
Building A Circuit Breaker For Node.js
For the last few weeks, I've been trying to build a Circuit Breaker for Node.js. The core concept is based on the Circuit Breaker that I built for ColdFusion; but, given the fact that Node.js / JavaScript is a different language with a very different non-blocking paradigm, the code is similar in intent but different in execution. That said, I think I finally came up with something that is worth sharing.
- Github: https://github.com/bennadel/Node-Circuit-Breaker
- npm: https://www.npmjs.com/package/@bennadel/circuit-breaker
For this post, I'm essentially copying the contents of the currenty ReadMe file:
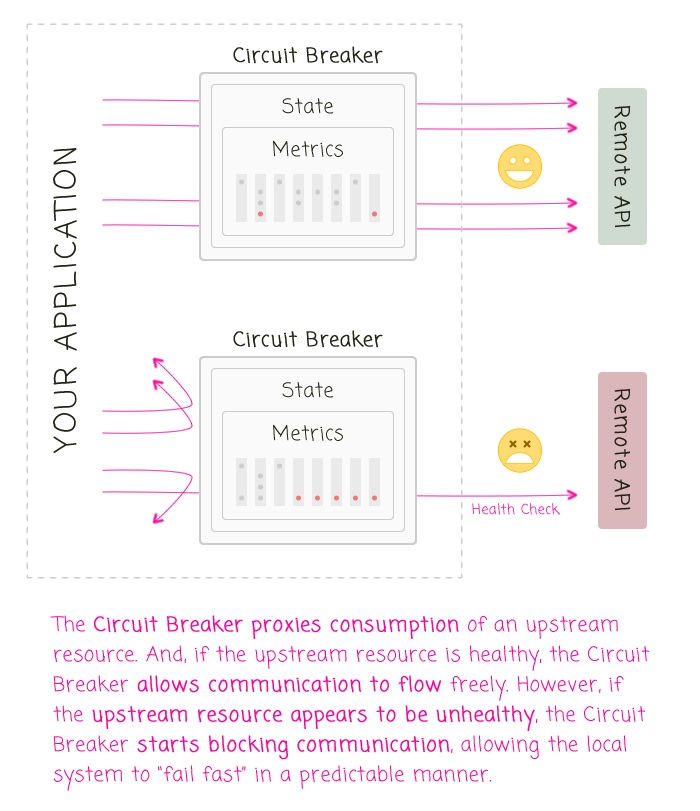
The Circuit Breaker is intended to proxy the consumption of upstream resources such that failures in the upstream resource propagate to the current system in a predictable manner. To be clear, the Circuit Breaker doesn't prevent failures; rather, it helps your application manage failures proactively, failing fast and / or providing fallback values when applicable.
The Circuit Breaker proxies the consumption of upstream resources; but, it does not have intimate knowledge of the upstream resource. As such, the scope of the Circuit Breaker can be as course or as granular as you think is appropriate. For example, you can have one Circuit Breaker that represents an entire upstream resource. Or, you can create an individual Circuit Breaker for each method in an upstream resource. The more granular your Circuit Breakers, the less likely you are to get false positives.
Default Usage
Each Circuit Breaker is a composition of several objects that work together to provide the tracking and the fail-fast functionality. Fortunately, you don't have to know about this unless you are building custom implementations. All you have to do is ask the Circuit Breaker Factory for an instance with the given settings.
The easiest way to create a Circuit Breaker is to create one with no settings at all. Doing so will create a Circuit Breaker with "good" defaults:
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var circuitBreaker = CircuitBreakerFactory.create();
// Invoke as closure.
circuitBreaker.execute(
function() {
return( upstreamResource.load() );
}
);
// Invoke as closure with context and arguments.
circuitBreaker.executeInContext(
upstreamResource,
function( param1, param2 ) {
return( this.load( param1, param2 ) );
},
[ "arg1", "arg2" ]
);
// Invoke as method on an object.
circuitBreaker.executeMethod( upstreamResource, "load", [ "arg1", "arg2" ] );
As you can see, there are three ways to run commands through a Circuit Breaker:
- execute( command [, fallback ] )
- executeInContext( context, command [, args [, fallback ] ] )
- executeMethod( context, methodName [, args [, fallback ] ] )
Each execute* method returns a Promise that will be fulfilled in resolution if the execution was successful; or, fulfilled in rejection if the execution threw an error (or was bypassed based on the state of the Circuit Breaker). The underlying method / function that is being invoked should return a Promise or a synchronous value. Or, it can omit a return if none is needed.
Configured Usage
The .create() method of the Circuit Breaker Factory works without any arguments; but,
you can provide a hash of settings that will be used to generate the Circuit Breaker.
