
Code Kata: Parsing Simple Timespan Strings Like 3h:12m:57s Using JavaScript
The other day, I was peer-reviewing some really cool static-asset processing pipeline stuff that Sean Roberts is building when something small caught my eye. He's allowing developers to define Cache-Control / Pragma settings using easy-to-read strings that get compiled-down into the necessary number of seconds used in the Amazon S3 object metadata. These timespan strings break-out days (d), hours (h), minutes (m), and seconds (s) into individual units so that the timespan is easy to consume at a glance. I thought it would be a fun code-kata to write the JavaScript Function that parses these timespan strings and calculates the total number of seconds that could eventually be used in the Cache-Control HTTP headers.
Run this demo in my JavaScript Demos project on GitHub.
View this code in my JavaScript Demos project on GitHub.
When I think about parsing a dynamic string into atomic chunks of information, of course my mind immediately goes to Regular Expressions. This is exactly the kind of task that Pattern Matching is built for. And, since the pattern we are trying to match is narrow in scope, the Regular Expression pattern is actually quite simple:
\d+(d|h|m|s)
This pattern will find one-or-more digits followed by one instance of a known-set of units (days, hours, minutes, seconds).
The above pattern will locate one atomic value; but, it says nothing about the input as a whole. So, at first, I was going to create another pattern that would validate the input itself. Something along the lines of:
^((\d+)(d|h|m|s))+$
This pattern uses the input delimiters (^) and ($) in order to ensure that the input string wholly contains groups that match the desired format (magnitude followed by unit).
But, then I got to thinking: why be so strict? One of my biggest gripes as a web-application consumer is when an input - like a Telephone number or a Birth date - is overly strict in its formatting requirements. When I'm not allowed to use spaces in a Telephone number, I find myself grimacing at the screen, flummoxed at the thought of a developer who has so little user empathy.
So, I started to consider all the ways in which a simple timespan may be formatted by different developers with different mindsets:
- 2d12h15m10s
- 2d 12h 15m 10s
- 2d,12h,15m,10s
- 2d-12h-15m-10s
- 2d:12h:15m:10s
- (2d)(12h)(15m)(10s)
- 2d..12h..15m..10s
- 2days 12hours 15minutes 10seconds
- 2d/ays 12h/ours 15m/inutes 10s/econds
- (2d)ays (12h)ours (15m)inutes (10s)econds
All of the above can be matched by the original atomic pattern so long as we don't try to validate the overall input string. So, let's not bother validating the overall input string - let's grant the developer the freedom to better express themselves and let's just look for patterns that match the magnitude-unit concept.
In general, I believe this approach is known as the "Robustness Principle":
Be conservative in what you do, be liberal in what you accept from others.
In this case, we are attempting to be liberal in what we accept as a timespan string because we want developers to use a format that they find most readable. Of course, this approach is not without trade-offs. By being liberal in our approach, we do open the door for subtle bugs. For example, what happens if a developer includes a magnitude without a unit:
1h30
The developer might think this is saying, "1-hour, 30-minutes". Or, they might think this is saying, "1-hour, 30-seconds". We don't know. We can't know. Our pattern-matching will only see "1h" as this is the only segment that contains both a magnitude and a discernible unit. So, if we don't validate the overall input, we can end-up calculating a timespan based on a "malformed" input.
The developer might also try to use units that aren't supported. For example, the developer might use "1y", thinking that "y" is "year". Or, "2w", thinking that "w" is "week". Such units would be skipped by our Regular Expression pattern.
It's just a trade-off: How strict do you want to be versus how usable do you want to be? And, of course, you can always add additional validation that makes sure various units match and that no number is used without a unit. There's no right answer, which is part of why this makes for such an interesting code kata.
With all that said, here's the simple version that I came up with:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>
Code Kata: Parsing Simple Timespan Strings Like 3h:12m:57s Using JavaScript
</title>
</head>
<body>
<h1>
Code Kata: Parsing Simple Timespan Strings Like 3h:12m:57s Using JavaScript
</h1>
<p>
<em>View the console for output...</em>
</p>
<script type="text/javascript">
// I parse a simple timespan string (ex, "12h,30m,17s") into a number of SECONDS.
