
Shedding The Monolithic Application With AWS Simple Queue Service (SQS) And Node.js
For too long, I have lived in the world of the monolithic web application - the single application that does everything for everyone. This year, I really want to evolve my understanding of web application architecture and try to think about applications as a collection of loosely coupled services. I think an important first step, in this journey, is to start experimenting with messages queues.
Message queues provide an asynchronous means of communication between components within a system. One (or more) components generates messages and pushes them onto a queue; then, one (or more) components asynchronously pops messages off of that queue and processes them. The beauty of the shared queue is that the relevant parts of the system become independently scalable and much more resilient to failure.
But, I'm new to message queues; so, I'll refrain from speaking out of turn. Rather, I'd like to share my experiment. Since this is my first play with message queues, the Amazon Web Service (AWS), Simple Queue Service (SQS), seemed like a really easy way to begin. I already have an AWS account; and, with the AWS Software Developer's Kit (SDK), jumping right into code is straightforward.
NOTE: Unlike some message queue services, SQS does not guarantee "one time" delivery; rather, it guarantees "at least one time" delivery. Meaning, due to the distributed natures of SQS, a message may be received more than one time, even after it has been deleted.
In addition to playing with message queues, I also want to start getting better at Node.js. While I love JavaScript with the rich, fiery passion of a thousand suns, I've never actually built any production components with Node.js. And, since I'm in the midst of rethinking application architecture, I might as well do that with Node.js.
Now, out of the box, I could have started using the standard error / callback pattern that has been popular in the Node.js community (and core codebase). However, coming from client-side JavaScript - and AngularJS - I have trouble imagining a world without Promises. As such, I'm also using this as an opportunity to see how people are using libraries like Q to "de-nodeify" the old-school approaches to workflow.
To start with, I want to keep it simple. I've created a Node.js script that sends a one-off message to SQS. And, I've created a Node.js script that (long) polls the same message queue, looking for messages to process.
Here is the Node.js script that sends the message:
// Require the demo configuration. This contains settings for this demo, including
// the AWS credentials and target queue settings.
var config = require( "./config.json" );
// Require libraries.
var aws = require( "aws-sdk" );
var Q = require( "q" );
var chalk = require( "chalk" );
// Create an instance of our SQS Client.
var sqs = new aws.SQS({
region: config.aws.region,
accessKeyId: config.aws.accessID,
secretAccessKey: config.aws.secretKey,
// For every request in this demo, I'm going to be using the same QueueUrl; so,
// rather than explicitly defining it on every request, I can set it here as the
// default QueueUrl to be automatically appended to every request.
params: {
QueueUrl: config.aws.queueUrl
}
});
// Proxy the appropriate SQS methods to ensure that they "unwrap" the common node.js
// error / callback pattern and return Promises. Promises are good and make it easier to
// handle sequential asynchronous data.
var sendMessage = Q.nbind( sqs.sendMessage, sqs );
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// Now that we have a Q-ified method, we can send the message.
sendMessage({
MessageBody: "This is my first ever SQS request... evar!"
})
.then(
function handleSendResolve( data ) {
console.log( chalk.green( "Message sent:", data.MessageId ) );
}
)
// Catch any error (or rejection) that took place during processing.
.catch(
function handleReject( error ) {
console.log( chalk.red( "Unexpected Error:", error.message ) );
}
);
As you can see, I'm taking the sqs.sendMessage() method and wrapping it in a Q-based proxy. This proxy will translate the error / callback pattern into one that properly resolves or rejects a promise. This way, I can use .then() and .catch() to handle various states of the promise chain.
Once I could get messages onto the SQS message queue, I created a script that could receive them. But, unlike the previous script, that only performed one-off operations, I wanted this receiving script to continuously poll for new messages.
