
Working With Inconsistent XML Structures In ColdFusion
After my recent post on moving XML data into a database, several people have asked me how to best go about working with XML documents in ColdFusion that do not have a consistent structure. While this might sound like an odd scenario, when dealing with 3rd party XML APIs, it's actually quite common. For example, when getting shipping information from UPS, often times their XML response structure will differ depending on what they have on file. As such, your processing code might need special logic to deal with things like a missing "company" node or "name" node.
I have several ways of doing this, but, before we can discuss the solutions, let's take a look at some sample XML. For this post, I'm going to assume we are working with an XML response that might contain this entire structure:
Full XML Response
<!---
Create our respone data template. This is the XML template
that uses all of the possible options.
--->
<cfxml variable="completeData">
<response>
<contact>
<name />
<email />
</contact>
<address type="business">
<street />
<street />
<company />
<city />
<state />
<zip />
</address>
</response>
</cfxml>
As you can see, this XML response data contains a contact and an address node, each with its own child nodes. In our XML processing logic, we are going to assume that the XML response that we actually receive may contain all or only some of the data defined by the full XML response. For demonstration purposes, we are going to use this as our given XML response:
Simulated XML Response
<!---
Create our response data using just some of the possible
data that is available.
--->
<cfxml variable="partialData">
<response>
<contact>
<name>Tricia</name>
</contact>
<address>
<zip>10016</zip>
</address>
</response>
</cfxml>
As you can see, our simulated XML response has both the contact and the address nodes, but it is missing almost all child elements as well as the "type" attribute of the address node.
Now that we have our ColdFusion XML documents, completeData and partialData, we can look at how to move the inconsistent XML data into the database. For the rest of this demo, please assume that I have a database table to contain each one of the leaf nodes in the complete XML document.
Brute Force Node Existence Checking
My first approach to working with inconsistent XML structures in ColdFusion is a brute-force approach in which we manually check for the existence of each target node before we extract its value. Because ColdFusion wraps up XML node sets in named collections that mimic structures, we can use things like StructKeyExists() and ArrayLen() to check for the desired nodes by name:
<!---
Create a container to hold our xml data. This container will
start off with all of the default data for the values. This
way, we only override the default values if the nodes are
found in the target xml document.
--->
<cfset data = {
name = "",
email = "",
street1 = "",
street2 = "",
company = "",
city = "",
state = "",
zip = ""
} />
<!---
Now that we have our default data structure, we can start
checking the XML response data for our target nodes. Remember,
we will only overrid the default data above if we find a node.
--->
<!--- Check to see if the contact nodes exists. --->
<cfif structKeyExists( partialData.xmlRoot, "contact" )>
<!---
Get a short hand reference to the contact node so that
our subsequent checks and retrievals are shorter and
easier to read.
--->
<cfset contactNode = partialData.xmlRoot.contact />
<!--- Check to see if the name node exists. --->
<cfif structKeyExists( contactNode, "name" )>
<!--- Get the name value. --->
<cfset data.name = contactNode.name.xmlText />
</cfif>
<!--- Check to see if the email node exists. --->
<cfif structKeyExists( contactNode, "email" )>
<!--- Get the email value. --->
<cfset data.email = contactNode.email.xmlText />
</cfif>
</cfif>
<!--- Check to see if the address node exists. --->
<cfif structKeyExists( partialData.xmlRoot, "address" )>
<!---
Get a short hand reference to the address node so that
our subsequent checks and retrievals are shorter and
easier to read.
--->
<cfset addressNode = partialData.xmlRoot.address />
<!--- Check to see if the first street node exists. --->
<cfif (
structKeyExists( addressNode, "street" ) &&
arrayLen( addressNode.street )
)>
<!--- Get the first street value. --->
<cfset data.street1 = addressNode.street[ 1 ].xmlText />
</cfif>
<!--- Check to see if the second street node exists. --->
<cfif (
structKeyExists( addressNode, "street" ) &&
(arrayLen( addressNode.street ) GTE 2)
)>
<!--- Get the second street value. --->
<cfset data.street2 = addressNode.street[ 2 ].xmlText />
</cfif>
<!--- Check to see if the company node exists. --->
<cfif structKeyExists( addressNode, "company" )>
<!--- Get the company value. --->
<cfset data.company = addressNode.company.xmlText />
</cfif>
<!--- Check to see if the city node exists. --->
<cfif structKeyExists( addressNode, "city" )>
<!--- Get the city value. --->
<cfset data.city = addressNode.city.xmlText />
</cfif>
<!--- Check to see if the state node exists. --->
<cfif structKeyExists( addressNode, "state" )>
<!--- Get the state value. --->
<cfset data.state = addressNode.state.xmlText />
</cfif>
<!--- Check to see if the zip node exists. --->
<cfif structKeyExists( addressNode, "zip" )>
<!--- Get the zip value. --->
<cfset data.zip = addressNode.zip.xmlText />
</cfif>
</cfif>
<!---
ASSERT: At this point, we have moved all possible target
nodes into our data structure.
