
An Opinionated Guide To Handling Pull Requests (PRs) On My Team
On last week's Working Code podcast episode, I presented my strongly held beliefs about how Pull Requests (PRs) should be managed within a team setting. This is based on a decade of trial-and-error and an evolving understanding of git and GitHub that works well for me and my small team at InVision. Some of these opinions resonated with the podcast panel; others were flat-out rejected. Your mileage may vary.
First, a little context about my particular team:
I work on a small, tight-knit team of 4-engineers (including myself).
Between the 4 of us, there's close to 30-years of experience working at InVision.
While each of us leans more towards the front-end or the back-end - and, each of us has developed different specialties - all 4 of us would be considered "full stack" engineers.
For SOC compliance, all PRs must be reviewed by another individual. Beyond that, we have no additional regulations that we must follow (ie, we don't deal with financial information or other forms of data that require specialized compliance).
We use
gitand GitHub - I have no idea if or how my opinions apply to other types of source control mechanisms.We have no Quality Assurance (QA) engineers on our team - we are the first and last line of defense for our set of services.
We make heavy use of Feature Flags when building out new features in our application.
My team prides itself on being kick ass! This may have nothing to do with anything else that I say here; but, it is part of our team identity and may feed into how we conduct ourselves.
With that said, let's get to my opinionated guide! And, as you read through these, understand that they work as a cohesive set. Meaning, they are "True" together - they are not necessary "True" as individual items. What makes them meaningful is the fact that they work synergistically.
Code Completed is More Important Than Code Being Written
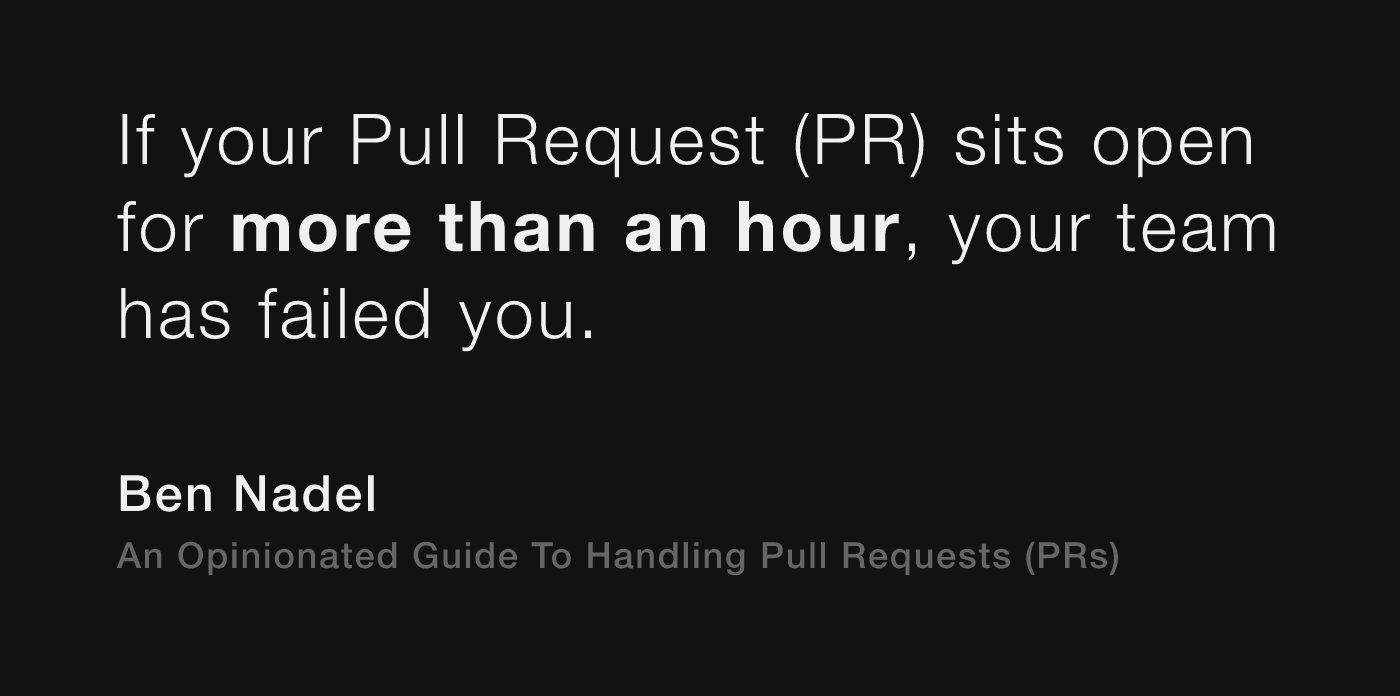
The entire "raison d'etre" of our application is to provide value for our customers. Which means, code completed is always more important than the code that is still being written since the completed code will be able to provide value sooner, not later. As such, the team must make it a priority to deploy code that is ready to be deployed; which means, making the reviewing of PRs a top priority.