// Require the demo configuration. This contains settings for this demo, including
// the AWS credentials and target queue settings.
var config = require( "./config.json" );
// Require libraries.
var aws = require( "aws-sdk" );
var Q = require( "q" );
var chalk = require( "chalk" );
// Create an instance of our SQS Client.
var sqs = new aws.SQS({
region: config.aws.region,
accessKeyId: config.aws.accessID,
secretAccessKey: config.aws.secretKey,
// For every request in this demo, I'm going to be using the same QueueUrl; so,
// rather than explicitly defining it on every request, I can set it here as the
// default QueueUrl to be automatically appended to every request.
params: {
QueueUrl: config.aws.queueUrl
}
});
// Proxy the appropriate SQS methods to ensure that they "unwrap" the common node.js
// error / callback pattern and return Promises. Promises are good and make it easier to
// handle sequential asynchronous data.
var receiveMessage = Q.nbind( sqs.receiveMessage, sqs );
var deleteMessage = Q.nbind( sqs.deleteMessage, sqs );
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// When pulling messages from Amazon SQS, we can open up a long-poll which will hold open
// until a message is available, for up to 20-seconds. If no message is returned in that
// time period, the request will end "successfully", but without any Messages. At that
// time, we'll want to re-open the long-poll request to listen for more messages. To
// kick off this cycle, we can create a self-executing function that starts to invoke
// itself, recursively.
(function pollQueueForMessages() {
console.log( chalk.yellow( "Starting long-poll operation." ) );
// Pull a message - we're going to keep the long-polling timeout short so as to
// keep the demo a little bit more interesting.
receiveMessage({
WaitTimeSeconds: 3, // Enable long-polling (3-seconds).
VisibilityTimeout: 10
})
.then(
function handleMessageResolve( data ) {
// If there are no message, throw an error so that we can bypass the
// subsequent resolution handler that is expecting to have a message
// delete confirmation.
if ( ! data.Messages ) {
throw(
workflowError(
"EmptyQueue",
new Error( "There are no messages to process." )
)
);
}
// ---
// TODO: Actually process the message in some way :P
// ---
console.log( chalk.green( "Deleting:", data.Messages[ 0 ].MessageId ) );
// Now that we've processed the message, we need to tell SQS to delete the
// message. Right now, the message is still in the queue, but it is marked
// as "invisible". If we don't tell SQS to delete the message, SQS will
// "re-queue" the message when the "VisibilityTimeout" expires such that it
// can be handled by another receiver.
return(
deleteMessage({
ReceiptHandle: data.Messages[ 0 ].ReceiptHandle
})
);
}
)
.then(
function handleDeleteResolve( data ) {
console.log( chalk.green( "Message Deleted!" ) );
}
)
// Catch any error (or rejection) that took place during processing.
.catch(
function handleError( error ) {
// The error could have occurred for both known (ex, business logic) and
// unknown reasons (ex, HTTP error, AWS error). As such, we can treat these
// errors differently based on their type (since I'm setting a custom type
// for my business logic errors).
switch ( error.type ) {
case "EmptyQueue":
console.log( chalk.cyan( "Expected Error:", error.message ) );
break;
default:
console.log( chalk.red( "Unexpected Error:", error.message ) );
break;
}
}
)
// When the promise chain completes, either in success of in error, let's kick the
// long-poll operation back up and look for moar messages.
.finally( pollQueueForMessages );
})();
// When processing the SQS message, we will use errors to help control the flow of the
// resolution and rejection. We can then use the error "type" to determine how to
// process the error object.
function workflowError( type, error ) {
error.type = type;
return( error );
}
As you can see, I'm once again wrapping the relevant SQS methods in a Q-based proxy so that both sqs.receiveMessage() and sqs.deleteMessage() work with promises. For me personally, this just makes the workflow easier to follow.
To get this script to run continuously, I defined the long-polling inside of a self-executing function block that could recursively call itself. This way, as soon as one request completes, either in success or in error, the long poll will be kicked back up, in search of the next message to process.
