
Ask Ben: Extracting Data With Regular Expressions vs. ColdFusion List Functions
What im trying to do is i basically have a string "XXXX #YYYY **ZZZZZZZZZZ** 11111-0000". In that string i need to extract the text between the # and the ** so YYYY, then i need to extract the text between the ** (ZZZ.......), and then i need to extract the text between ** to the end (11111-0000). I was looking at the java regex and i couldnt put a # in my string without it bombing on me due to me having to escape it. Any assistance would be appreciated.
I am a HUGE fan of regular expressions. I think we all know that - they are the cat's pajamas! They are sexier than sexy! However, from time to time, regular expressions can be a bit overkill for a given job. For this particular problem, I think we might be able to solve it much more easily with a simple ColdFusion list function. So often, we think of lists in ColdFusion as being only comma-delimited strings. One of the most powerful aspects of ColdFusion list manipulation that often goes overlooked is the fact that lists can have multiple delimiters.
If you look at your test data and think about lists with multiple delimiters, you can start to see that what we have is sort of like a list that uses the space, the hash, and the star as delimiters. You might get thrown off by the fact that we have multiple delimiters in a row; but, remember the other most powerful aspect of list manipulation in ColdFusion is that it ignores empty characters (some people hate this, but it is an insanely useful feature for many situations)!
That said, let's break this string apart using a single ColdFusion ListToArray() call:
<!--- Create our test string. --->
<cfset strData = "XXXX ##YYYY **ZZZZZZZZZZ** 11111-0000" />
<!---
Break the list up into an array. When we view this list,
we are going to be using multiple delimiters. Since we
don't want to gather any spaces, hashes, or stars, we can
use all those as delimiters which will break out string
up exactly how we want.
--->
<cfset arrData = ListToArray(
strData,
" ##*"
) />
<!---
Dump out the array of data. You will see that each part
of the data is isolated to its own index of the newly
formed data array.
--->
<cfdump
var="#arrData#"
label="Multi-Delimiter ListToArray()"
/>
Running this code, we get the following output:
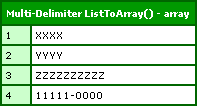
This works really well, but I also want to address the regular expression method since regular expressions are wicked powerful. If you are using ColdFusion 8, we can use the REMatch() method to accomplish the same thing as above. If we slightly alter our mentality and think about matching all characters that do not contain our list delimiters, we can easily break the string into the appropriate pattern matches:
<!--- Create our test string. --->
<cfset strData = "XXXX ##YYYY **ZZZZZZZZZZ** 11111-0000" />
<!---
Get all strings that do not include our "list" delimiters.
Like the ListToArray() method, this will break our string
up into the appropriate parts.
--->
<cfset arrData = REMatch(
"[^ ##*]+",
strData
) />
<!---
Dump out the array of pattern matches. You will see that
each part of the data is isolated to its own index of the
newly formed data array.
--->
<cfdump
var="#arrData#"
label="REMatch() Data"
/>
Running the above code, we get the following output:

As you can see, we get the same results.
OK, ColdFusion 8 is awesome; but, you did mention a Java regular expression, so I want to explore that method as well. Using a Java regular expression and the Pattern Matcher actually gives us the most amount of control since we can hand pick our capture groups. This method also gives us more flexibility in how the string is defined. We are going to use a regular expression to define the entire string in a single pattern. Then, as part of that pattern, we are going to capture the specific sub-strings into groups.
Because regular expressions are not meant to be read, I am going to define this using the verbose flag so I can really space it out for clarity. This will make the expression seem way bigger than it actually is, but hopefully you will be able to read AND understand it:
<!--- Create our test string. --->
<cfset strData = "XXXX ##YYYY **ZZZZZZZZZZ** 11111-0000" />
<!---
Create our pattern for matching this string. We are
going to create a pattern that will match the ENTIRE
test string; then, we are going to CAPTURE each target
substring into it's own group which can be retrieved via
the pattern matcher.
To help explain this, I am going to build the regular
expression in a string buffer and use the VERBOSE flag
so that we can break it up for readability.
--->
<cfsavecontent variable="strRegEx">
<!--- The VERBOSE flag. --->
(?x)
<!--- Match the start of the string. --->
^
<!---
The first group is all the characters that do NOT
include the first white space character.