--->
<!--- Insert the extracted XML data into our database. --->
<cfquery name="insertData" datasource="ben">
INSERT INTO partial_xml
(
name,
email,
street1,
street2,
company,
city,
state,
zip
) VALUES (
<cfqueryparam value="#data.name#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.email#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.street1#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.street2#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.company#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.city#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.state#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.zip#" cfsqltype="cf_sql_varchar" />
);
</cfquery>
As you can see, we start off with a default collection of data points. I like to start off this way because I tend to give everything a default value if it doesn't exist. If you need to have conditional inserts into your database based on the XML response, you can always start off with an empty data collection and then populate it with only the existing XML node values. Once the XML is extracted from the partial XML document, we move the centralized data collection into the database with a simple INSERT.
Gathering XML Data Using XmlSearchWithParam()
The code in the brute force method above is very easy to follow, but it's long. Of course, it has to be long because we need it to check for the existence of our target XML nodes. But, what if we didn't have to worry about XML node existence? Then, our code could be much shorter. In the first example, the default values were created first which meant we had to search out potential override values; in this next approach, I am building the concept of default values right into the data collection.
This solution uses a ColdFusion user defined function, XmlSearchWithParam(), which mimics the functionality of ColdFusion's XmlSearch() function, with the caveat that if no results are found, the method will populate the results array with a given default node value (or set of values). By using this function, rather than XmlSearch() directly, we know that our results array will always contain the type of target data we are seeking, even if it's not the actual data coming from the XML document:
<cffunction
name="xmlSearchWithParam"
access="public"
returntype="array"
output="false"
hint="I perform an XmlSearch() with the option to param the results with the given structure.">
<!--- Define arguments. --->
<cfargument
name="xmlDocument"
type="any"
required="true"
hint="I am the Xml document being searched."
/>
<cfargument
name="xpath"
type="string"
required="true"
hint="I am the XPath query to search with."
/>
<cfargument
name="defaultNode"
type="struct"
required="false"
default="#structNew()#"
hint="I am the default node to put in the xmlSearch() results if no target node is found."
/>
<cfargument
name="defaultCount"
type="numeric"
required="false"
default="1"
hint="I am the number of default nodes to be added to the results if no valid results are found (or not enough valid results are found)."
/>
<!--- Define the local scope. --->
<cfset local = {} />
<!--- Perform the xmlSearch() query. --->
<cfset local.nodes = xmlSearch(
arguments.xmlDocument,
arguments.xpath
) />
<!---
Check to see if we came up empty handed from the search
AND if there is a default node to use in place of any
valid search results.
--->
<cfif (
structCount( arguments.defaultNode ) &&
(
!arrayLen( local.nodes ) ||
(arrayLen( local.nodes ) lt arguments.defaultCount)
))>
<!---
Add as many default nodes to the array as requested
by the user. Be sure to duplicate the struct so we
don't create reference issues.
--->
<cfloop
index="local.defaultNodeIndex"
from="#(arrayLen( local.nodes ) + 1)#"
to="#arguments.defaultCount#"
step="1">
<!--- Use the default node as the only result. --->
<cfset arrayAppend(
local.nodes,
duplicate( arguments.defaultNode )
) />
</cfloop>
</cfif>
<!--- Return the collected nodes. --->
<cfreturn local.nodes />
</cffunction>
<!---
Create a structure that contains only one key - XmlValue.
When we search for our text nodes, this is a sub-set of
the structure that will be returned. We can use this to
param the results of our XmlSearch() call.
--->
<cfset defaultNode = {
xmlValue = ""
} />
<!---
Now that we have our default value, let's search for the
nodes in our partial XML document. I'm going to search for
each leaf node individually.