Every one of the following settings is optional:
- id - The unique identifier of the underlying state instance, which is used for logging.
- requestTimeout - The time (in milliseconds) that a pending request is allowed to hang (ie, not complete) before being timed-out in error.
- volumeThreshold - The number of requests that have to be completed (within the rolling metrics window) before failure percentages can be calculated.
- failureThreshold - The percent (in whole numbers) of failures that can occur in the rolling metrics window before the state of the Circuit Breaker switches to opened.
- activeThreshold - The number of concurrent requests that can hang (ie, not complete) before the state of the Circuit Breaker switches to opened.
- isFailure - The function that determines if the given failure is an error; or, if it should be classified as a success (such as a 404 response).
- fallback - The global fallback to be used for all executions in the Circuit Breaker (which can be overridden locally with each execution).
- monitor - The monitor - Function or instance - for external logging (ex, StatsD logging).
- bucketCount - The number of buckets to be used to collect rolling stats in the rolling metrics window.
- bucketDuration - The duration (in milliseconds) of each bucket within the rolling metrics window.
NOTE: The duration of the rolling metrics window will be (bucketCount * bucketDuration). This is also the amount of time that the Circuit Breaker will remain opened after failing before allowing a "health check" request to execute.
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var circuitBreaker = CircuitBreakerFactory.create({
id: "Remote API",
requestTimeout: 5000,
volumeThreshold: 10,
failureThreshold: 10, // Percent (as in 1 failure in 10 responses trips the circuit).
activeThreshold: 50,
isFailure: function( error ) {
return( ! is404( error ) );
},
fallback: { /* Fallback value. */ },
monitor: function( eventType, eventData ) {
console.log( eventType, eventData );
},
bucketCount: 30,
bucketDuration: 1000
});
Fallback Values
The primary goal of the Circuit Breaker is to "fail fast" if the upstream resource appears to be unhealthy. However, the secondary goal of the Circuit Breaker is to provide a better user experience. That means that if a meaningful fallback value can be provided in the case of error, the Circuit Breaker will facilitate this approach.
The fallback value can be a Function, a Promise, or any static value. If it's a Function, it should return either a Promise or a static value. Fallback values can be defined when the Circuit Breaker is created:
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var circuitBreaker = CircuitBreakerFactory.create({
id: "Remote API",
fallback: { /* Fallback value. */ }
});
But, they can also be provided at the time of execution (regardless of whether or not a global fallback value was provided):
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var circuitBreaker = CircuitBreakerFactory.create({
id: "Remote API",
fallback: { /* Fallback value. */ }
});
circuitBreaker
.execute(
function() {
throw( new Error( "Network Error" ) );
},
{ /* Local fallback value. */ }
)
.then(
function( result ) {
console.log( result ); // Will be LOCAL fallback value.
}
)
;
If the fallback value is a Function and the execution was provided with a context and arguments, the same context and arguments will be used to invoke the Fallback.
Circuit Breakers Are Scary - What If I Get It Wrong?
To be honest, it can be scary - the idea of putting something into production that will purposefully block calls to proxied systems. If you pick an error threshold that's too low, you may start blocking requests too quickly. If you pick an active threshold that's too high, you may clobber the upstream resource.
Luckily, you don't have to dive right into the deep-end. Instead, you can deploy a passive Circuit Breaker that will log all of the traffic; but, will never fail open, no matter how unhealthy the upstream resource becomes. This way, you can spend some time passively gathering metrics about your API usage (including counts, durations, and errors) before switching over to an active Circuit Breaker with tailored settings.
Since this is a passive Circuit Breaker (that never opens), there are fewer settings:
- id - The unique identifier of the underlying state instance, which is used for logging.
- isFailure - The function that determines if the given failure is an error; or, if it should be classified as a success (such as a 404 response).
- fallback - The global fallback to be used for all executions in the Circuit Breaker (which can be overridden locally with each execution).
- monitor - The monitor - Function or instance - for external logging (ex, StatsD logging).
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var circuitBreaker = CircuitBreakerFactory.createPassive({
id: "Remote API",
monitor: function logEvent( eventType, eventData ) {
// Log statsD metrics about count and duration.
// Log errors.
}
});
// This error will result in a rejected promise; but, the Circuit Breaker will always
// remain closed, allowing requests to be executed.
circuitBreaker.execute(
function() {
throw( new Error( "Network Error" ) );
}
);
Once you've had a chance to monitor your Circuit Breakers, you can start switching your .createPassive() factory calls with .create() factory calls using settings that you know correspond to the collected base-line of metrics. And, you can sleep well at night.
