
Performing A SublimeText-Inspired Fuzzy Search For String Matching In Angular 7.2.15
At InVision, my team is considering working on a new search feature. And, when it comes to "search", one of the most delightful user experiences that I've come across is the "fuzzy search" performed by SublimeText's "Goto Anywhere" command. The "Goto Anywhere" anywhere command takes your search query and gracefully matches it across non-sibling substrings in your file system. This makes it incredibly easy to locate files, even when you're not exactly sure what they are named. In preparation for my teams search initiative, I wanted to try and build a proof-of-concept fuzzy search for string matching in Angular 7.2.15.
Run this demo in my JavaScript Demos project on GitHub.
View this code in my JavaScript Demos project on GitHub.
If you haven't used the SublimeText "Goto Anywhere" command, it's just an input with a dropdown that lists the fuzzy matches for the given input value. For example, if I enter "donkey" as my search phrase, my current SublimeText project gives me the following Goto Anywhere experience:
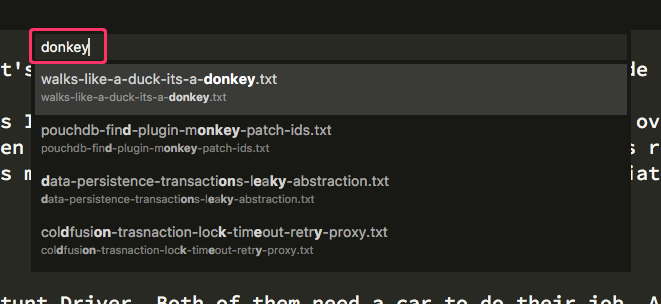
As you can see, the first result contains a direct match for "donkey". The other three results, however, contain only partial matches for "donkey". But, while the remaining results are only partial matches, notice that all of the characters from the input are matched in sequence. This creates for a very flexible - but not overly flexible - search paradigm.
While I was working on my proof-of-concept for this in Angular, I came across a blog post by Forrest Smith. Like me, Forrest loves the SublimeText experience and wanted to recreate it. His solution is ultimately more intelligent than mine, placing emphasis on word-boundaries and the proximity of a match to the beginning of a value. His fuzzy-matching library is definitely worth checking out!
Of course, my exploration wouldn't really be any fun if I didn't try to build something for myself; so, I went about trying to create a fuzzy-search algorithm in Angular. And while my approach is, in many ways, a much more naive version when compared to Forrest's approach, I broke mine up into a two-phase solution, first scoring and then formatting the set of possible values.
I created a two-phase solution in an attempt to cut down on unnecessary processing. In a search context, I don't necessarily want to show all the results at once (or even at all). As such, I didn't want to fully process values that I would never show to the user.
In my approach, the first phase just scores each value, but doesn't concern itself with the formatting of the value. Then, the calling context can take the resultant scores, sort the values based on said scores, reduce the number of values that the application will show to the user, and then - as only as a second phase - format the visible values. This way, I only incur the overhead of formatting for the subset of values that I am going to render.
To see this in action, I've created a simple demo in which you can search though a list of Primate Species. With each input key-stroke, I'm scoring, filtering, and then formatting the set of all primates. The bulk of the work is done in the applyFilter() method of my App Component:
// Import the core angular services.
import { Component } from "@angular/core";
// Import the application components and services.
import { FuzzyMatcher } from "./fuzzy-matcher";
import { FuzzySegment } from "./fuzzy-matcher";
import { primates } from "./primates";
import { Species } from "./primates";
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
interface FilterMatch {
score: number;
value: Species;
segments: FuzzySegment[];
}
@Component({
selector: "my-app",
styleUrls: [ "./app.component.less" ],
template:
`
<input
type="text"
name="filter"
[(ngModel)]="form.filter"
(ngModelChange)="applyFilter()"
placeholder="Search primates...."
autofocus
class="filter"
/>
<ul *ngIf="matches.length">
<li *ngFor="let match of matches" class="match">
<span
*ngFor="let segment of match.segments"
class="match__segment"
[class.match__segment--on]="segment.isMatch"
>{{ segment.value }}</span>
</li>
</ul>
`
})
export class AppComponent {
public form: {
filter: string;
};
public matches: FilterMatch[];
private fuzzyMatcher: FuzzyMatcher;
// I initialize the app component.
constructor( fuzzyMatcher: FuzzyMatcher ) {
this.fuzzyMatcher = fuzzyMatcher;
this.form = {
filter: ""
};
this.matches = [];
}
// ---
// PUBLIC METHODS.
// ---
// I apply the current filter to the collection of primates, generate a set of fuzzy
// matches.
public applyFilter() : void {
// If there is no filter, then hide the list entirely. We only want to show
// matches when we have something to match on.
if ( ! this.form.filter ) {
this.matches = [];
return;
}
this.matches = primates
// First, we want to take the updated form input and use it to SCORE the
// collection of values. This phase will have to evaluate the entire set of
// values; but, will only do the minimal amount of work needed to calculate a
// scope. Then, we'll be able to use that score to narrow down and format the
// set of values that we end-up showing to the user.