--->
<!--- Should return one match. --->
<cfset nameNodes = xmlSearchWithParam(
partialData,
"//contact/name/text()",
defaultNode
) />
<!--- Should return one match. --->
<cfset emailNodes = xmlSearchWithParam(
partialData,
"//contact/email/text()",
defaultNode
) />
<!--- Should return TWO matches. --->
<cfset streetNodes = xmlSearchWithParam(
partialData,
"//address/street/text()",
defaultNode,
2
) />
<!--- Should return one match. --->
<cfset companyNodes = xmlSearchWithParam(
partialData,
"//address/company/text()",
defaultNode
) />
<!--- Should return one match. --->
<cfset cityNodes = xmlSearchWithParam(
partialData,
"//address/city/text()",
defaultNode
) />
<!--- Should return one match. --->
<cfset stateNodes = xmlSearchWithParam(
partialData,
"//address/state/text()",
defaultNode
) />
<!--- Should return one match. --->
<cfset zipNodes = xmlSearchWithParam(
partialData,
"//address/zip/text()",
defaultNode
) />
<!---
Now that we have our search results, we can store the values
of the collected nodes into our data collection.
--->
<cfset data = {
name = nameNodes[ 1 ].xmlValue,
email = emailNodes[ 1 ].xmlValue,
street1 = streetNodes[ 1 ].xmlValue,
street2 = streetNodes[ 2 ].xmlValue,
company = companyNodes[ 1 ].xmlValue,
city = cityNodes[ 1 ].xmlValue,
state = stateNodes[ 1 ].xmlValue,
zip = zipNodes[ 1 ].xmlValue
} />
<!---
ASSERT: At this point, we have moved all possible target
nodes into our data structure.
--->
<!--- Insert the extracted XML data into our database. --->
<cfquery name="insertData" datasource="ben">
INSERT INTO partial_xml
(
name,
email,
street1,
street2,
company,
city,
state,
zip
) VALUES (
<cfqueryparam value="#data.name#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.email#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.street1#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.street2#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.company#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.city#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.state#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.zip#" cfsqltype="cf_sql_varchar" />
);
</cfquery>
As you can see, by ensuring that an XmlSearchWithParam() method call always returns a result set with the appropriate number of target nodes, when it comes time to moving the node values into our data collection, we don't have to do any node validation.
Paraming An Entire XML Document With XmlParam()
The above approach is a bit better; but, even excluding the XmlSearchWithParam() user defined function, which would be stored in some UDF library, the code is not that much shorter than our brute force method. And, on top of that, we are now forcing the programmer to use XPath, which is certainly an advanced level topic. Ideally, we want to use ColdFusion's named-node collections, which are much more intuitive than using XmlSearch(); but, we also don't want to have to worry about checking for node existence. In this last and final approach, I am using another ColdFusion user defined function, XmlParam(), to literally param our entire partial XML document.
If we know the structure of a complete XML document, we can use that structure to fill in the gaps in our partial XML response with default values. And, once we do that, we can then use the named-node collection notation to easily populate our data collection:
<cffunction
name="xmlParam"
access="public"
returntype="any"
output="false"
hint="I take a partial XML document and param it based on a complete XML document.">
<!--- Define arguments. --->
<cfargument
name="partialXmlDoc"
type="any"
required="true"
hint="I am the partial XML document that we are paraming."
/>
<cfargument
name="completeXmlDoc"
type="any"
required="true"
hint="I am the complete XML document against which the the partial XML document is being paramed."
/>
<!---
NOTE: Following arguments are optional if you want
to param an entire XML document. Use the following two
arguments if you only want to param part of an XML
document (specifically, the given node).
--->
<cfargument
name="partialXmlNode"
type="any"
required="false"
hint="I am the partial node being compared. Exclude this argument if you want to param the entire document."
/>
<cfargument
name="completeXmlNode"
type="any"
required="false"
hint="I am the complete node being compared. Exclude this argument if you want to param the entire document."
/>
<!--- Define the local scope. --->
<cfset var local = {} />
<!---
Make sure that we have XML nodes. If we don't then get
the root node of the given documents. If we do, then
either the user sent them in or we are in the middle of
a recursive comparison.
--->
<cfif !structKeyExists( arguments, "partialXmlNode" )>
<!---
Get Root nodes for both the partial XML document
and the completeXml document.
