
Finding HTML Comment Nodes In The DOM Using TreeWalker
The other day, I blogged about my jQuery plugin that facilitates searching the DOM (Document Object Model) for Comment nodes based on pseudo attributes. While I was writing that plugin, I came across a relatively new JavaScript API, the TreeWalker. The TreeWalker provides an iteration interface for easily traversing specific components of the DOM tree. Given the fact that comments cannot be found with normal CSS selectors, I wanted to see if I could use the TreeWalker as a comment-query optimization.
To be clear, the TreeWalker can iterate over any kind of (or combination of) DOM nodes. But, Comment nodes seem like the most interesting topic since they cannot be easily targeted through other means (hence my jQuery plugin).
When you instantiate a TreeWalker, you give it the root node (within which to search) and the type of nodes that you want to find - in this case, comments. You can also pass-in an optional filter that will allow you to skip (or reject) nodes in the iteration process. There is some cross-browser funkiness in the way the filtering is defined; but, it's rather easy to overcome.
IE (Internet Explorer) expects a filter function to be defined. Other browsers expect an object that contains an "acceptNode" method. To overcome this, we can simply define the filter function as a member of itself. Remember, in JavaScript, Functions are just objects that can be invoked. And, like all objects in JavaScript, Functions can have properties.
So, for cross browser support, we just define a reference to the filter function on itself:
filter.acceptNode = filter;
In this way, "filter" is both an object and a function.
To see this in action, I'm going to search the DOM for comments; then, for each comment that I find, I'm going to insert a Paragraph element with the same text value. Notice that I'm skipping the last comment in the DOM:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>
Finding Comment Nodes In The DOM Using TreeWalker
</title>
</head>
<body>
<h1>
Finding Comment Nodes In The DOM Using TreeWalker
</h1>
<!-- Comment 1: In the Body. -->
<div>
<!-- Comment 2: In a nested Div. -->
<div>
<!-- Comment 3: In a double-nested Div. -->
</div>
</div>
<!-- Comment 4: Back up in that Body. -->
<!-- Load scripts. -->
<script type="text/javascript" src="../../vendor/jquery/jquery-2.0.3.min.js"></script>
<script type="text/javascript">
if ( ! document.createTreeWalker ) {
throw( new Error( "Browser does not support createTreeWalker()." ) );
}
// By default, the TreeWalker will show all of the matching DOM nodes that it
// finds. However, we can use an optional "filter" method that will inform the
// DOM traversal.
function filter( node ) {
if ( node.nodeValue === " Load scripts. " ) {
return( NodeFilter.FILTER_SKIP );
}
return( NodeFilter.FILTER_ACCEPT );
}
// IE and other browsers differ in how the filter method is passed into the
// TreeWalker. Mozilla takes an object with an "acceptNode" key. IE takes the
// filter method directly. To work around this difference, we will define the
// acceptNode function a property of itself.
filter.acceptNode = filter;
// NOTE: The last argument [] is a deprecated, optional parameter. However, in
// IE, the argument is not optional and therefore must be included.
var treeWalker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_COMMENT,
filter,
false
);
// For each comment node, add a
while ( treeWalker.nextNode() ) {
$( "<p></p>" )
.text( treeWalker.currentNode.nodeValue )
.insertAfter( treeWalker.currentNode )
;
}
</script>
</body>
</html>
When we run this code, we get the following page output:
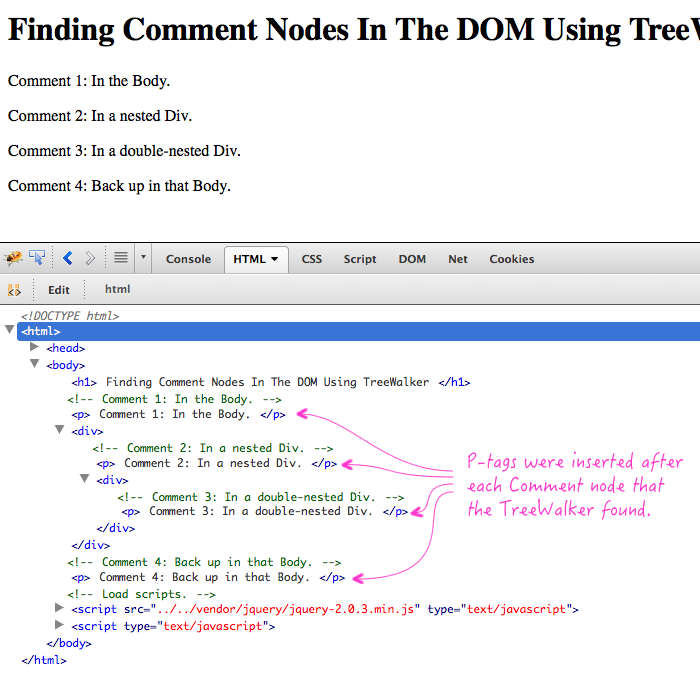
As you can see, we were able to locate each Comment node using the TreeWalker; and, we were able to insert a P-tag after each comment. A subtle, but important fact here is that the TreeWalker can iterate over a dynamic DOM tree. Meaning, it had no trouble iterating over the DOM even as we were changing it (ie, inserting P-tags).