.map(
( primate ) => {
return({
value: primate,
score: this.fuzzyMatcher.scoreValue( primate.name, this.form.filter )
});
}
)
// Now that the entire set of values has been scored, let's sort them from
// highest to lowest.
.sort(
( a, b ) => {
return(
( ( a.score > b.score ) && -1 ) || // Move item up.
( ( a.score < b.score ) && 1 ) || // Move item down.
0
);
}
)
// For the sake of the demo, we only want to show the top-scoring matches.
// Slice off the top of the scored values.
.slice( 0, 20 )
// At this point, we've narrowed down the set of values to the ones we want
// to show to the user. Now, we can go back and create a data-structure that
// can be more easily rendered (but takes more processing).
.map(
( scoredValue ) => {
return({
score: scoredValue.score,
value: scoredValue.value,
segments: this.fuzzyMatcher.parseValue( scoredValue.value.name, this.form.filter )
});
}
)
;
}
}
As you can see, in the first phase of the input processing, I use the FuzzyMatcher service to map the collection of species onto a scored result-set. I then take that scored result-set, sort it (higher scores are better), and then slice off the top-20 results. These are the results that I intent to show to the user. And, once I have this reduced set of results, I then use the FuzzyMatcher to perform phase-two of the algorithm in which I go back and parse and segment the top results that I intend to render.
Each of the results in the second phase of the algorithm - those returned by the .parseValue() method - is an array of segments that represent a sequential substring of the value. Each substring is either matched or not-matched by the search query:
export interface FuzzySegment {
value: string;
isMatch: boolean;
}
With this data structure, when rendering each fuzzy match, all I need is an *ngFor loop that applies special CSS to any segment in which the "isMatch" flag is True:
<li *ngFor="let match of matches" class="match">
<span
*ngFor="let segment of match.segments"
class="match__segment"
[class.match__segment--on]="segment.isMatch"
>{{ segment.value }}</span>
</li>
ASIDE: By breaking the fuzzy match up into two phases, I have the option to omit the special formatting altogether. In such a scenario, I will only incur the cost of having to score the values, not the cost of parsing them into formatable segments.
With that said, let's look at the FuzzyMatcher service. It only has two methods that directly map to the two phases of my search algorithm: scoreValue() is phase-one that does nothing but return a numeric score; and, parseValue() is phase-two that breaks the value up into matching and non-matching segments:
// Import the core angular services.
import { Injectable } from "@angular/core";
// ----------------------------------------------------------------------------------- //
// ----------------------------------------------------------------------------------- //
export type FuzzyScore = number;
export interface FuzzySegment {
value: string;
isMatch: boolean;
}
@Injectable({
providedIn: "root"
})
export class FuzzyMatcher {
// I parse the value against the given input, dividing it up into a collection of
// segments that either match or do not match sequences within the input.
public parseValue( value: string, input: string ) : FuzzySegment[] {
var valueLength = value.length;
var inputLength = input.length;
var valueIndex = 0;
var inputIndex = 0;
var segments: FuzzySegment[] = [];
var segment: FuzzySegment;
while ( valueIndex < valueLength ) {
var valueChar = value.charAt( valueIndex++ ).toLowerCase();
var inputChar = input.charAt( inputIndex ).toLowerCase();
// If this character matches the input, add to a matching segment.
if ( valueChar === inputChar ) {
inputIndex++;
if ( segment && segment.isMatch ) {
segment.value += valueChar;
} else {
segment = {
value: valueChar,
isMatch: true
};
segments.push( segment );
}
// If we've run out of input characters to match, we can short-circuit
// the segmentation - we know that the rest of the value will contain
// non-matching characters - we can add them to a final segment.
if ( ( inputIndex === inputLength ) && ( valueIndex < valueLength ) ) {
segments.push({
value: value.slice( valueIndex ),
isMatch: false
});
// Force the while-loop to end.
break;
}
// If this character does NOT match the input, add to a non-matching segment.
} else {
if ( segment && ! segment.isMatch ) {
segment.value += valueChar;
} else {
segment = {
value: valueChar,
isMatch: false
};
segments.push( segment );
}
}
}
return( segments );
}
// I compare the input to the given value and return a score for the fuzzy match.
public scoreValue( value: string, input: string ) : FuzzyScore {
// For the scoring process, we don't need to maintain the case of the arguments.
