
Paginating Record Sets In ColdFusion With One SQL Server Call
A while back, I wrote a blog post on pagination record sets using ColdFusion and two SQL server calls. The first database call was to get a list of valid IDs that match your search criteria. This list was then used to calculate the pagination data (pages, offset, start, prev, next, etc.). The second call was then to get the N number of full records that corresponded to the IDs that needed to be displayed on the page.
I have been mostly happy with this technique, however, I have always been disappointed that I had to perform two database calls. Ideally, I would just perform one call to the database to get the same amount of data. Based on an idea that I got from my main man, Simon Free, I took my original pagination idea and transformed it into a single database call. I am not sure if this is better or faster, but I do know that the algorithm is very similar to my original idea MINUS the first database call, and therefore, I can only guess that it is faster.
The idea here is that instead of returning an initial query that has the matching record IDs, I am going to populate a temporary, in-memory table with those IDs. The trick, though, is that this temporary SQL table has an additional column that is an auto-incrementer. As the IDs get inserted into the temp table, the auto-incrementing column creates an index of row numbers. This temp table can then be easily joined to the target table or insanely simplistic filtering and ordering of the final records.
Take a look at this demo page:
<!--- Kill extra output. --->
<cfsilent>
<!--- Param the offset value. --->
<cftry>
<cfparam
name="URL.start"
type="numeric"
default="1"
/>
<cfcatch>
<cfset URL.start = 1 />
</cfcatch>
</cftry>
<!--- Query for blog entries. --->
<cfquery name="qBlog" datasource="#REQUEST.DSN.Source#">
<!---
Create the temporary table into which we are going
to be storing our ID list. This list will eventually
be joined to our target data table to limit the
number of rows that get returned.
--->
DECLARE @id TABLE (
id INT,
row_number INT IDENTITY( 1, 1 )
);
<!---
Get a variable to hold the total count of the
matching IDs. We are going to return this as one
of the columns.
--->
DECLARE @row_count INT;
<!---
Populate the ID temp table. Because this table has
an AUTO INCREMENTING column, we will get not only
the IDs that match our search criteria, but also
the row number in which they are returned.
--->
INSERT INTO @id
(
id
)(
SELECT
t.id
FROM
(
<!---
It is in this query that the MEAT of
the query logic is performed. Here is
where we filter and order the returned
IDs. This filtering is just checking for
ColdFusion, but this could be very robust
search criteria.
NOTE: I am limitting the search results
to 1,000 records (I rarely feel the need
to paginate more than that). However,
you could use 100 PERCENT.
--->
SELECT TOP 1000
b.id
FROM
blog_entry b
WHERE
CHARINDEX( 'ColdFusion', b.name ) > 0
ORDER BY
b.name ASC
) AS t
);
<!---
Get the number of total records that match our
search criteria.
--->
SET @row_count = (
SELECT
COUNT( * )
FROM
@id
);
<!--- Get the blog entries that match the --->
SELECT
b.id,
b.name,
b.date_posted,
b.time_posted,
<!--- Get the pagination data. --->
i.row_number,
( @row_count ) AS row_count
FROM
blog_entry b
INNER JOIN
@id i
ON
(
b.id = i.id
<!--- Limit based on pagination request. --->
AND
i.row_number >= <cfqueryparam value="#URL.start#" cfsqltype="cf_sql_integer" />
AND
i.row_number < <cfqueryparam value="#(URL.start + 5)#" cfsqltype="cf_sql_integer" />
)
ORDER BY
i.row_number ASC
;
</cfquery>
</cfsilent>
<cfoutput>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<head>
<title>ColdFusion / SQL Pagination Demo</title>
</head>
<body>
<h1>
Blog Entries
</h1>
<!---
Check to see if there were any blog entry records
returned in our search.
--->
<cfif qBlog.RecordCount>
<cfloop query="qBlog">
<p>
<strong>#qBlog.name#</strong><br />
<em>
Record #qBlog.row_number# of
#qBlog.row_count#
</em>
</p>
</cfloop>
<!---
Do pagination. Since we are only doing this WHEN
we have returned records, we know that row_count
will be a valid number.
--->
<cfloop
index="intPage"
from="1"
to="#Ceiling( qBlog.row_count / 5 )#">
<!---
Calculate the start value based on the
current page.
--->
<cfset intStart = (1 + ((intPage - 1) * 5)) />
<!--- Output paginating link. --->
<a
href="#CGI.script_name#?start=#intStart#"
>#intPage#</a>
</cfloop>
<cfelse>
<p>
<em>No entries were found</em>.
</p>
</cfif>
</body>
</html>
</cfoutput>
Notice that the temp SQL table, @id gets only the IDs that match our search criteria filtering. Notice also that it gets these IDs in the proper order of our search results. This temp table then gets joined to our target table (blog_entry) and in the ON clause of the SQL JOIN statement, we are efficiently selecting only the records that should be shown according to the pagination data.