To throw out an arbitrary number, so as to underscore the importance of the matter, if your PR sits open for more than an hour, your team has failed you.
Keep PRs Small
Your PRs should be kept as small as possible; but no smaller. To throw out an arbitrary number, so as to underscore the importance of the matter, if your PR takes more than 15-minutes to review, you have failed your team. You have failed to decompose a large problem into a set of smaller, independently deployable problems.
When you ask your team for a PR review, make sure to include the general size of the PR in the description. Example:
@hereI have a:pull-request:medium-sized PR to add a confirmation step to the widget deletion workflow -[link-to-PR]
If everyone else on the team is asking for "small PRs", and you're the one person that keeps asking for "large PRs", hopefully the social mores will eventually sink in and you'll figure out how to join the ranks of the "small PRs" club.
The "Cost of Context Switching" is a "Smell"
Engineers often tout the "cost of context switching" as the reason they shouldn't be interrupted for things like PR reviews. I even remember being explicitly warned at my first job that when a particular engineer had his headphones on, he was not to be interrupted under any circumstances. This is supposedly because us engineers are building these massive mental models in our heads; and to be interrupted would mean that all of that formulation and deep thinking gets flushed down the drain.
Yes this is true sometimes - when we are working on the early discovery phase of a very tough problem, it can be important to go "heads down" until you can see the path forward.
But, I would push back against the idea that this is the "normal state of being" for an engineer. If you can decompose your large problems down into a series of smaller problems, then the cost of context switching approaches zero. As such, if you have engineers who always seem to have a high cost of context switching, then they would probably benefit from some deliberate practice on their problem solving - and problem decomposition - skills.
ASIDE: My brain is terrible and my short-term memory is crap. I have to write everything down which is why I create like a dozen JIRA tickets a day. If it's not written down, I will forget it. And yet, I have no problem in switching contexts because I work on very small sub-problems. As such, "rebuilding" a mental model takes almost no effort.
All Team Members are Responsible for Reviewing PRs
Everyone on the team is responsible for helping out in PR reviews. As such, you should try to avoid pinging specific individuals and err on the side of pinging your whole team. This way, whom ever is available to jump on the PR will have the opportunity to do so.
At work, we use Slack; which means that PRs get announced in my private-team channel with an @here mention. Example:
@hereI have a:pull-request:tiny PR to add analytics to the widget UI -[link-to-PR]
As mentioned in the previous section, sometimes engineers do have to go "heads down". And by broadcasting the PR to your entire team with @here, you allow the "heads down" engineers to safely ignore the request with the understanding that someone else on the team will likely jump in and karate-chop it.
On my particular team, we denote a "claimed" PR by adding an :eyes: emoji to the PR request Slack message. This indicates that the PR is being handled and can be ignored by other engineers.
There should be no "on call" engineer that handles PR reviews. Doing so only furthers this idea that engineers should be uninterruptable.
And, of course, if there is an engineer that needs to be the one to review the PR due to a specialized skill-set, then feel free to ping that engineer. For example, if I have a security related ticket, I will usually ping our application security engineer (different team) specifically for a review.