Logging And Monitoring
By default, the Circuit Breaker quietly discards all internal events. However, you will probably want to log Errors and record StatsD metrics in your application. To do this, you can provide a logging Function as the monitor argument:
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var circuitBreaker = CircuitBreakerFactory.create({
id: "Remote API",
monitor: function logEvent( eventType, eventData ) {
console.log( eventType, eventData );
}
});
This logging Function will be called with the following eventTypevalues:
- closed passing eventData properties { stateSnapshot }
- execute passing eventData properties { stateSnapshot }
- emit passing eventData properties { stateSnapshot }
- failure passing eventData properties { stateSnapshot, duration, error }
- fallbackEmit passing eventData properties { stateSnapshot }
- fallbackFailure passing eventData properties { stateSnapshot, error }
- fallbackMissing passing eventData properties { stateSnapshot }
- fallbackSuccess passing eventData properties { stateSnapshot }
- opened passing eventData properties { stateSnapshot }
- shortCircuited passing eventData properties { stateSnapshot, error }
- success passing eventData properties { stateSnapshot, duration }
- timeout passing eventData properties { stateSnapshot, duration, error }
Under the hood, this is actually using your logEvent() Function to complete a concrete implementation of the AbstractLoggingMonitor. If you don't provide a Function, you can provide a Class that extends either the Monitor class or the AbstractLoggingMonitor class. If you extend the AbstractLoggingMonitor base class, you only have to override the logEvent() method:
var AbstractLoggingMonitor = require( "@bennadel/circuit-breaker" ).AbstractLoggingMonitor;
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
class MyMonitor extends AbstractLoggingMonitor {
constructor( statsD ) {
super();
this._statsD = statsD;
}
logEvent( eventType, eventData ) {
stats.increment( `circuit-breaker.${ eventType }` );
}
}
// ....
var circuitBreaker = CircuitBreakerFactory.create({
id: "Remote API",
monitor: new MyMonitor( stats )
});
However, if you extend the Monitor class, you can override any of the log* methods:
var CircuitBreakerFactory = require( "@bennadel/circuit-breaker" ).CircuitBreakerFactory;
var Monitor = require( "@bennadel/circuit-breaker" ).Monitor;
class MyMonitor extends Monitor {
logClosed( stateSnapshot ) {
/* ... */
}
logOpened( stateSnapshot ) {
/* ... */
}
}
// ....
var circuitBreaker = CircuitBreakerFactory.create({
id: "Remote API",
monitor: new MyMonitor()
});
The Monitor class provides the following default, no-op (No Operation) methods, which means you only have to override the ones that are meaningful to your application:
- logClosed( stateSnapshot ) -- I log the point at which the Circuit Breaker state moves from opened to closed.
- logExecute( stateSnapshot ) -- I log the point at which the execution is accepted by the state of the Circuit Breaker and the underlying command is about to be invoked.
- logEmit( stateSnapshot ) -- I log the point at which the request has entered the Circuit Breaker but has not yet been approved for execution.
- logFailure( stateSnapshot, duration, error ) -- I log the point at which the execution has ended in error. This only accounts for non-Circuit Breaker errors (see, logTimeout() and logShortCircuited() events).
- logFallbackEmit( stateSnapshot ) -- I log the point at which a non-successful execution (due to error, timeout, or short-circuiting) is being evaluated for a fallback response.
- logFallbackFailure( stateSnapshot, error ) -- I log the point at which an existing fallback function resolved in error.
- logFallbackMissing( stateSnapshot ) -- I log the point at which a failed execution has no fallback defined.
- logFallbackSuccess( stateSnapshot ) -- I log the point at which a fallback value has successfully stood-in for a failed or bypassed execution.
- logOpened( stateSnapshot ) -- I log the point at which the Circuit Breaker state moves from closed to opened.
- logShortCircuited( stateSnapshot, error ) -- I log the point at which an execution is bypassed because the Circuit Breaker is currently in an opened state.
- logSuccess( stateSnapshot, duration ) -- I log the point at which an execution has resolved successfully.
- logTimeout( stateSnapshot, duration, error ) -- I log the point at which a long-running execution has been explicitly timed-out in error.