// Supports the following units (must be lowercase):
// --
// * d = days
// * h = hours
// * m = minutes
// * s = seconds
// --
// Input may contain other delimiters, as desired, in order to make the input
// more readable by the developers.
function parseTimespan( input ) {
// CAUTION: On its own, this pattern does not require the input to only
// contain tokens that can be matched by this pattern. Depending on how hard
// you squint, this can be a good or bad thing.
var pattern = /(\d+)(d|h|m|s)/g;
var multiplier = {
d: 86400,
h: 3600,
m: 60,
s: 1
};
var timespan = 0;
var match;
// Apply each matched magnitude-unit combination to the running total.
while ( match = pattern.exec( input ) ) {
var magnitude = match[ 1 ];
var unit = match[ 2 ];
timespan += ( magnitude * multiplier[ unit ] );
}
return( timespan );
}
// --------------------------------------------------------------------------- //
// --------------------------------------------------------------------------- //
console.group( "Single Units" );
console.log( "2s =>", parseTimespan( "2s" ) );
console.log( "2m =>", parseTimespan( "2m" ) );
console.log( "2h =>", parseTimespan( "2h" ) );
console.log( "2d =>", parseTimespan( "2d" ) );
console.groupEnd();
// Notice that the parseTimespan() function doesn't care about how you format
// your input string; you could use spaces, commas, colons, etc. While this does
// open the door for subtle errors (of omission), it grants you the flexibility
// to choose a formatting option that sparks the most joy.
console.group( "Mixed Units" );
console.log( "1m2s =>", parseTimespan( "1m2s" ) );
console.log( "2s 1m =>", parseTimespan( "2s 1m" ) );
console.log( "3d..2h..16m..18s =>", parseTimespan( "3d..2h..16m..18s" ) );
console.log( "16m, 2h, 18s, 3d =>", parseTimespan( "16m, 2h, 18s, 3d" ) );
console.log( "10s:15s:20s =>", parseTimespan( "10s:15s:20s" ) );
console.groupEnd();
</script>
</body>
</html>
In this approach, I'm not really applying any validation at all (with the exception that the pattern is case-sensitive). I'm just looking for digits followed-by one character from a set of known units. I'm then looping over the matches and aggregating the number of calculated seconds. And, when we run this in the browser, we get the following output:
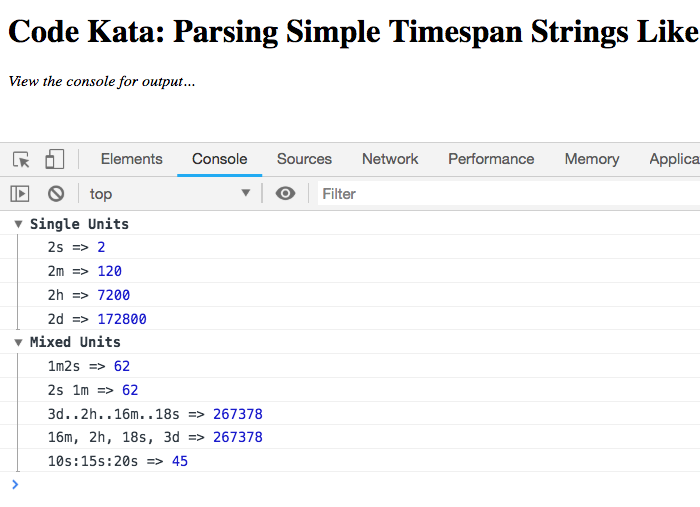
As you can see, by embracing the Robustness Principle, the developer is free to choose a formatting option that sparks the most joy.
To be honest, this code kata became a lot more philosophical than I expected it to become. At first, it was just going to be about Regular Expressions. But, that's the beautiful thing about deliberate practice. Hopefully you found this an interesting exploration.
Want to use code from this post? Check out the license.

Reader Comments