, the xmlGetText() function uses the xmlSearch() function to return all the text nodes that are descendant from the given node. Then, it simply has to loop over the text nodes and build a single aggregate string. It does this using an intermediary buffer so as to avoid string concatenation for as long as possible.
When we run the above code, we get the following page output:
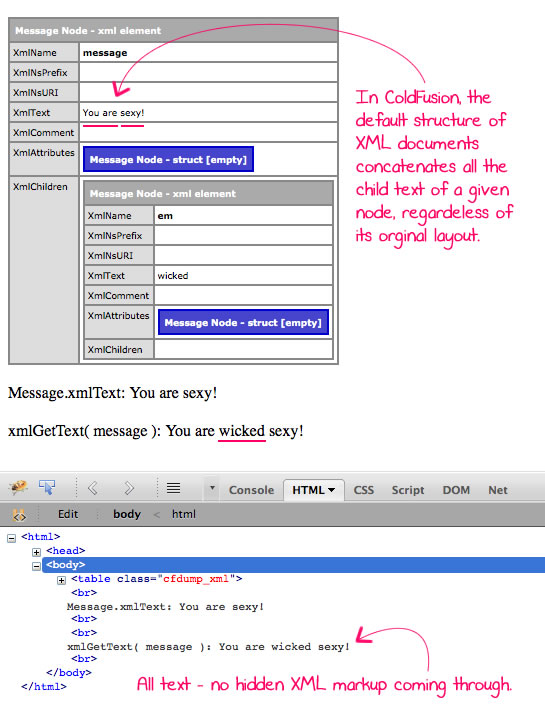
As you can see, the xmlGetText() user defined function is able to build the aggregate text value without a problem.
ColdFusion is such an amazing language. I love that it seeks to provide the most user-friendly way of accessing data; but, at the same time, it also provides all of the low-level hooks that might be needed in the rare use cases. Even after years of ColdFusion programming, I am still in complete awe of how well thought out so many aspects of the language really are. Well done ColdFusion, well done!
Want to use code from this post? Check out the license.

Reader Comments
It really sounds like the <message> element should have used a CDATA tag for it's content:
<data>
<message>
<![CDATA[You are EM wicked EM sexy!]]>
</message>
</data>
This treats the contents of the <message> tag a literal string instead of treating the tag as a child node.
Depending on your needs, it might be easier to use a RegEx to add a CDATA tag to the XML before parsing.
It just seems like this might be an easier path to the problem you were originally trying to solve (but I'm inferring here, so I could be way off base.)
@Dan,
Oops, I think the EM tags got lost in the comment there (as actual HTML) - I'll try to fix that.
The XML that I am getting, in this case, is from a Yahoo! Query Language request. So, it's their interpretation of HTML as converted to XML. I don't really have much control over how the XML is created or where CDATA is applied.
I suppose I could manually add the CDATA after I get their XML string; that would allow me to get the "EM" with the data. But, my goal (in this particular case - not stated in the blog post) was to get the basic string version of the parent element.
In any case, this was the first time I used xmlSearch() to this extend -- which is the part of was really excited about :)
This is really nice! I ran into this problem a while back and totally missed xmlNodes. I bet that would have made things much easier!
@Ben:
How timely! I was thinking about the problems of mixed content (mixed text and tags) in jQuery just last night!
I started out trying to write my own Greasemonkey user script that would highlight the current page in the same manner that Google does when you click a "Cached" hotlink. (Search terms get a background colors that make them easier to spot in the page.) I wanted to be able to do that on any page with any arbitrary string.
I eventually abandoned the idea when I realized that Firefox already had the ability to do exactly that for you, even without Greasemonkey installed: Edit > Find > Highlight All (a feature I never noticed till I started thinking about user scripts to do the same).
Still, you can see that the problem of mixed content vexes the jQuery coder just as much, although in a different way. You have the .innerText property (analog of using xmlNodes to aggregate text), but you can't use it to rewrite the HTML without throwing away markup. And you have the .innerHTML property, but that interferes with spotting the string to be highlighted.
What I'd LIKE to do is iterate over DOM "text nodes", if jQuery had a selector for that, just as you did with xmlNodes. Then you could take
and highlight "c d" with
Oh well, it's unnecessary because of Highlight All. But you can understand why it was so fun and intriguing to read about doing the same sort of thing on the server.
Another great article!
Trying again without escaping angle brackets:
... Then you could take
and highlight "c d" with
This is not exactly what you are talking about here (or is it?), but I also often use Xpath's string() function to get the same result:
@Steve,
Yeah, it's a bit frustrating that they don't show everything in CFDump. Even if they showed it and the value was "Not Displayed", at least we would remember the keys existed.
@WebManWalking,
Finding mixed-node content is one thing - changing it is a completely different story :) At that point, I think complications get taken to the next level.
@Kirill,
Hmmm, very interesting! I'll have to try that one ASAP.
@Kirill,
AWESOME!!!! I just tried this out for myself:
www.bennadel.com/blog/2190-Using-The-XPath-String-Function-In-XmlSearch-To-Aggregate-Node-Text-In-ColdFusion.htm
You sir, are amazing :) Thanks!
I am integrating the USPS International Shipping Rates API into a shopping cart right now. This info is coming in very handy. Once again, thanks for the great tutorial.