--->
<cfset arguments.partialXmlNode = arguments.partialXmlDoc.xmlRoot />
<cfset arguments.completeXmlNode = arguments.completeXmlDoc.xmlRoot />
</cfif>
<!---
Param the node attributes. Loop over the complete XML
node to move any non-existent attributes over to the
partial XML document.
--->
<cfloop
item="local.attribute"
collection="#arguments.completeXmlNode.xmlAttributes#">
<!---
Param the value in the partial document. Since we
are using CFParam, it will only be copied over if
it doesn't already exist.
--->
<cfparam
name="arguments.partialXmlNode.xmlAttributes[ '#local.attribute#' ]"
type="any"
default="#arguments.completeXmlNode.xmlAttributes[ local.attribute ]#"
/>
</cfloop>
<!---
Now, let's loop over the children to see if they match
up. This is a bit trickier since XML documents can be
so flexible. This is ONLY going to work with CERTAIN
types of XML documents (specifically those that have a
rigid structure and not so much for those that can
contain 1..N of a particular type of node - for that,
you have to param sub-documents).
--->
<cfloop
index="local.nodeIndex"
from="1"
to="#arrayLen( arguments.completeXmlNode.xmlChildren )#"
step="1">
<!--- Get a reference to the complete child node. --->
<cfset local.completeChildNode = arguments.completeXmlNode.xmlChildren[ local.nodeIndex ] />
<!---
Check to see if the partial XML document has enough
children to even check this against the complete
version of the node.
--->
<cfif (arrayLen( arguments.partialXmlNode.xmlChildren ) lt local.nodeIndex)>
<!---
The partial XML document doesn't even have a node
at this position. As such, we have to just copy
over the node from the complete Xml document.
--->
<cfset arrayAppend(
arguments.partialXmlNode.xmlChildren,
xmlElemNew(
arguments.partialXmlDoc,
local.completeChildNode.xmlName
)
) />
<!---
Now that we have appended the new child node,
get a short-hand reference to it.
--->
<cfset local.partialChildNode = arguments.partialXmlNode.xmlChildren[ local.nodeIndex ] />
<!--- Copy over the default text value. --->
<cfset local.partialChildNode.xmlText = local.completeChildNode.xmlText />
<!---
With the new node in place in the partial
document, we can now recursively move over the
rest of the complete sub-tree recursively.
--->
<cfset xmlParam(
arguments.partialXmlDoc,
arguments.completeXmlDoc,
local.partialChildNode,
local.completeChildNode
) />
<cfelse>
<!---
A node exists at this index in the partial XML
document. Now, we have to see if is the right
node to be at this index, or if we need to
create a new node.
--->
<!--- Get a refernce to the partial XML node. --->
<cfset local.partialChildNode = arguments.partialXmlNode.xmlChildren[ local.nodeIndex ] />
<!---
Check to see if this partial node is the same name
as the complete node. If they are, then we can
simply compare them. If they are not, however,
then we have to insert a new node.
--->
<cfif (local.partialChildNode.xmlName eq local.completeChildNode.xmlName)>
<!---
The node names are the same. Therefore, we can
simply compare them recursively.
--->
<cfset xmlParam(
arguments.partialXmlDoc,
arguments.completeXmlDoc,
local.partialChildNode,
local.completeChildNode
) />
<cfelse>
<!---
The node names are NOT the same. This means
that the given node is missing from the
partial xml document. We now have to create it
and then insert it.
--->
<cfset local.partialChildNode = xmlElemNew(
arguments.partialXmlDoc,
local.completeChildNode.xmlName
) />
<!--- Copy over the default text value. --->
<cfset local.partialChildNode.xmlText = local.completeChildNode.xmlText />
<!--- Insert the node at the given position. --->
<cfset arrayInsertAt(
arguments.partialXmlNode.xmlChildren,
local.nodeIndex,
local.partialChildNode
) />
<!---
Now that we have inserted the new node,
compare it to the target complete node.
NOTE: Because XML elements are inserted by
VALUE, we have to get the reference to our
taret child node again otherwise the changes
will not hold.
--->
<cfset xmlParam(
arguments.partialXmlDoc,
arguments.completeXmlDoc,
arguments.partialXmlNode.xmlChildren[ local.nodeIndex ],
local.completeChildNode
) />
</cfif>
</cfif>
</cfloop>
<!--- Return the updated partial XML document. --->
<cfreturn arguments.partialXmlDoc />
</cffunction>
<!---
Param the partial data response using the structure of our
known complete data XML repsonse.
