
Reading In File Data Using ColdFusion 8's New File Functions
A couple of weeks ago, I demonstrated how to read in file data one line at a time using either ColdFusion's new CFLoop functionality or Java's LineNumberReader. Recently, however, Martin reminded me that there are also new function-based equivalents to the CFLoop behaviors that I showcased. I've always been a tag-based coder so I sometimes forget that certain functions exist. As such, I thought I'd take a moment to redo my previous demo using the new file-oriented functions.
Just as we did before, we are going to create a text file, populate it with some data, read that data back in, and display the contents on the page. The file reading will be done in two different ways - by line and by character chunk.
<!---
We are going to be reading in a file, line by line, so first,
let's create a file to read. Define the path to the file we
are going to populate.
--->
<cfset filePath = expandPath( "./data.txt" ) />
<!---
Delete the file if it exists so that we don't keep populating
the same document.
--->
<cfif fileExists( filePath )>
<cfset fileDelete( filePath ) />
</cfif>
<!---
Create a file file object that we can write to. We have to
explicitly define the Mode as Append otherwise the file will
be opened on read mode.
--->
<cfset dataFile = fileOpen( filePath, "append" ) />
<!--- Write some data to the file. --->
<cfloop
index="i"
from="1"
to="10"
step="1">
<!---
We could use either fileWrite() or fileWriteLine() here.
However, fileWriteLine() will automatically append a line-
break after each file write.
--->
<cfset fileWriteLine(
dataFile,
"This is line #i# of 10 in this file."
) />
</cfloop>
<!---
Now that we have finished writing the file, let's close it.
This will close the stream which should prevent any unintented
locking on the file access.
--->
<cfset fileClose( dataFile ) />
<!--- ----------------------------------------------------- --->
<!--- ----------------------------------------------------- --->
<cfoutput>
<!---
Now, we are going to read the file in line-by-line using
ColdFusion 8's new file functions. First, we need to open
our file and get a handle on the input stream.
NOTE: We could have left out the "Read" mode as it is
the default mode of the file object.
--->
<cfset dataFile = fileOpen( filePath, "read" ) />
<!---
Read the file in one line at a time. When we do this, we
can only read until we have reached the End of File (EOF);
otherwise, we'll get a ColdFusion error for "End of file
reached."
--->
<cfloop condition="!fileIsEOF( dataFile )">
<!--- Read the next line. --->
<cfset line = fileReadLine( dataFile ) />
Line: #line#<br />
</cfloop>
<!--- Close the file stream to prevent locking. --->
<cfset fileClose( dataFile ) />
<br />
<!---
The new file functions also allow us to read in chunks of
a file at a time (not just lines... which are chunks in a
sense). Here, we are going to read the file in 50 characters
at a time.
Again, we have to open the file for reading.
--->
<cfset dataFile = fileOpen( filePath, "read" ) />
<!--- Keep looping until we reach the end of the file. --->
<cfloop condition="!fileIsEOF( dataFile )">
<!--- Read in upto 50 characters. --->
<cfset chunk = fileRead( dataFile, 50 ) />
50 Char Chunk: #chunk#<br />
</cfloop>
<!--- Close the file stream to prevent locking. --->
<cfset fileClose( dataFile ) />
</cfoutput>
As you can see, we are making use of many of the new file-oriented functions provided in ColdFusion 8. The first half of the demo reads in the file one one line at a time (as delimited by the new line and carriage return characters). The second half of the demo reads in the file 50 characters at a time. When I run the above code, we get the following page output:
Line: This is line 1 of 10 in this file.
Line: This is line 2 of 10 in this file.
Line: This is line 3 of 10 in this file.
Line: This is line 4 of 10 in this file.
Line: This is line 5 of 10 in this file.
Line: This is line 6 of 10 in this file.
Line: This is line 7 of 10 in this file.
Line: This is line 8 of 10 in this file.
Line: This is line 9 of 10 in this file.
