
Learning ColdFusion 8: CFZip Part III - Reading Zip File Entries
ColdFusion 8 has made creating and manipulating zip archive files quite easy. In the previous parts, we looked at creating zip archives using the CFZip tag alone as well as using the CFZip tag in conjunction with the CFZipParam tag. Now, let's take a look at reading parts of an existing zip archive file. For the following examples, let's create a zip file to work with. We will use the following directory as our archive source:
./data/documents/manual.txt
./data/documents/readme.txt
./data/images/funny.jpg
./data/images/mud_monster.jpg
./data/images/red_face.jpg
./data/images/smile.jpg
To create the zip, we are going to use the simple ColdFusion 8 CFZip tag:
<!---
Create a zip archive of the data directory.
By default, ColdFusion 8 will recurse the
source directory, store the storage paths,
and do to our use of Overwrite attribute, we
will make sure we create a new zip archive.
--->
<cfzip
action="zip"
source="#ExpandPath( './data/' )#"
file="#ExpandPath( './data.zip' )#"
overwrite="true"
/>
This will put all contents of the data directory into the root of our zip archive. Once we have an archive to work with, the most simple reading action we can do is to the list the files. Like CFDirectory, CFZip can read the contents of an existing zip archive file and into a ColdFusion query:
<!--- Read the zip archive file into a ColdFusion query. --->
<cfzip
action="list"
file="#ExpandPath( './data.zip' )#"
name="qFile"
/>
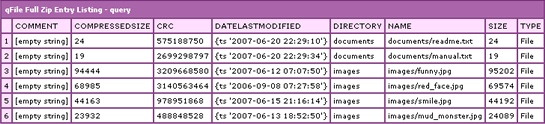
The above code uses the three required attributes for zip archive listing. The file is the zip archive file we are reading and the name is the name of the ColdFusion variable into which the query is stored. This code will read the data archive file into a ColdFusion query with the following columns:
Comment - A comment for the entry (if it exists - I couldn't get this to work in any way).
CompressedSize - The size of the compressed file as it exists in the archive after having been zipped.
CRC - CRC-32 checksum of the uncompressed entry data. This is used to test the entry for corruption.
DateLastModified - The last modified date of the entry. This is not the date that the entry was added to the archive; this is the date of last modification of the actual entry file.
Directory - The directory path of the entry as it is stored in the archive.
Name - The file name of the entry path. This value is NOT supposed to contain anything but the file name, but as you can see from the CFDump output below, the name value does indeed have a directory path. This, I assume, is a bug in the ColdFusion 8 beta.
Size - The uncompressed size of the entry file.
Type - The type of the entry, file or directory. I am not sure how you can get an entry to be of type directory (even when I zipped a target folder using WinZip or WinRAR).
If we CFDump out the query, we get:
By default, ColdFusion 8 will recurse through the zip archive including all files that it comes across. Using the optional
CFZip attributes, we can limit the files that get included in the query. The Filter attribute will only include files that match the filter mask. In the following example, we are only including JPG files:
<!---
Read the zip archive file into a ColdFusion query.
Limit the reading to image files.
--->
<cfzip
action="list"
file="#ExpandPath( './data.zip' )#"
name="qFile"
filter="*.JPG"
/>
As you can see, the filter can include the wild card character, *, and is not case sensitive. From the following CFDump, you will see that only the files from the images directory have been including as they are the only JPG files:

As we have seen before (when creating a zip file), the filter mask can hold a comma delimited list of mask values. This is true for the list action of the ColdFusion 8 CFZip tag as well. For example, the filter:
*.txt,*red*
... would select all TXT files as well as files that contain the substring "red." The filter can be in the main CFZip tag or it can be moved to a nested CFZipParam child tag:
<!---
Read the zip archive file into a ColdFusion query.
Instead of reading all files in the directory, we
are going to filter on several different masks
using the nested child tag CFQueryParam.
--->
<cfzip
action="list"
file="#ExpandPath( './data.zip' )#"
name="qFile">
<!--- Only get text files and *red* files. --->
<cfzipparam
filter="*.txt,*red*"
/>
</cfzip>
But, what's really cool is that we can separate each filter file mask into its own CFZipParam tag:
<!---
Read the zip archive file into a ColdFusion query.
Instead of reading all files in the directory, we
are going to filter on several different masks
using the nested child tag CFQueryParam.
--->
<cfzip
action="list"
file="#ExpandPath( './data.zip' )#"
name="qFile">
<!--- Only get text files. --->
<cfzipparam filter="*.txt" />
<!--- Only get *red* files. --->
<cfzipparam filter="*red*" />
</cfzip>
Running the above code, you will see that we get a query three rows - the two TXT files in the documents folder and the one JPG, red_face.jpg:

This ability to break out the file filtering is really going to make highly dynamic zip queries a total breeze (but hey, isn't ColdFusion in general all about making stuff mad easy?!?).
Additionally, we can also turn off the default recursive behavior of the list action. Running the following code:
<!---
Read the zip archive file into a ColdFusion query.
By not letting the list recurse, we are only going
to be getting entries in the root directory.
--->
<cfzip
action="list"
file="#ExpandPath( './data.zip' )#"
name="qFile"
recurse="false"
/>
... we are going to end up with an empty query. Since only directories (images, documents) are in the root of our zip archive, the query comes back with no entries. Once again, I am confused on how to ever get an entry that is of type directory. I figured this would return the images and documents directory, but alas, it does not.