What's in master / main Should Match What's in Production
Code should only ever be merged into your master / main branch when it is ready to be deployed. And, it should be deployed moments thereafter. You never want to have a divergence between what's in production and what's in master since this will make it very challenging to understand the state of the production system.
If you merge code into master and then walk away, you will cause an incident sooner or later. Not to mention the fact that you will make it very difficult for other engineers to debug an incident if they mistakenly assume that the master branch represents what's in production.
You Must Be Actively Involved With the Deployment of Your Code
Once your code has been merged into master / main and is about to be deployed, you must be actively involved with that deployment. Even if that doesn't mean that you're the one "pushing the button" (for various compliance reasons), you must be standing-by ready to confirm your work and review logs and metrics once the code hits production.
Never ever ever ever rely on any form of automation to monitor the deployment for you. Yes, those things are great; canary builds are great; automated roll-backs are great; but, you should never assume that they will work.
Always Review Your Own PR
The first person to review your PR should always be you! Looking at a PR is different than looking at code in an IDE - it forces your brain to work in a different way. As such, by looking at your own PR first, you're likely to spot quirks and catch issues that weren't apparent in your IDE. Make sure to do this before you ask anyone else to look at your PR.
ASIDE: This is akin to being in school where teachers recommend that you print our your reports and read them back on paper before you hand them in - just as with a PR, it forces your brain to consume the content in a different mode.
Always Review Comments Before You Merge Your PR Into master / main
Always look at the comments on your PR before you merge it into the master / main branch. Not all comments will block approval. Which means that a reviewer may approve a PR but also leave suggestions about things that might be changed or might merit deeper thinking. If a reviewer doesn't feel strongly enough about an issue, their primary goal is to facilitate code moving to production. They can therefore defer to the author of the code to determine if said issues are worthy of blocking the deployment; or, if said issues can be addresses in future tickets.
Alway Let People Know When Their PRs Have Been Reviewed
Just as an engineer pings the private team room when they have a PR to be reviewed, you should ping that engineer back when the PR has been approved (or has changes requested). Never assume that someone is sitting there watching the PR or is monitoring their email on the lookout for GitHub notifications. Assume that the engineer is frozen in time; and that the only way to unfreeze them is to notify them that their PR has been reviewed.
Large, Cross-Cutting Changes Should be in Their Own PR
PRs should be as small as possible. But, sometimes, PRs for cross-cutting concerns will be massive. Moving files around; changing linting rules; merging two code-bases together; these can all result in massive PRs. And, in those rare cases, those PRs should be managed and deployed independently of any other changes.
Never ever ever ever mix "cross-cutting changes" and "business logic changes" in the same PR. Doing so puts a massive cognitive load on the engineer that has to review that PR.
PRs Should Be Cohesive
In addition to being as small as possible, PRs should also be as cohesive as possible. Meaning, a PR shouldn't contain several unrelated changes; unless, of course, the point of the PR is something like, "a collection of small changes".
As much as possible, deploy all changes independently. This means that if any one PR ends up causing an incident, you don't have to "revert all the things" you just deployed together - you only have to revert the one, independent thing that caused the incident.
ASIDE: This is not meant to exclude superficial changes. For example, if you come across some "spelling mistakes" while working on an unrelated task, it is OK to include those spelling changes in the same PR. The point here is to follow the "intent" of the law, not the "letter" of the law.
Your Commit History Should Mirror the Evolution of the Application
Your git commit history should mirror the evolution of the application, not the journey of the engineer. Which means that all commit messages like:
WIPNot sure why this is breakingWTF is going on?!!?!?!More changesTrying something differentFUCK YOU CODE!!!!!!
... should be squashed before you create your PR. These types of commit messages are about you and your engineering journey, not about the application. They don't add clarity and they don't help explain why the application is the way it is. Don't let these commit messages become part of the permanent codebase.