--->
([^\s]+)
<!---
Our first "delimiter is the space and the hash
(escaped for ColdFusion CFOutput - not shown).
Because we are using VERBOSE regex, we need to
escape the hash sign (normally we wouldn't have to
do this).
--->
\s\##
<!---
Our next group is everthing until the next white
space character.
--->
([^\s]+)
<!---
Our second delimiter is space and two stars. Since
stars are special characters, we have to escape them.
--->
\s\*\*
<!---
Our next group is anything until the next star. Since
this is in a character group, we don't have to escape it.
--->
([^*]+)
<!--- Our third delimiters is two stars and a space. --->
\*\*\s
<!---
Our final value (group 4) is anything until the end
of the string.
--->
(.+)
<!--- Match the end of the string. --->
$
</cfsavecontent>
<!--- Compile our pattern. --->
<cfset objPattern = CreateObject(
"java",
"java.util.regex.Pattern"
).Compile(
JavaCast( "string", Trim( strRegEx ) )
)
/>
<!---
Get a pattern matcher that will scan our target string
for the given match and make the captured groups accessible
by group index.
--->
<cfset objMatcher = objPattern.Matcher(
JavaCast( "string", strData )
) />
<!--- Check to see if we found a match. --->
<cfif objMatcher.Find()>
<!--- We found a match, output the groups. --->
Group 1: #objMatcher.Group( JavaCast( "int", 1 ) )#<br />
Group 2: #objMatcher.Group( JavaCast( "int", 2 ) )#<br />
Group 3: #objMatcher.Group( JavaCast( "int", 3 ) )#<br />
Group 4: #objMatcher.Group( JavaCast( "int", 4 ) )#<br />
</cfif>
Running the above code, we get the following output:
Group 1: XXXX
Group 2: YYYY
Group 3: ZZZZZZZZZZ
Group 4: 11111-0000
If you think about it, using this method, we are sort of breaking apart the string like a CSV value. Pretty cool stuff.
So, three methods to solve the same problem. I hope one of these helps.
Want to use code from this post? Check out the license.

Reader Comments
hey Ben!
did you try to load test them anyhow to maybe see performance differences between them?
@Ed,
Hmm, My guess is that the ListToArray() would be the fastest.. but that's just a gut feeling. I think regex, as awesome as it is, is going to have a small amount of additional overhead; remember, the goal here is to match the string, not "not-match" it, which is where RegEx can be faster I think.
They're all gonna be wicked fast :)
I can't believe I've never heard of verbose regular expressions! Especially since a quick Googling turned up a post on your blog from January 2007. (Your Google mojo never fails to amaze me.)
You can't go wrong learning as much as possible about regular expressions. It is one of the most transferrable skills in information technology, as the syntax appears (with only small variations) in nearly every programming language you might be asked to learn.
@David,
Yeah, regular expressions are quite awesome. They help me in CF and Javascript! Truly cross-platform. The verbose flag is great for trying to make regular expressions as readable as possible. Let's face it - RegEx patterns are about the most unreadable things you can create; so, by given us the ability to break them down piece by piece and comment them, it sheds some light into their complexity.
The one caveat is that you have to be explicit about all your white space usage. Since verbose expressions ignore things like spaces and line breaks, you have to litterally use \s and the like to get them to match.
Also, # signs are "comments" in verbose mode, so you have to escape those if you want them to match.
Hope you don't mind me digging up this thread again Ben!? Some googling brought up this thread when trying to find a solution to my predicament. I'm basically wondering if it is at all possible to do this if the original string has just a single hashtag in it, (like the original question here)? I've tried any number of ways to do this, but no luck :(
The reason being Twitter and trying to divide up a tweet which (possibly) includes a single hashtag.
Can this be done in cfm or is it a no go?
@Sam,
If you are trying to link hashtags in a twitter message, you'd probably be better off with a regular expression than with any list functions. ColdFusion can definitely handle this. Probably something like:
rereplace(
message,
"\b##([^\b]+)",
"[a href='search_url?search=\1'>\1</a>",
"all"
)
... Obviously I don't know what the hashtag linking is, but I hope you get where I'm going with this.
@Ben,
sorry for bringin' up this thread after that much time, but I stumbled upon this one when googling for a way to extract parts of an URL from the current template. And thanks to your awesome code it finally worked! Thank you so much for your help in getting ColdFusion closer to the programmers world, Ben. You're the best!!!