
Redis Doesn't Store Empty Sets Or Hashes (And Will Delete Empty Sets And Hashes)
Since Sunday night, I've been battling Redis (like a boss). There's nothing wrong with Redis itself - the problem was in our code; but, the solution involved writing a migration script that scans over tens of millions of keys looking for specific ones to delete (based on corresponding keys). As I was writing this migration script, I discovered something unexpected about Redis: it doesn't store empty sets or empty hashes. And, furthermore, it will delete a set or a hash at the time the last member or key is removed, respectively. While this isn't necessarily a bad thing, if you don't know that this happens, it can lead to expected behavior if you are providing your keys with a TTL (time to live).
First, let's demonstrate that empty sets and empty hashes are automatically purged from the Redis store. In the following terminal, I'm going to look at the existence of a set:

As you can see, the set exists until the last member is removed. At that point, the "type" command returns "none" and the "exists" command confirms that the key has actually been removed from the store.
The same thing can be demonstrated with a hash:
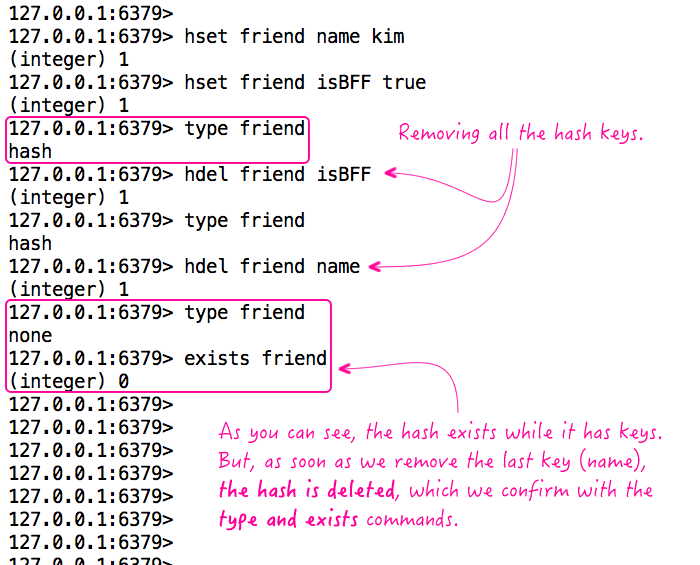
As you can see, the hash exists until the last key is removed. At that point, the "type" command returns "none" and the "exists" command confirms that the key has actually been removed from the store.
Now, in the vast majority of cases, this behavior is totally fine because a non-existent set or hash basically acts like an empty set or hash. Meaning, if you were to ask for the cardinality (set size) of a non-existent set, for example, Redis returns zero instead of throwing an error:
127.0.0.1:6379> scard my-non-existent-set
(integer) 0
127.0.0.1:6379> hlen my-non-existent-hash
(integer) 0
Which is cool.
But, the real edge-case with this behavior, at least in my mind, is when TTL (time to live) comes into play. Imagine that you have a set with a TTL on it. As you are adding and removing members, you may inadvertently delete the set. And, when that happens, the existing TTL is lost. Then, when new members are added to the set, the just-in-time set is created without a TTL.
This is easy to demonstrate:
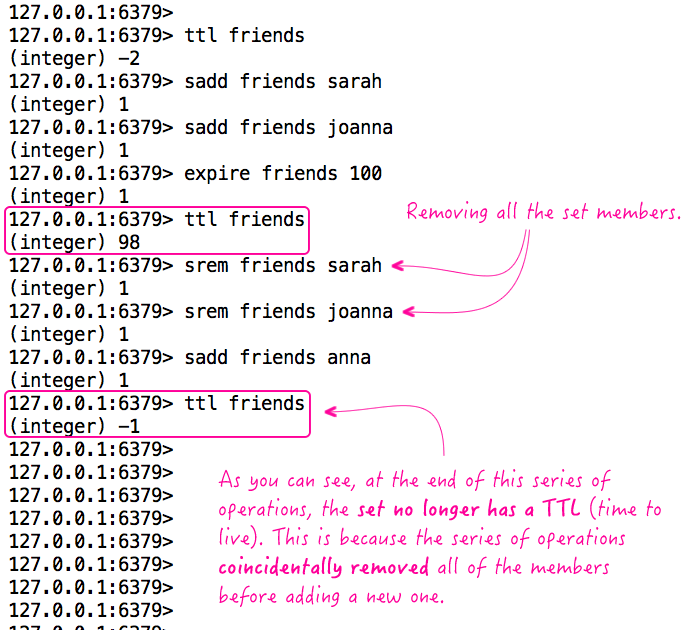
As you can see, we start out with a TTL (time to live) on the set. However, during our series of operations, we coincidentally remove all of the set members before we add the newer ones. And, when we remove the last member, the set - along with its existing TTL - is deleted. At this point, any new members will precipitate the creation of a new set (on the fly) without a TTL.
NOTE: This behavior is true even if you are executing all of this inside a MULTI / EXEC transaction block.
I don't necessarily consider this buggy behavior. I assume this approach is beneficial for memory management. However, I do think that this behavior can be surprising, especially since the fact that deleting empty sets and hashes isn't well articulated in the Redis documentation (at least not with the relevant commands). So, just keep this in the back of your mind when you're using Redis.
Want to use code from this post? Check out the license.

Reader Comments
Indeed! That's how Redis work, nice explanation for new comers, will definitely share it in our next RedisWeekly Ben!
@Redsmin,
Once you realize that it works this way, it's actually quite nice. Though, if you don't know that it works this way, it seems awkward and inconsistent. My only real gripe with the feature was that it didn't seem documented.
What if I want to cache the fact that a collection is empty, without creating a new key to do so? In my case...
if(Key does not exist) { hit db; cache results; }
If the db results are empty, it hits the db every time for the objects with empty result sets.
@Planecrash,
Hmm, well, the good thing is that, from a Redis perspective, there's little difference between an "empty set" and a "non-existing set". Meaning, if you try do something like call:
redis-cli> smembers foo
(empty list or set)
redis-cli> sscan foo 0
1) "0"
2) (empty list or set)
redis-cli> scard foo
(integer) 0
... so, the non-existing key, "foo" looks and acts like an empty set when you try to query it. As such, you can treat them both in the same way.
Does that help at all?
@Planecrash,
Also, if you truly wanted to know whether or not the key existed, you could both check the existence and get the set in the same multi-transaction:
redis-cli> MULTI
OK
redis-cli> exists foo
QUEUED
redis-cli> smembers foo
QUEUED
redis-cli> EXEC
1) (integer) 0
2) (empty list or set)
... here the EXEC returns an Array of results. The first item indicates that the key did NOT exist, and the second item contains the members of the set (which appears to be empty).