If I run these scripts side-by-side, I get the following terminal output:
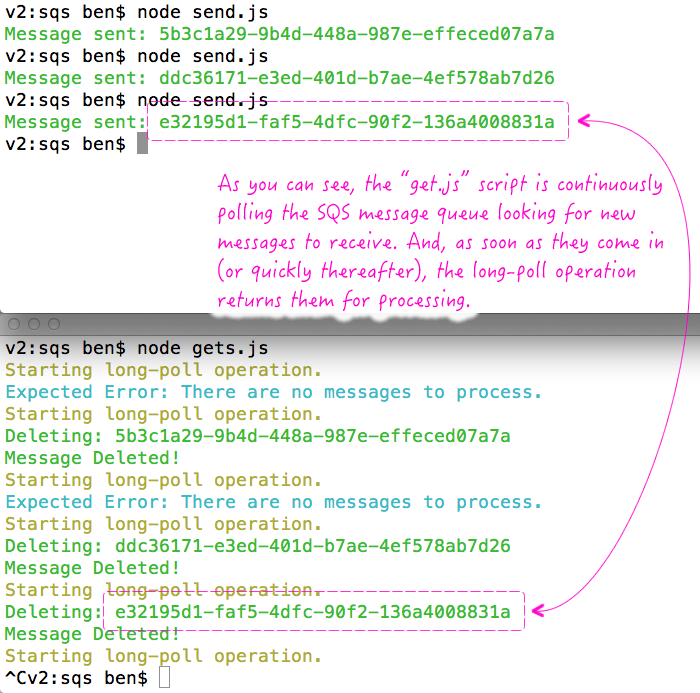
When I saw this work for the first time, I almost jump out of my seat with excitement! Obviously, there's a lot more to consider when working with message queues; but, seeing these messages flow from sender to receiver via asynchronous queue feels like a huge milestone in my evolution as a developer.
Want to use code from this post? Check out the license.

Reader Comments
Fair warning, If there's something wrong with the message or your code is failing, it will sit there and plug the queue up until it's removed or deleted. I highly recommend making it a practice (on failing messages), backing up the failures on S3 or whatever makes sense, deleting the message and moving on.
@Todd,
Interesting point. When I was reading up on SQS this weekend, it did seem to have something called a "Dead Letter Queue", which seems to be a place that Amazon can send messages that fail a given number of times. That said, I suppose if that's not monitored properly, things can get out of hand pretty quickly.
Can you expand on your failures-to-S3 comment a bit more? Who does that? The queue implementation? Or the queue receiver?
One thing I am still very fuzzy on is how much data should actually be in the message? IE, should it be totally self-contained? Or, should it just contain relevant event/IDs that can then be used to reconcile a shared-data store? Or, everything in between with zero concept of a "traditional message queue usage pattern." So exciting, but at the same time, I have like a thousand more questions now!
Dead letter queue must be new. Never saw it until now. At work, if it fails, we back up the message as json on S3, email support, and move on. I used to have a manual dead letter queue setup, but didn't like the 14 day rention restriction. Hence the flat file to S3.
@Todd,
Ah, ok cool. Thanks for the clarification. It's a brave new world for me :)
At my job we use SNS/SQS messaging often so I think I can answer some of your questions.
Some way to handle messages that fail to process is a must. We, personally, really like to use the Dead Letter Queue. If the message fails to process 3 times, it drops into the dead letter. We have a separate process that monitors the dead letter queue and if it grows too large, an alert is sent out. Of note: we also log the failures as they happen (we use Splunk), which can in turn set off an alert of its own if the failure is particularly problematic.
As for what is actually in the queue message, we tend to use a JSON stringified object in this format:
{
Subject: 'service.Action',
Message: JSON stringified object
}
Subject is used to break up actions performed by the queue processor (We have queues for each service, not each individual action).
Message contains all the information the processor will need. How much information you put in here is really up to you but we tend to lean towards putting all the information needed to complete the action. UUIDs for look-ups are useful here if the information you need to process is too large or too sensitive to drop into your queue.
@Danny,
Good stuff, thanks. Since you use SQS, let me ask you a follow-up question. I see that SQS guarantees "at least once" delivery. And, while I haven't experienced this in my R&D, apparently you can get a message more than once. For certain things, I can understand that this doesn't matter, such as with generated image thumbnails.