That said, once someone has started reviewing your PR, subsequent changes made at the reviewer's request should be left as standalone commits. This way, the reviewer can see the limited-scope of what has changed since they last looked at your PR.
All PRs Should Be Associated With a Ticket / External Source of Truth
Regardless of what ticketing system or bug tracker you use, all PRs should be associated with an externalized source of truth. This way, when other engineers are looking at the code and want to understand why a change was made, they'll have a resource that they can refer to.
This is even true for middle-of-the-night hotfixes. If you are in a rush to deploy some emergency code, quickly create an empty ticket in your ticketing system and use that ticket number in your hotfix PR. Then, you can go back later and fill out the empty ticket when you have a moment to breathe.
On my team, we end all PR messages with this notation:
JIRA Ticket: RAIN-1234
... where RAIN-1234 is the unique ticket number on our JIRA board.
This also helps your managers do their job since they can look at the ticketing system - not the code - in order to understand what kinds of work is getting finished and deployed.
The Names of Your Branches Are Meaningless - Don't Over-Think It
The names of your git branches are meaningless. They should be meaningful enough to you, so that switching between branches is easy; but, you should never worry about whether or not anyone else understands what your branch names mean. If you want to create your own schema, like prefixing branch names with product/ or feature/ or bug/, then that's your business - do whatever works for you. But, never make your branch name schema someone else's problem.
ASIDE: Every ticketing system that I've used (which is admittedly only a handful) can pick the JIRA ticket number out of the PR message when creating associations between commits and tickets.
Expect Your PR Commit Message to be Consumed in a Git Blame
While every PR should reference an externalized source of truth, never assume that said source of truth will be around forever - teams change project management systems all the time. As such, you should treat your PR commit message as if it were the only source of information that future engineers will have. Use the PR commit message as an opportunity to tell a story about why a change is being made.
When Possible, Include a GIF / Screenshot / Video of UI Changes
Never assume that anyone is going to pull your code down and run in. As such, if your code changes the user interface (UI) in a meaningful way, try to include a screenshot, GIF, or even a short video of the changes. This will give the reviewer a nice picture of what the code is actually doing.
Delete Remote Branches After They've Been Merged
This is just common courtesy - delete your feature branches after they've been merged into your master / main branch. The GitHub UI makes this super easy - right after you merge your PR, a big "Delete Branch" button shows up in almost the same exact mouse location.
And, if you're not using the GitHub UI, you can always delete your remote branch with a push:
git push origin :my-branch
Your Reviewer is Not There to Ensure the Success of Your Code
The person who reviews your PR is not there to ensure the success of your code. Only you can do that. Your reviewer is there to help catch red flags and changes that may have not been fully considered. But, they are not there as the last line of defense. You should be just as confident in your code before you ask for a review as you are after your PR has been reviewed.
ASIDE: I am specifically referring to PRs are that ready to be deployed. I am not talking about the context in which a PR is created specifically for the purpose of having a deeper conversation with another engineer. Such PRs are merely a conversational starting-point and not a PR in the sense that this guide is addressing.
Don't Review a PR Until You're Asked To
As I mentioned in the last item, PRs get created for more than just a pre-deployment checkpoint. They can be created as the jumping-off point of a deeper conversation. And, they can be created simply as a means to see a clear side-by-side comparison of your own changes. As such, you should never review a PR until you (or your team) are explicitly asked to. The existence of a PR does mean that the code is ready to be reviewed.
Your Mileage May Vary
The items outlined in this guide have worked very well for my team in our particular context. They will likely not work in every context. I suggest that you take the items that may make sense for your team and just ignore the rest. And, if you want to hear this discussed by several people, check out our Working Code podcast episode 14.

Reader Comments
@All,
For anyone interested in how this plays into velocity, here's a post that speaks to that a bit:
www.bennadel.com/blog/4014-the-coldfusion-monolith-allows-my-team-to-move-fast-and-deploy-hella-often.htm
While not an apples-to-apples comparison of my team to other teams, I think this captures the fact that my team's strategies work very well for my team.