In the documentation, there is an optional ShowDirectory attribute which defaults to No. The documentation says that this specifies whether to show the directory structure. I have no idea what this means and turning it on and off (true-false) did not seem to have any impact on the returned ColdFusion query (any of the above queries for that matter).
Now that we know how to look into the zip archive file and see what entries it contains, let's explore actually reading files out of it. Using the actions, Read and ReadBinary, we can read out a single entry file at a time into a ColdFusion variable. Both actions work in the same exact way, only the ReadBinary returns the entry file in a binary encoding while the Read action returns a string value.
In addition to the Action attribute, both Read and ReadBinary have three required attributes. The file attribute is the full path to the zip archive. The EntryPath attribute is the zip-root relative path the entry we want to read. The Variable attribute is the name of the ColdFusion variable into which we want to store the data.
In the following example, we are going to read and output the contents of the readme.txt file:
<!---
Read the readme.txt file directly into a
ColdFusion string variable.
--->
<cfzip
action="read"
file="#ExpandPath( './data.zip' )#"
entrypath="documents/readme.txt"
variable="strData"
/>
<!--- Output the file contents. --->
#strData#
Running the above code gives us the following output:
This is the readme file.
While the entry path used above is relative to the root of the zip archive, we cannot use any leading path constructs. For instance, you might be tempted to do something like this:
./documents/readme.txt
... or ...
/documents/readme.txt
While this might seem right from a path standpoint, it will throw the ColdFusion error:
The zip entry for path ./documents/readme.txt was not found in the zip file specified.
When reading in text data using the Read attribute, there is an optional attribute, Charset. This is the encoding used to convert the zip entry data into a text string. I don't fully understand that, so I just exclude it which will get CFZip to default to the encoding of the host machine. This seems to work fine so long as the zip is created and read by the same machine and neither actions defined an explicit charset.
Once we have the entry data in a ColdFusion variable, we can either write it to disk or stream it to the browser. In the following example, we are going to read the context of the readme.txt text file and then write it to the local file system:
<!---
Read the readme.txt file directly into a
ColdFusion string variable.
--->
<cfzip
action="read"
file="#ExpandPath( './data.zip' )#"
entrypath="documents/readme.txt"
variable="strData"
/>
<!---
Write the data to a file on the local file
system. This is basically like performing
a single-file zip extraction.
--->
<cffile
action="write"
file="#ExpandPath( './extracted_readme.txt' )#"
output="#strData#"
addnewline="false"
/>
Similarly, we can read in the binary mud_monster.jpg image data and then write that to the local file system:
<!---
Read the mud_monster.jpg file directly into a
ColdFusion binary data variable.
--->
<cfzip
action="readbinary"
file="#ExpandPath( './data.zip' )#"
entrypath="images/mud_monster.jpg"
variable="binImageData"
/>
<!---
Write the data to a file on the local file
system. This is basically like performing
a single-file zip extraction.
--->
<cffile
action="write"
file="#ExpandPath( './extracted_image.jpg' )#"
output="#binImageData#"
addnewline="false"
/>
What's cool about the ReadBinary action is that it gives us a binary data variable that is packaged and ready to stream to the browser using ColdFusion's CFContent tag and Variable attribute:
<!---
Read the mud_monster.jpg file directly into a
ColdFusion binary data variable.
--->
<cfzip
action="readbinary"
file="#ExpandPath( './data.zip' )#"
entrypath="images/mud_monster.jpg"
variable="binImageData"
/>
<!---
Stream the binary image data directly to the
browser as if it was an image on the web server.
--->
<cfcontent
type="image/jpeg"
variable="#binImageData#"
/>
The listing of the files within a zip archive seem to be a bit buggy, but I am sure that will be taken care of with the next release (or a hot fix or something). As always, though, I am quite impressed with how easy ColdFusion 8 is making it for developers to perform the actions that used to require a lot of Java hacking or third party tools.
Want to use code from this post? Check out the license.
Reader Comments
Ben,
The name field in the cfzip action="list" not being "only" name is not a bug. Its the entry name for the zip entry in the zip file. Its the name by which an entry in the zip is identified. While implementing this, I had thought about it for a while whether to include both 'name' and 'entryName' and then decided against it. The reason is - more than 90% of the time you would only need the entry name. If at all you need only file name (which I dont think will be so common), it is very easy to get from the entry name.
@Rupesh,
I think the documentation (granted it is Beta) needs to be updated. The documentation says:
"DIRECTORY: Directory containing the entry. For the preceding example, the directory is help/docs. You can obtain the full entry name by concatenating directory and name."
If concatenated the directory column and the name column, I would get a value like:
documentsdocuments/readme.txt
... which not be the entry path. The name itself seems to be the full entry path (which is what you are saying).... and I agree, 90% of the time this is going to be the most useful value. Good judgement call.... just be sure to update the docs (I am sure you guys are doing that anyway :)).
But, that aside, yes, I agree, if you needed to get the file name, it would be an easy task.
Also, what is ShowDirectory? :D I could not get this to do anything??
I just asked Ben about this via Twitter and he did not know. Perhaps someone here does.
<cfzip action="list"> dateLastModified does not provide timezone info. Is the dateLastModified GMT or is it the timezone where the file was last modified? If it is the latter, is it possible to get the timezone of dateLastModified?
Thanks for any help.