The stateSnapshot object passed to the Monitor methods (and to the AbstractLoggingMonitor logEvent() method) contains identification and metric information about the State being used to power the Circuit Breaker. Since one Circuit Breaker can share state with another Circuit Breaker, there's not too much sense in identifying the Circuit Breakers themselves; as such, the State becomes the meaningful information for logging and monitoring. Each stateSnapshot provided by the default implementation uses the following structure:
{
"id": "Circuit Breaker for API",
"closed": true,
"settings": {
"requestTimeout": 0,
"volumeThreshold": 0,
"failureThreshold": 0,
"activeThreshold": 0
},
"metrics": {
"emit": 0,
"execute": 0,
"success": 0,
"failure": 0,
"timeout": 0
},
"totalMetrics": {
"emit": 0,
"execute": 0,
"success": 0,
"failure": 0,
"timeout": 0
},
"current": {
"activeRequestCount": 0
}
}
Building Your Own State Implementation
The Circuit Breaker is designed to be a composite of several different classes all working together to accomplish one goal. The reason for this composition was to allow custom implementations to be designed if desired. Ideally, if you want a custom implementation, the only class you should have to provide is the State class. The CircuitBreaker class manages the control-flow; but, it uses the State implementation to power that control-flow. If you want to provide your own State implementation, you have to provide a class that exposes the following methods:
- canPerformHealthCheck()
- getSnapshot()
- isOpened()
- isClosed()
- getTimeout()
- trackExecute()
- trackEmit()
- trackFailure( duration, error )
- trackFallbackEmit()
- trackFallbackFailure( error )
- trackFallbackMissing()
- trackFallbackSuccess()
- trackShortCircuited( error )
- trackSuccess( duration )
- trackTimeout( duration, error )
What you do inside these methods is completely up to you. But, they have to exist since the CircuitBreaker is going to call them. The general control-flow for the CircuitBreaker follows this plan:
-> Top-level execute*() method is called.
-> Call trackEmit().
-> Check to see if isOpened().
-> If opened:
---> Check to see if canPerformHealthCheck()
-----> If can perform health check, proceed to execution.
-> If can execute command:
---> Call trackExecute().
---> Setup timeout timer using getTimeout().
---> Invoke underlying command.
-> On resolution:
---> Call trackSuccess().
-> On rejection:
---> Check type of error:
-----> If OpenError call trackShortCircuited().
-----> If TimeoutError call trackTimeout().
-----> Otherwise call trackFailure().
---> Call trackFallbackEmit().
---> Check to see if a fallback was provided (locally or globally).
-----> If fallback was provided:
-------> Execute fallback.
-------> On resolution:
---------> Call trackFallbackSuccess().
-------> On rejection:
---------> Call trackFallbackFailure().
-----> If no fallback was provided:
-------> Call trackFallbackMissing().
Once you have a custom State implementation, you can construct a CircuitBreaker:
var CircuitBreaker = require( "@bennadel/circuit-breaker" ).CircuitBreaker;
var state = new CustomStateImplementation();
var circuitBreaker = new CircuitBreaker( state [, globalFallback] );
Guarantees Around Synchronous State Tracking
Since the Circuit Breaker generates and returns Promises around the execution of black-boxed commands, many of the methods on the State instance will be invoked asynchronously. However, the following series of methods are guaranteed to be invoked synchronously within the same tick of the Node.js event loop:
- trackEmit()
- isOpened()
- canPerformHealthCheck() - called only if isOpened() returns true.
- trackExecute()
Since Node.js runs in a single process, you can assume that these four methods will be called without any race conditions.
All Metrics Should Be Stored In-Memory
If you are building your own State implementation, you may be tempted to share metrics across different Node.js processes (or machines). For example, you may be tempted to store metrics in a shared Redis instance that can be consumed be every instance of a Circuit Breaker that proxies a single resource. DO NOT DO THIS. Not only does the Circuit Breaker expect State methods to run synchronously; but, trying to share state offers no real value-add. Since the failure-tracking is based on percentages, sharing state won't make the percentages more accurate. In fact, sharing state across processes could lead to false-positives if a particular process or machine is having issues (such as configuration issues that don't affect other processes or machines).
Package Exports
This Circuit Breaker package exports the following public members:
- OpenError
- StateError
- TimeoutError
- Metrics
- AbstractLoggingMonitor
- Monitor
- State
- CircuitBreaker
- CircuitBreakerFactory
Anyway, this was a lot of fun to build. Hopefully, I'll get to try it out in production. If nothing else, this was a wonderful code-kata - it really made me think more deeply about code composition and separation of concerns. Also, this is the most unit-testing I have ever done!
Want to use code from this post? Check out the license.

Reader Comments
@All,
So, while I was researching node.js circuit breakers, I kept coming across the following line of code (in various implementations):
timeout.unref();
.... I had never seen it before. But, seeing it over and over made me think it was maybe a "best practice." But, the more I think about it, the more I think it makes no sense in a Circuit Breaker context:
www.bennadel.com/blog/3301-calling-timeout-unref-with-settimeout-does-not-appear-to-be-a-best-practice-in-node-js.htm
... the more I noodle on it, the more I think it should be the exception and not the rule.