Running the above code, we get the following output:
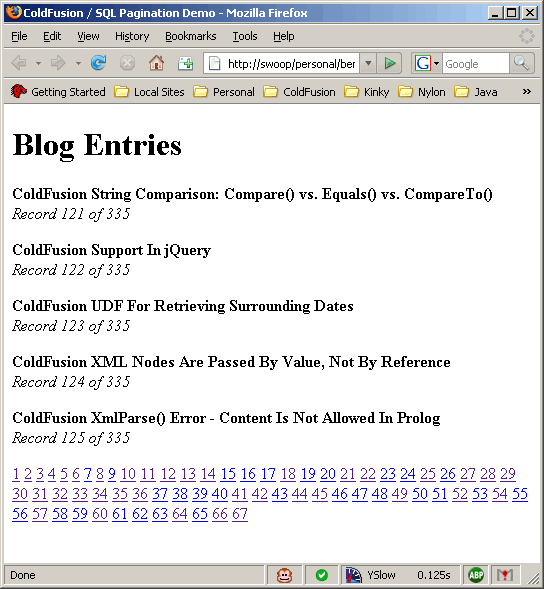
It works quite nicely. This is why I like this pagination method:
It only requires a single database call.
Only relevant data is every being moved from the SQL server to the ColdFusion memory space.
The filtering of target records is made insanely simplistic via the temp table JOIN (regardless of how hugely complicated the search filtering of IDs is).
It's not really duplicating any effort in logic.
It maintains the look and feel of a ColdFusion query.
Nothing too complicated is going on.
It's easy to update on the fly.
To view it in action, click here.
Now, I know there is going to be opposition to this. I know that people like stored procedures and dynamically executed SQL statements. But frankly, I just don't know anything about stored procedures so I cannot argue for or against them. What I can say is that I don't like the LOOK of dynamically executed SQL. This is petty and shallow, I know, but it's my opinion that passing in SQL statements as a string argument makes us no better that classic ASP programmers... and come on, we're ColdFusion programmers - we ARE better than that.
Anyway, just another take on SQL server record set pagination in ColdFusion. Take it with a grain of salt.
Want to use code from this post? Check out the license.
Reader Comments
Thanks Ben! I'm going to have to give that a shot. Since the dawn of time (maybe not quite that long) I have wished there was a way to natively query a subset of records, but until that time, I think this solution is great.
I would imagine that this would be faster as a stored procedure.
Have you tried :
SELECT TOP <limit> id, name,date_posted
FROM blog_entry WHERE id NOT IN (SELECT TOP <offset> id FROM blog_entry ORDER BY date_posted) ORDER BY date_posted
Ben Just a though - if your on MSSQL 2005 - can you try this
select *
from
(
SELECT
b.id,
b.name,
b.date_posted,
b.time_posted,
i.row_number,
row_number() over (order by b.name ASC) AS row_number
FROM
blog_entry b
WHERE
CHARINDEX( 'ColdFusion', b.name ) > 0
) tmp
where
row_number >= <cfqueryparam value="#URL.start#" cfsqltype="cf_sql_integer" />
AND
row_number < <cfqueryparam value="#(URL.start + 5)#" cfsqltype="cf_sql_integer" />
ORDER BY
row_number ASC
@Shlomy,
That would work. The problem is that as the logic for the filtering starts to get more complicated, you have to really duplicate a lot of effort. If the table could only be filtered as the result of several table joins, then those joins would have to go in both the parent select and the sub-select.
@Kris,
Not on 2005 yet :( I have seen some cool stuff. Actually, it may have been Shlomy (above) who gave a SQL Server 2005 presentation at the NYCFUG a while back. He talked all about the cool pagination stuff and that fact that you can even break a result set in to page object in the server, or something like that. I never got to apply it, so it is very faint in my mind. Hopefully one day, I can harness the power of 2005!
Interesting way of tackling the problems. But it's just not nearly as efficient as doing it with a sproc:
With *heavy* inspiration from http://blog.sqlauthority.com/2007/06/11/sql-server-2005-t-sql-paging-query-technique-comparison-over-and-row_number-cte-vs-derived-table/ and http://www.robgonda.com/blog/files/robGonda/UserFiles/File/sp_selectnextn.txt, I recently created the strategy that I just put in a blog entry for 2005 (but you could use the SQL 2000 compatible version from Rob Gonda (see above), which runs very efficiently as well (at least in my testing, which including hitting tables with over 7 million rows and returning the data up to 10X faster than via cfquery.
http://cfzen.instantspot.com/blog/index.cfm/2007/10/11/Paginating-Records-in-CF-with-One-SQL-Server-2005-call
@Aaron,
Like I said on your blog, the STored Proc method loses some readability. But then, as I think about it, not a problem. See, while ColdFusion was originally designed to be "fast enough", in this scenario, with pagination, we don't want fast enough. We want as fast as possible, especially when we are dealing with 7million+ records.
That being said, I bow out to your method (similarly shared by many OOP type people).
Nice Article!
I wonder if it would be possible to write more generic/dynamic routines. I already have such generic routines for query results, based on a query-on-queries, but of course they are very inefficient (due to the huge data amout loaded but not used).