After finding this, I added some branching logic to my jQuery.fn.comments() plugin that will use the TreeWalker if it's available.
Want to use code from this post? Check out the license.

Reader Comments
Fascinating. FYI, you should (imo) add a link to the API in the main article (since some folks don't read comments): https://developer.mozilla.org/en-US/docs/Web/API/TreeWalker
@Ray,
Good point; I'm generally bad about that kind of stuff. On a related note, the MDN stuff is so great. Whenever I look up stuff in JS, I start with the MDN prefix, as in Googling for:
"mdn TreeWalker"
Such a great resource!
Agreed on the MDN love. I used to assume it was FF only. Now I've got Google filtering w3schools and I use the prefix as well.
@Ben,
You can skip the manual Google search, here's the direct link: http://mdn.io/TreeWalker :)
Simi, I think we were just commenting on using mdn to prefix our searches in general. It is a tip I know I share w/ folks when I present. :)
@Ben,
Instead of "treeWalker" (var treeWalker = document.createTreeWalker), I'd like to suggest calling your variables "triffid", "birnamWood", "Ent", "treeBeard", "Fangorn" or "fangornForest".
Odd that literature has given us so many tree walkers.
@WebManWalking,
I assume that's a reference to some sort of sci-fi/fantasy book, but it went over my head, sorry!
@Ben,
Day of the Triffids (novel by John Wyndham), MacBeth and Lord of the Rings. Apparently, trees uprooting themselves and walking around is a thing. Also an army disguising themselves as a forest (MacBeth).
Based on your book and movie choices in the past, I really think you would like the Day of the Triffids. You like things that make you think and see things in a new way. John Wyndham likes to explore themes of survival, what traits does it take to survive when the world radically changes. Much of his stuff gets made into movies, though the subtext about survival traits doesn't always make it onto the screen. Village of the Damned was also based on one of his novels. It's been made into a movie, like, 5 times.
@WebManWalking,
I just watched trailers for the movie versions of said items. The Day of the Triffids looks very interesting. The Village of the Damned... not sure I feel about the John Carpenter version of that one :)
Oh you definitely need to see the 1960 version. It got nominated for 2 Hugo awards:
http://www.imdb.com/title/tt0054443/
The book was called The Midwich Coocoos. The coocoo bird lays its eggs into another bird's nest, to get the duped bird to feed/raise the coocoo's offspring. I think Stephen King semi-stole that idea for "The Dome": alien creature(s) with telepathy and ability to invade humans' minds, dome around a town, etc. John Wyndham's estate should demand royalties.
What was this all about? Oh yeah, tree walkers. Sorry. I digressed.
@WebManWalking,
It's funny to see how movie trailers have changed so much over time (link on IMDB). The super-dramatic voice-overs that we have now make the ones back them seems comical. It's hard not to imagine this being watched as some part of a Mystery Science Theater 3,000 :D
Very Nice. It is really helpful. I am trying to use it on ilmiweb.com. Thanks.
Thanks Ben,
I wonder if you came to try (or can recommend) a polifill/shim implementation for TreeWalker for [lte IE 8].
My search yielded a few:
- https://github.com/Krinkle/dom-TreeWalker-polyfill
- https://github.com/JamesMGreene/jWalker
- http://intranet-gei.insa-toulouse.fr:8181/BASE/JS/Mozile08/doc/jsdoc/overview-summary-TreeWalker.js.html
Thanks
Hany
Oh and:
- https://gist.github.com/shawndumas/1132009