Line: This is line 10 of 10 in this file.50 Char Chunk: This is line 1 of 10 in this file. This is line 2
50 Char Chunk: of 10 in this file. This is line 3 of 10 in this f
50 Char Chunk: ile. This is line 4 of 10 in this file. This is li
50 Char Chunk: ne 5 of 10 in this file. This is line 6 of 10 in t
50 Char Chunk: his file. This is line 7 of 10 in this file. This
50 Char Chunk: is line 8 of 10 in this file. This is line 9 of 10
50 Char Chunk: in this file. This is line 10 of 10 in this file.
50 Char Chunk:
This works quite nicely. And, while there are more functions available to us, the only ones that I needed for this demo were:
- fileExists( path )
- fileDelete( path )
- fileOpen( path [, mode, charset ] )
- fileWriteLine( file, data )
- fileReadLine( file )
- fileRead( file [, charset ] )
- fileClose( file )
- fileIsEOF( file )
NOTE: fileRead() also accepts a file path instead of a file object. Using it in this way returns the entire content of the file. While this is very useful, it does not pertain to either of the approaches demonstrated in this blog post.
When we open a file using fileOpen(), ColdFusion creates either an input or output stream for that file and returns a reference to the file object. Not only is this file object used in conjunction with many of the file functions, it also provides us with information about the file in question. CFDump'ing the resultant file object gives us something that looks like this:
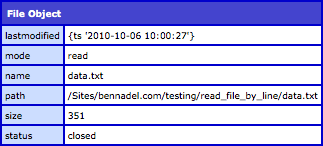
The status of the file can be either "open" or "closed". If it the file is closed, you can no longer perform any actions on it. If the file is open, the actions that you are able to perform are based on the mode in which the file was opened. By default, the fileOpen() function opens the file in "read" mode which only allows you to invoke read-based functions on it. Any attempt to write to a file that has been opened in "read" mode will result in the following ColdFusion error:
Write cannot be called when the file is opened in read mode.
Conversely, any attempt to read from a file that has been opened in "write" mode will result in a similar error:
Read cannot be called when the file is opened in write mode.
If you want to write to a file, you need to open it in either "write" or "append" mode. If you open a file in "write" mode, write-based actions will overwrite the entire contents of the existing file (if it exists). If you open a file in "append" mode, on the other hand, write-based actions will simply append the content to the existing file (if it exists).
When you are done reading from or writing to a file, it is best to close the file stream using fileClose(). Doing this allows the operating system to release its hold on the file which will help to prevent unexpected file locking. While I was not able to actually demonstrate (deliberately cause) any file locking problems, it is definitely a best practice to explicitly relinquish control over a given file when it is no longer required.
NOTE: You still have access to the file object properties after the file stream has been closed.
I know there are a lot of people who swear by Script-based programming and don't much care for using CFML tags; but, if you compare this demo to my previous demo, you'll notice that using the file functions in lieu of the file tags actually requires us to use a bit more logic. The CFFile and CFLoop tags nicely encapsulate all of the file-stream management so that we don't have to care about locking or modes (as much). Now, I'm not saying you shouldn't use these functions - I'm just saying that sometimes, CFML tags provide a really nice interface to core functionality. The best solution is going to involve knowing when to use the most appropriate approach.
Want to use code from this post? Check out the license.

Reader Comments
First Comment! :)
I'll also mention fileSeek. Useful if you want to read the "end" of a large file.
@Eric,
Ha ha, well played.
@Ray,
That sounds cool. It looks like CF9 added even more functions for files (and directories).
Is CF8 still considered new? It's new to me, but I'm now starting to migrate to CF8 and CF9 for different sites...
I think Ben was referring to functions newly available in CF 8.
This is great for reading files, but is there a way to write a line of code within the file, not appending to the end? I need to loop over the file and at a certain line, add some text, is this possible?
@All (tangential),
The cffile feature I've always wanted was the ability to specify action="upload" with variable="variablename".
Before ColdFusion existed, I coded a HTTP File Upload routine in plain ANSI C that broke down the multipart/form-data post and grabbed the file upload data directly. So I know that an HTTP File Upload is not to a file. It's actually available in memory. So why does CF force us to do an I/O to the file system in cffile action="upload", only to have to do another cffile action="read" to get it into a variable? Seems kinda inefficient, requiring 2 I/Os to gain memory access to an upload that's already in memory, doesn't it?
Ever since CFMX gave us access to Web Services, I haven't had any need to do an HTTP File Upload. So maybe a direct-to-memory way of accessing a file upload exists now. But if not, why not? It's not like I haven't suggested it often enough to Allaire, Macromedia and Adobe.
