
Putting DEBUG Comments In Your SQL Statements Makes Debugging Performance Problems Easier
I freakin' love SQL. And, I freakin' love relational databases. But, as everyone knows, database operations can become a significant bottleneck in the performance for your web application, especially as it scales. At InVision App, part of my job is to monitor our database performance, identify problematic queries, and think about ways to make them faster (often by making them simpler). And, to make that job easier, I've gotten into the habit of including "DEBUG" statements at the top of all of my SQL queries.
A DEBUG statement is not magic. It's nothing more than a SQL comment that helps identify where the given query is being run from. This way, when that query shows up in the PROCESSLIST or the SLOW_LOG or in FusionReactor monitoring or the New Relic monitoring, it doesn't take more than a quick glance to be able to identify the query in the context of the overall application.
To see what I mean, here's a query with a DEBUG statement that I would use. Notice that the DEBUG statement includes both the component name and the method name that was used to initiate the query:
SET @userID = 1;
/* DEBUG: userGateway.getCurrentFriends(). */
SELECT
u.id,
u.name,
u.email
FROM
user uSource
INNER JOIN
friendship f
ON
(
uSource.id = @userID
AND
f.userID = uSource.id
AND
f.endedAt IS NULL
)
INNER JOIN
user u
ON
u.id = f.friendID
ORDER BY
f.startedAt ASC
;
While this does mean that you are sending more data over the wire to the database, the cost is trivial and the benefit is enormous. If this query were to start showing up in the SLOW_LOG, for example, it would be simple to identify:
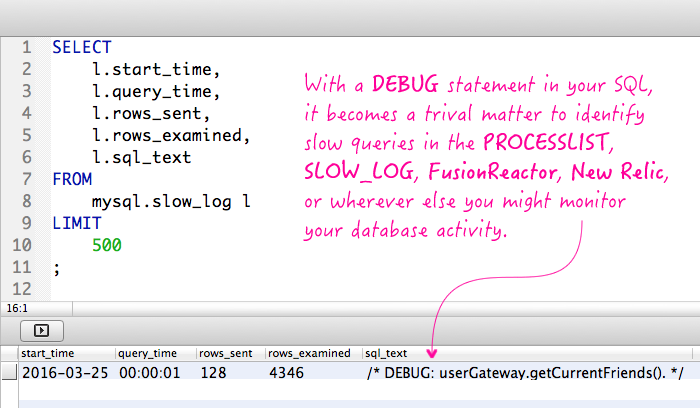
As you can see, without even seeing the entire SQL statement, I can already tell you that this slow query was being initiated by the UserGateway component via the method getCurrentFriends(). Now, I just need to go explore that code and see if there are ways to optimize the query or refactor the workflow to get better performance.
Honestly, I can't imagine writing SQL any other way at this point. Having these DEBUG statements come through in all the monitoring has made my life so much easier.
Want to use code from this post? Check out the license.

Reader Comments
On Twitter, Todd Rafferty (@webRat) asked me about SQL injection and use of SET. My bad for not explaining this part of the code. In ColdFusion, behind the scenes, I actually use CFQueryParam to protect against SQL injection. The reason that I used SET in this particular code demo was because I wanted to demonstrate that the DEBUG comment needs to come right before the SELECT.
My guess / assumption is that query parser associates the comment with the next statement. So, if I were to include the DEBUG statement before the SET:
/* DEBUG: .... */
SET ....
SELECT ....
... then the DEBUG statement won't actually show up in the logs.
You can see this same behavior if you have a CFQuery that has a temp table before the final SELECT - the comment won't show up unless the actual temp table population is what is "slow".
So, long story short, the take away is that the DEBUG comment has to be immediately before the part of the query you want to isolate in the logs. In this case, I didn't care about the SET, only the SELECT. So, I put the comment after the SET but before the SELECT.
Thanks for the clarification. :)
@Todd,
Always a pleasure, good sir.
I use an md5 hash of the query for the same reason.
@Curt,
Can you expand on that a bit more? I'm not familiar with hashing queries (though I know it's something you can do in Redis - create hashes of functions that can be run on the server).
A downside is that if you use the same query, but with a different "DEBUG" comment, you'll create a different plan cache and possibly a different execution plan with each different command - which could create memory issues. I wish SQL Server would strip out comments before analyzing, but it doesn't. I'm currently researching putting the caller info in the connection string Application Name field, but I'm looking into if that would affect connection pooling (most likely).
@Shawn,
That's a really excellent point to bring up! With a debug comment, it can be tempting to put argument info into the comment itself. Something like:
/* DEBUG: getData( ${ id } ). */
... where "${ id }" is whatever interpolation is used by your particular programming language. But, as you point out, using a different comment *technically* makes it an entirely different query which means that it gets its own query cache which will defeat the purpose of parameterized queries to being with.
Great tip!
@Ben,
I literally just paste the query, cfqueryparams and all, into http://www.miraclesalad.com/webtools/md5.php and put the resulting hash in the query as a comment.
@Curt,
Interesting. So, to be clear, you MD5-hash the query and then add the hash as a comment? Like:
/* b7df0038dfee8...... */
@Ben,
I put a copy of the query into a md5 hash generator such as http://www.miraclesalad.com/webtools/md5.php . I then put the hash at the top of the query in a comment just like you have done so I can easily search the codebase for that particular hash if needed.