But, if I'm going to communicate with a user, such as sending out an email or a SMS text message, clearly I need to guarantee that this communique should only be sent out once. Do you guys run into this kind of problem? And, if so, how are you dealing with it?
"apparently you can get a message more than once" - This only happens if you don't delete it or set up your queues correctly.
Case in point, if you have a long running process, that message "hiding" will expire and go back into the queue before the job finished. The jobs you have processing should be very lean, very fast. If you stick with that in mind, this never happens. And, don't forget, you have some leeway because you can adjust the configuration of how long things get hidden.
If you're really concerned that things aren't being finished in time, all the messages have ids, so you should be able to tell if you've had that message at least once before, but requires you to track it.
@Ben
As Todd said, you don't have to worry if your processes are quick and you are deleting messages afterwards.
One of the things we use SQS for us sending emails and I can confirm we have not had an issue with extra sends.
The entire gamification system I built on Education Exchange ( http://edex.adobe.com/ ) relies on SQS. I haven't ever had a problem with it. It's easy to work with, provided you plan everything out. Stay small, compact, and lean. You can do a lot with a little. :)
@Danny, @Todd,
From what I was reading in the SQS documentation, I am not sure that is 100% correct. The way I read it, the "at least once" behavior is a byproduct of the distributed nature of the queue. Your messages live in multiple servers, which is why you might not even be able to receive it the first time (if the randomly-sampled server doesn't have it yet). So - again, this is how I interpreted the docs - if you send a deleteMessage() command, it may hit one server; but, it's possible that the next receiveMessage() command will sample a server to which the "delete" operation has not yet propagated.
But, even the docs say that this most of the time, this will not happen.
Actually, on this page:
http://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/DistributedQueues.html
... they codify it a bit better:
>> Amazon SQS stores copies of your messages on multiple servers for redundancy and high availability. On rare occasions, one of the servers storing a copy of a message might be unavailable when you receive or delete the message. If that occurs, the copy of the message will not be deleted on that unavailable server, and you might get that message copy again when you receive messages. Because of this, you must design your application to be idempotent (i.e., it must not be adversely affected if it processes the same message more than once).
So, it does sound like this is an outlier / edge-case related to the uptime of the servers storing your particular queue.
I haven't bumped into the issue at all unfortunately. You should plan for it, that's about the best I can offer. :)
@Todd,
Ha ha, no problem, I can dig it. For now, I'll just assume it won't happen, unless I'm doing really really important things like financial transactions (which I'm not). An email going out twice, accidentally? The world ain't gonna end ;)
I've had upwards to 2000+ (highest ever was around a hundred thousand) emails sent out daily using SQS / Gamification system. I haven't had complaints of duplicates yet.
Well written article, you should have written this two weeks earlier than I wouldn't reinvent similar queue handling. I got actually similar solution for the queue handling, only the problems comes with memory leaking. I am using the heroku worker dyno to run my example, but it takes about one day to fill all my 512MB memory. Have you encountered similar problems ? As far I can tell the sqs receive message is causing this.
Similar problem with Heroku and SQS polling, as you can see it has some memory leak.
@Todd,
Works for me :D
@Risto,
I've only just started to play with this stuff, so I can't speak to any real-world memory-based problems yet. Maybe some of the other here can. That said, a memory leak, in general, is due to memory that can't be freed up, typically due to variable references that never get destroyed. In JavaScript, that is usually due to a closure that won't free up a reference.
Now that we're talking about this, I am looking my recursive workflow and I think it is OK. I am not seeing any references being passed out-of-scope in a way that feels suspicious. That said, memory leaks and memory management feels like "black magic" to me.
I know there are tools for profiling node like Node Inspector ( https://github.com/node-inspector/node-inspector ) but I've not gotten that far in my node education yet.
I've also been doing this. I've had a lot of success using ElasticBeanstalk to host the workers. The beauty of this is that EB workers get SQS messages as standard HTTP POSTs, and you reply with a 200 for success, or an error status code, and EB will do the right thing with the message.