@Eric: The canonical first comment is "Firsties!" :-)
@Dan,
According to the docs for fileSeek, it works for both file reading and writing operations. That implies you can seek to position N and write there. I'll confirm this in a few minutes..
@Steve,
all cffile/upload does is just copy the tmp file to a location you want to store the file in. As it stands, the web server _has_ to do some file i/o for the uploaded file (afaik).
@Dan,
Just an FYI, I can confirm you can write to a file at any position with fileSeek. However, it overwrites. It does not insert. Looking into this more.
@Steve,
A number of people have asked for this kind of functionality; but in order to do this, ColdFusion would have to defer ALL file writes on uploads as the files are uploaded before your file actually runs. If you do that, then you have to start to worry about referential integrity and garbage collection.
Image a request that uploaded a 10MB file. Then, in the page that processed the request, a CFThread is launched that runs in parallel. In order to make the parent page variables available to the thread, ColdFusion would NOT be able to clear the file out of the RAM until the thread had finished executing (and the parent page finished executing).
Now, of course you run into the same problem if you read the file in manually; but, I suppose at that point, you are demonstrating an understanding of how variables need to be referenced???
My gut feeling is that it could get complicated, memory-wise really fast.
@Ray,
Are you planning to demo the fileSeek() functionality? Seems very interesting.
@Ben,
I've got a little demo now - but want to figure out if insert is possible. Overwrite is pretty limited I'd assume.
@Ray,
Groovy shoes :) If you find something cool, let us know.
Ben, Ray and others:
the reason I asked about this is I am trying to automate a process we are doing manually now. We have inline queries we are moving to cfc's. I figured if I could find the queries inline, I could add a beginning comment and an ending comment tag which would comment out the query we are moving to cfc's. Being able to pick the line the <cfquery tag is on to add the comment tag would be awesome.
So, if fileSeek will let me do this, that would be awesome or "groovy shoes" :)
thanks
dan
Pretty sure the answer will be no. In my research at the Java level it seems as if fileSeek will allow you to overwrite text only, not insert.
Now - in your example - you are talking about updating CFMs. Even in my most butt ugly code, I've never gone over 3k or so lines. You can fileRead that entire thing easily enough. That's going to have no real impact on RAM. So I'd say fileRead the whole sucker, do an insert(), then fileWrite it back.
Hmmm,
since I have not used the insert function before, this should be interesting.
so i just do a cffile action=read this will read line by line...
when i find my line, i should be able to insert ()into the file not sure how to figure out position...
the filewrite it back part not sure about.
I guess sometimes seeing the code is easier for me than trying to picture it in my head...ugh
insert() is just one of the many string functions. To be honest, I can't remember the last time I used it.
But basically - I wouldn't even bother with reading line by line.
Suck in the whole thing as a string. For each cfquery tag pair you find you insert a opening CFML comment before it and a closing one after it.
If you want a demo of that - I could write something up.
a demo, if it's not too much trouble...i kinda understand, but I am not 100% sure.
thanks
@Dan,
I agree with @Ray that you really won't have any problem at all reading an entire CODE file into memory and manipulating it. If that causes a memory issue... you might have some more pressing concerns to address.
As far as commenting out the query code within the file, you might be good with a regular expression replace. Something like:
... I haven't tested this, but it would replace the CFQuery tag/body with itself surrounded with comments.
@Dan,
Just use Ben's regex. :)
Oh - except change it to reReplaceNoCase or add the case insensitive flag.
so, should I put Ben's regex inside a loop, or just by itself?
I am reading the file:
<cffile action="read" file="c:\coldfusion9\wwwroot\newtest\cfqueryPage.cfm" variable="readThis">
now, should I just use is code after that, or in a loop? Then, how does it actually get changed in the file?
I feel stupid asking these questions, however, if I actually knew what to do, i wouldn't ask the questions...duh :)
thanks
@Ray,
Good point regarding reFindNoCase().
@Dan,
After you read in the file, then you run the reReplaceNoCase() on the content, then write the file back to disk (pseudo code):
I've left out some attributes there, but that's the basic work flow.