I'm thinking of a custom tag, which could be called "cf_pagedquery" or something, which could wrap the dynamic sql code.. maybe?
another question is, why do you prefer CHARINDEX against LIKE '%value%', which is the more usual way? I wasn't able to find reliable informations about this.
Thanks!
@Thomas,
Other people have more generic routines using dynamically built and executed SQL calls. Just look at Aaron's comments somewhere above this one.
As far as CHARINDEX() over LIKE; I only recently discovered CHARINDEX() and after testing have found it to be twice as fast as LIKE for literal string matching. The downside is that it cannot match wild cards - but honest, I don't use wild cards all that much, so I will take the speed increase.
@Ben
don't want to become this to much offtopic, anyway: if CHARINDEX was faster, that was something i had to try instantly. I made a few example runs and was NOT able to achieve a speed advantage agains LIKE %... expression.
the CHARINDEX method was about 10% SLOWER than LIKE %... expression. When analyzing the query plans, i noticed that LIKE was more accurate in estimating the result rows. (We're on SQL Server 2000.)
@Thomas,
There are no off topic discussions - it's all good :) When you say:
LIKE was more accurate in estimating the result rows
What does that mean? Also, can you give me an example of something you would be testing? My testing showed that CHARINDEX() was significantly faster, so just curious as to how you are getting your results (not saying that they are wrong).
@Ben
Ok so some more information about this subject :)
I had some tests running in our article database.
Row count: 9.2 mio rows
Column Type: varchar(22) (case insensitive, not unique)
contains: Article Numbers (alphanumeric)
index: yes (not clustered)
I need to get a DISTINCT count of hits containing the number "500000":
Queries:
SELECT Count(DISTINCT TecRefNr) FROM Tec203 WHERE TecRefNr LIKE '%500000%'
vs.
SELECT Count(DISTINCT TecRefNr) FROM Tec203 WHERE Charindex('500000', TecRefNr) > 0
Returns: 175
I turned on the query plans and got the following results:
First query 43% of total 7sec batch runtime, second took 57%. A query with leading percent cannot really use the statistics, i guess. First query performs the INDEX SCAN with estimated 575,700 rows. Second query also performs an INDEX SCAN but with estimated 2.7 mio rows.
Actually, both estimated results are far from reality but first is still much closer, which also probably means, that the queries use different calculations to estimate the result count.
Now second case, same queries but WITHOUT DISTINCT expression.
Result is 376, this time bot take exactly 50% of (still 7sec) batch runtime. Result count estimation remain the same. But still CHARINDEX is not faster.
In another different cases i get 50% vs. 50% all the time (using varchar(6000) column, with or without index, clustered/non clustered etc.) for non-distinct queries, but when using DISTINCT the LIKE performs better. I had no case where CHARINDEX was performing faster than LIKE.
@Thomas,
That is very interesting stuff. I am fairly new to indexing, so I am not sure if that has any affect. That columns that I was testing on were not Indexed.
Of course, I can't argue with the numbers. If LIKE is faster for you and your database then go for it. I would be curious to see how your example does on a column that does not have indexing.
nicely done!
I came across View, that was created by a Stored procedure.
Now i need to check the SP thats been used to create it.
How can i check it? what command can i use to see, how the view has been created?
@DD,
I am not sure. I know very little about stored procedures.
I love your tutorials, but man they're hard to follow with the double-line spacing, comments, returns and tabbing. I thought those things were supposed to make things 'easier' to follow..hehe
Hi Ben,
The code works s well. The only issue I have is that the meat of the query ("# !---
# It is in this query that the MEAT of....
---) is coming from a stored procedure ,
Is there a way out as cfquery with dbtype='query' can not be used.
Thank you
Neetu K
@Paul,
Ha ha, I guess to each, their own :) I happen to find this spacing and formatting much easier to follow that compact code. It allows me to truly look at and absorb each line of code on its own.
@Neetu,
I'm sorry, I don't know much about dealing with stored procedures.
Thanks Ben,
Is there any way to sort the data and return it while maintaining the pagination?
@Ben
Just wanted to say THANKS for posting this. I know it was over 3 years ago but it really inspired me to re-design a dynamic report that was killing us.
I wasn't so concerned with pagination, but I used the table variable as a "base query" to get the primary recordset, and then did multiple joins to that virtual table in the very SAME SQL request to get related fields needed for the report (lookup tables etc). And finally I took the results returned from the SQL server and used a QOQ to filter those results based on optional form fields selected by the user. So only one big ugly request is sent to the SQL server.
This changed our report from a server killer to something that now runs in under 5 seconds as a worst case when even the largest possible set of records is selected.
Also for what it's worth I like the extra spacing and comments. I find myself using this format more and more.
I know this post is old, but you always seem to have a post for whatever my question may be so I wanted to say thanks a lot. One issue I ran into with this approach was that the insert into the @id table variable was that it wasn't respecting any order by clauses inside the insert sub query.
The approach here is very creative and bypassed this issue quite nicely.
http://blog.bittersweetryan.com/2010/03/optimized-coldfusion-record-paging-and.html
Thanks again for a great post and thought I'd share this solution with anyone else who might need the order by enforced.
-tim