// As such, we can normalize them now so that we don't have to do it inside of
// each loop iteration.
var normalizedValue = value.toLowerCase();
var normalizedInput = input.toLowerCase();
var valueLength = normalizedValue.length;
var inputLength = normalizedInput.length;
var valueIndex = 0;
var inputIndex = 0;
// When several letters are matched in a row, we're going to give them extra
// weight in the scoring since this more likely to provide a meaningful match.
var previousIndexMatched = false;
var score = 0;
while ( valueIndex < valueLength ) {
var valueChar = normalizedValue.charAt( valueIndex++ ); // Get and increment.
var inputChar = normalizedInput.charAt( inputIndex );
// If the current character matches the next part of the sequential input,
// we are going to increase the score of the match.
if ( valueChar === inputChar ) {
inputIndex++;
// If the previous character was also a match, let's bump the score by
// slightly more.
score += ( previousIndexMatched )
? 3
: 2
;
previousIndexMatched = true;
// If we've run out of input characters to match, then we can short-
// circuit the scoring based on the number of remaining characters in the
// value (each remaining character will be detracted from the score).
if ( inputIndex === inputLength ) {
return( score -= ( valueLength - valueIndex ) );
}
// If the current character does NOT Match the next part of the sequential
// input, we are going to decrease the score of the match.
} else {
score -= 1;
previousIndexMatched = false;
}
}
return( score );
}
}
As you can see, my scoring algorithm is fairly simple - I add points for matching letters and then subtracting points for non-matching letters. For a more intelligent algorithm, I recommend looking at Forrest Smith's library mentioned above.
If we open this Angular app in the browser and try searching for "hosan", we get the following browser output:

As you can see, even though "hosan" isn't a direct match for the primate, "homo sapiens", it still matches enough sequential characters to float the primate to the top of the search results.
Part of what makes the SublimeText experience so magical is that it's blistering fast. Frankly, I have no idea how they make it so fast. I have projects that contain tens-of-thousands of files and the "Goto Anywhere" command responds instantaneously. In an Angular 7.2.15 application, we have more performance constraints around change-detection and the general single-threading of the UI (User Interface) thread. So, I know that I will never achieve SublimeText speeds. That said, by breaking the fuzzy search into two phases, I hope that I can limit the processing overhead to only when it is needed.
Want to use code from this post? Check out the license.
Reader Comments
Ben. This a great article. It is a simple yet powerful algorithm. I've always wanted to know what the term 'fuzzy', means, in relation to the search paradigm.
I would actually like to use this routine to search through data from my MySQL database. But, I am wondering whether it would be more efficient to convert your code into Coldfusion and do the data analysis on the server?
At the moment, I am using a Hash Tag auto complete library, called "ngx-chips", in an Angular project. Every time, a user types into an input, it sends a request back to the server. Not quite, for every character, because I am using 'debounceTime'.
The server then searches through my database for an "exact" match. Now, what I would like to do, is instead of sending back exact matches to the client, I would like to use your fuzzy search to find near matches, as well.
Does this sound like a reasonable use case?
@Charles,
Fuzzy searching against a database gets a bit more complicated. As you can see in my approach, it's "brute force". Meaning, I'm manually looping over all the potential values and evaluating each one of them in turn. You definitely don't want to be pulling your entire database into memory just to do something this.... well, depending on the size of the data you are searching. If the data-set is small, you can do that; you can even cache it in the server memory so you don't have to go back to the database.
But, if you need to do fuzzy search over a large database, things get much more complicated. You can always do something like using the
LIKE %operator in SQL; but, that is quite limited. You'll probably need some sort of "full text indexing". Each database has some kind of text indexing; but, you'll get better performance if you have a specialized database that is designed for Search as a feature.That said, I have basically no experience with search-oriented databases like Lucene and Solr, so I can't really speak to that. Just to say that these database exist to make search fast.
Yes. I see. That makes sense. I will try and use it, in some other way, when I have a predefined data set, client side.
Hi Ben,
cool idea. Your fuzzy search works very well and fast. For a real world search I had to fine tune the scoring system.
If there is a perfect match (value contains search term) I started your algorithm just at position (indexOf). Because if you have
example text:
acdcb xxxxxx abc</b xxxxxxxx
search:
abc
Here some shorter text with "a",...,"b",...,"c" will get better score. Depends on the length. A text with exactly search term inside should be scored higher.
I added also more points if the matches are at first character of search and value. Something like that
//score up first caracter matches
score += inputIndex == 1 ? 2 : 0;
score += valueIndex == 1 ? 2 : 0;
In my project the result was good for longer search terms. With my changes it is also a good result at first key strokes for one, two and three character search terms.
Now I have a good mix of search as usual and a backup result, if the website user misspells things or does not exactly know what to search.
The results got even better after returning the score and do not score down
if ( inputIndex === inputLength ) { return score; //( score -= ( valueLength - valueIndex ) ); }My assumption is that the search term should never be the complete text of result. A good result is, few letters typed in and the first shown item is your searched item. The down score penalizes long text terms more than short ones. Maybe there is another way. Returning the score was fine for me.
Thanks a lot for your inspiring solution :-)
Best Regards
Marco