Ok, so I am dumb. I re-read your posting and tried what you said. I read the file, i did a replace with the regex then over wrote the file with the variable. This added the comment code into the file.
that really helped me do what I needed.
As always you guys are big helps!!
Dan
@Dan,
.... and of course, test this on some TEST files before you unleash on code that is mission critical :)
@Dan,
Awesome!
@Ben,
He doesn't have to test. He is using source control.
Right Dan? :)
@Ray,
I'm not sure CMD-Z will work with this?? Oooh, you mean the other kind of source control :)
The real hard core programmers go into their folder, select, ctrl-c, ctrl-v. Done.
@Ray,
I've always been a fan of File >> Save As >> {file}.BAK :)
Cmd-C, Cmd-V. Done. Just like Ray said, but on a Mac! I thought that's what version control meant?!? :)
@All,
No one seems to know this, so here goes. When you don't specify enctype="multipart/form-data", a post looks like this:
When you do specify enctype="multipart/form-data", a post looks like this:
The boundary value ("something", in this case) was chosen by the browser to be a string that doesn't occur anywhere in the posted data. It's usually very gobbledy-gooky. The server uses the boundary to decode the multipart encoded data. Assuming that the boundary is "something", the header is "--something", followed by a Content-Disposition. The trailer is "--something--". If you want to see what the data looks like:
Web forms: http://www.w3.org/TR/html401/interact/forms.html#h-17.13.4.2
E-mail: http://www.w3.org/Protocols/rfc1341/7_2_Multipart.html
But my point is this: It's just like a regular post, only encoded differently for greater efficiency with files. The name is given in the Content-Disposition. The value is given between the header and trailer. There's a filename field in the Content-Disposition, but it's only what the filename was on the client. There isn't anything anywhere in the post that says where the file is supposed to go on the server. It's exactly the same as field=value, only completely different. :-)
So Raymond was partially right. But it isn't the web server that writes file data to a file. (It doesn't know where to put it.) It's ColdFusion that feels the need to write the form data out to a file for some reason. Perhaps it wants to save on memory, as Ben suggested. CF writes the file to a SERVER-INF/temp subdirectory.
In the process of writing a little tester file just now, I discovered that Form.FileFieldName contains the SERVER-INF/temp subdirectory/file name, so we can at least eliminate one I/O by reading it directly (doing action="read" right away, instead of action="upload").
The flip side of that coin is that there may already be some people who discovered this and are relying on that CF behavior to avoid I/O. So the fact that Form.FileFieldName contains a path and filename can't change. I guess that explains why Allaire, Macromedia and Adobe never figured out a source-code compatible way to add that feature. They had committed to doing at least one file I/O no matter what.
@Steve,
I guess I just don't see what the need is here. (Not to say there isn't of course!) In every single app I've done with file uploads, there is always a set of checks (valid file, size check, etc) that is done before the file is considered valid and stored in it's final location. CFFILE/upload can do some of these checks for you (type, although it isnt very secure), but it really just acts as a simple way to copy from tmp to your desired location.
Thinking more on this. If you are ok with doing a file read anyway, is the move op (that cffile/upload does, i said copy above but meant move) that big of a deal?
@Raymond,
Oh, I'm not really okay with doing a file read, as compared to doing no I/O at all.
Suppose hypothetically Adobe defined a new suffix ".cfu", which is the the same as ".cfm", except that, if a multipart/form-data post came in, it would put the file contents into Form.FileFieldData instead of writing it out to a temporary file location. You would use .cfu only as the action page of any form post where you anticipated a file. Use CF Admin > Settings > "Maximum size of post data" to prevent abuses of memory by denial of service attacks. Done. No I/O.
Compare that to one I/O to write to the temporary file, one I/O to move it where you want it and one I/O to read it. Three I/Os.
I was just saying that doing a cffile action="read" instead of cffile action="upload" does two I/Os instead of three. I wasn't saying that two I/Os were better than none.
If you want to keep the uploaded file on the server, I suppose it's all the same, but we're not allowed at my [government] site to do that. By security edict, no user is allowed to save a file onto the server's file system. Because cffile action="upload" gives us no choice, we had to process it and immediately delete it. But what if we crashed before getting to delete it? Much safer if it was never on the hard drive in the first place. Ultimately, we had to give up on HTTP File Upload in favor of Web Services for exactly this reason.