--->
<cfset xmlParam( partialData, completeData ) />
<!---
ASSERT: At this point, our partial XML document structure is
the same as our complete XML document structure.
--->
<!---
Now that we have paramed our partial xml document to mimic our
complete xml document, we can use named-node collection
notation to store the node values into our data collection.
--->
<cfset data = {
name = partialData.xmlRoot.contact.name.xmlText,
email = partialData.xmlRoot.contact.email.xmlText,
street1 = partialData.xmlRoot.address.street[ 1 ].xmlText,
street2 = partialData.xmlRoot.address.street[ 2 ].xmlText,
company = partialData.xmlRoot.address.company.xmlText,
city = partialData.xmlRoot.address.city.xmlText,
state = partialData.xmlRoot.address.state.xmlText,
zip = partialData.xmlRoot.address.zip.xmlText
} />
<!---
ASSERT: At this point, we have moved all possible target
nodes into our data structure.
--->
<!--- Insert the extracted XML data into our database. --->
<cfquery name="insertData" datasource="ben">
INSERT INTO partial_xml
(
name,
email,
street1,
street2,
company,
city,
state,
zip
) VALUES (
<cfqueryparam value="#data.name#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.email#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.street1#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.street2#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.company#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.city#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.state#" cfsqltype="cf_sql_varchar" />,
<cfqueryparam value="#data.zip#" cfsqltype="cf_sql_varchar" />
);
</cfquery>
Ok, now granted that the code for XmlParam() is rather long - it's a complicated function. But, once we get past that function, which would be stored in a UDF library, the code for extracting the XML data is extremely small! Because we are ensuring that the partial XML document mimics the structure of the complete XML document, we can use our named-node collection without having to worry about any node existence checking. This is truly the best of all possible worlds.
The XmlParam() method is quite beasty and by no means easy to understand. As such, I want to run a small example just to show you how it alters the given XML document:
<!--- Dump out the partial document before we param it. --->
<cfdump
var="#partialData#"
label="Before XmlParam()"
/>
<!--- Param the document. --->
<cfset xmlParam( partialData, completeData ) />
<br />
<!--- Dump out the partial document after we param it. --->
<cfdump
var="#partialData#"
label="After XmlParam()"
/>
As you can see here, we are outputting the partial document, then paraming it with the complete document, and then outputting it again. Here is what we get:
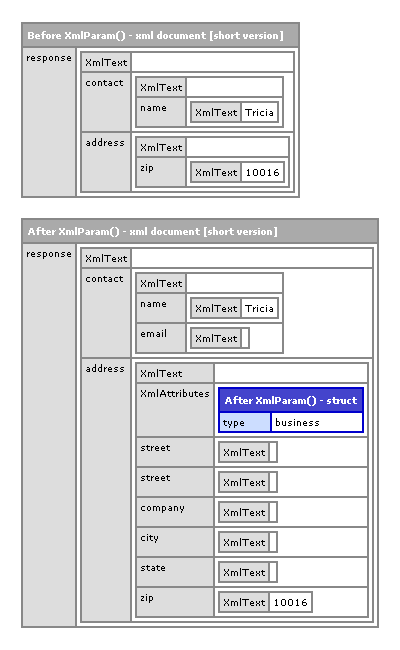
By passing the partial XML document to the XmlParam() method, we leave all the existing values in the partial document untouched; however, for every value in the complete XML document that does not also exist in the partial XML document, we copy it over. This way, we can move forward with the partial XML document assuming it has a complete structure.
These three methods are just some of the methods used for dealing with inconsistentt XML data in ColdFusion. Furthermore, they are designed to work only within certain boundaries; specifically, in situations where the XML data structure does not hugely alter the processing logic and in situations were default values can be easily assigned when target nodes are absent. That said, the above boundaries cover the majority of XML use cases that I have had to deal with. I hope this helps in some way. If you want to see any additional demo for a given use case, just let me know.
Want to use code from this post? Check out the license.

Reader Comments
Ben, your blog is always a great place to answer an that I have when I hit a dead end. Thank you for your contributions to use developers.
I used to think XPath had very little power and I have now been reformed; and I am better for it.