Just different security policies, that's all.
Hmm, ok, interesting argument there. Although I will say that if you simply cffile/upload to a location outside of webroot yous should be perfectly safe. There is never a reason why one should put a file under web root, _even_ if you immediately delete. My own product, Galleon, got hacked that way.
@Steve,
Very interesting point regarding the security policy of saving files onto the disk. I had never even considered something like that.
Great post Ben and great discussion going on here in the comments too.
I was looking at the new file functions specifically for reading (potentially) large amounts of data.
I like the fact that fileOpen() and fileReadLine() let you get into a file without having to load the entire thing into memory.You can start reading it without any idea of how long it is going to be.
My understanding of cfloop was that it needs to load the entire file with cffile action="read" into memory first (even though it doesn't parse it). Does that sound correct to you?
Cheers
Martin
Ben and Ray,
Source Control, what is that? You mean when we do some updates on code and we don't want to screw up the working code? Well, we just make a new folder using explorer and copy all the files there and start to work...isn't that good enough :)
Trust me, I have done a simple presentation on the value of source control, and I am trying to get at least Subversion in place...it is a struggle convincing old school people (not programmer mind you, but PM) that subversion is critical to our success...granted testing is not something we concentrate on here highly either, but one problem at a time :)
Again, thanks for all your help, when I showed my co-worker my basic proof of concept, he started coming up with all sort of ways to expand on my concept to really enhance what it does and how it can help.
dan
@Martin,
I believe that CFFile/read does read the entire file into memory; however, I would think that the CFLoop/file approach actually uses the LineNumberReader under the hood. I wish I could find the reference, but I could swear that someone on the engineering team told me this to be true.
@Dan,
Glad you're getting some good stuff out of this conversation (I know I am).
I do use source control (for real)... but I could be MUCH BETTER at it. I'm interested in looking into Git to have both a local and live repository. This way, when we submit to a live repo, we don't always have to be slow.
Ben,
All of the examples I've seen here and on other web sites use FileClose on a file that was explicably opened ( like fileOpen(SomeFile) ).
My question concerns reading a file via CFLoop.
The CF documentation states that ColdFusion closes the file when the loop finishes executing.
However, I wouldn't want to depend on that. I would rather check to see if it's open and then close it. But, how would this be done after a Cfloop action?
Thanks,
Mike
@Mike,
I don't know how to do that. I am not sure if you can close a file input stream without having a reference to the stream that opened it. That is beyond my understanding of Java.
I would simply suggest that you don't worry about it unless it's actually causing a problem. ColdFusion is an abstraction layer that is meant to hide us from the difficulties of Java. As such, I would assume they thought this one through and took steps to make sure files wouldn't get locked.
Sorry I don't have better advice on that one.
Hello all,
I'm sure there's some n00bish error I'm making here (not new to ColdFusion, just to file-related functions).
I'm using the following code to try to generate and write to a file on the server, and I just can't get it to work.
<cfset file = expandPath("./nodata.txt")>
<cffile action="write" file="#file#" output="#form.program#" mode="777" addnewline="true">
I get no errors...just...nothing. If I replace the file-related code with a cfquery I'm able to successfully write #form.program# to a database.
For context, the variable #form.program# is being provided by a jQuery $.post Ajax call.
Many thanks for any insight you might provide.
Hi, I try to read a 325Mb csv file with fileOpen but I get a Java error... Maybe the file is too big ?
I tried with cffile, cfhhtp and I got "java.lang.OutOfMemoryError: Java heap space"; that's why I'm looking at fileOpen.
Some help would be appreciated !
Thanks
Also....
Is it possible to read just few lines in a file (and read the whole file in multiple steps) ??
Ex: read from 1 to 50 000
then from 50 001 to 100 000
then from 100 001 to 150 000
then....
how to get the file data line by line in cold fusion? My file contains the data in |(pipe) delimiter format and In that file How I need to get the 17th delimiter value and how to change that column value in the same line and how to add that modified value in the same line
Can you pls post the sample data in cold fusion.
@Raheman,
Have you checked the docs? There is a fileReadLine function.
Thank you for the post. It helped me with a problem that I had today reading a .txt file.