This makes for easier conversion (perhaps you have existing services that already listen for HTTP messages), handling as everything does HTTP, and testing.
EB supports docker images too, so getting anything on there is easy. My node.js worker does audio processing, so it needs the appropriate packages.
@Ben,
True, the resources are never freed up as the memory usage gets higher, so be careful if you are running the queue polling in limited memory environments like Heroku etc.
I made quick benchmark, removed all the unnecessary abstractions and other Node modules which are not needed. Example is located here https://gist.github.com/riston/087124c2323b00167576. As you can see the memory usage grows in time quickly https://docs.google.com/spreadsheets/d/1Xhr3xPirWoGTkULC3n0oCn-PBMc9sPSycBi6LV0TGIA/pubchart?oid=2051713826&format=image.
Are you familiar with this book: http://www.enterpriseintegrationpatterns.com/ ? I recently went through the chapter summaries on the website, which were very good, and enough to get me thinking in the context of messaging. Java projects like Spring Integration and Apache Camel nicely encapsulate many of the concepts and message-handling with systems like ActiveMQ- sometimes without custom code. Just started using it for a project and love thinking in this structured manner.
@Jeremy,
ElasticBeanstalk sounds really cool - I just read the description. SQS is like the second AWS service that I've used after S3; so, basically know *next* to nothing about the AWS ecosystem. That's really interesting to hear that SQS can support that HTTP / Response status code. I didn't see that in the docs when I was reading about it. But, it was a lot of information to absorb at one time.
@Risto,
Holy cow, that is fascinating! I'm looking that the code you have and, I'm not seeing *anything* that should indicate a memory leak. If this was running in Chrome, at least I could open up the profiler and see what's holding onto references. I wonder if there is something inside the AWS service that's leaking.
Do you have any thoughts on what the hecks going on? Awesome exploration!
@Jim,
I know the book by reputation only but, have not read it myself. I've heard nothing but great things about it though. That, and the book "Refactoring", is on my mental checklist when there are few more hours in the day.
I tried reading "Node.js The Right Way" a while back and got most of the way through it; but, I wasn't really doing Node.js stuff at the time, so it was hard to visualize all the stuff that the author was talking about:
http://shop.oreilly.com/product/9781937785734.do
But, it does talk about Message Queues as well and about some really interesting communication patterns. I think it's time I go back an finish it up.
Interesting long polling technique.
You're increasing the stack every time you make a new request.
For a queue listener (which is meant to be alive for a long time), I would feel highly uncomfortable with this.
@Ben,
The great advantage to using ElasticBeanstalk worker is that you don't need to worry about all the polling code etc. and having to make sure you do it right and clean up correctly. And EB will auto scale the workers.
The disadvantage is that to test it from your own development machine you need to reproduce the HTTP messages from SQS... so you do still need to write that polling code at some point.
@Joseph,
Ah, interesting - I hadn't thought about it in terms of increasing the stack. But, I'm not sure if it actually does due to the fact that Q does a lot of things asynchronously. When I look at the source code for Q (which is rather large), I see a lot of references to nextTick() and setImmediate() and setTimeout(). I think what it does is try to put things in a later point in time on the event loop, which I think would prevent the stack from growing.
But, that's just theory and I'm super new to Node.js. What do you think?
I would probably have something like this:
function pollQueueForMessages() {
receiveMessage().finally(function() {
done = true;
});
}
var done = true;
setTimeout(function() {
if ( ! done) return;
pollQueueForMessages();
done = false;
}, 100);
which is similar to what John Resig uses here for scrolling performance: http://ejohn.org/blog/learning-from-twitter/
There are many other ways to accomplish this, but this is just a quick solution thrown together in 2 minutes.
Sorry, but I'm a little busy now :(
@Joseph, I think your solution wouldn't loop, it'd only poll once.
var poll = true;
function pollQueueForMessages() {
return receiveMessage().then(processMessage).finally(function() {
if(poll) {
process.nextTick(pollQueueForMessages)
}
});
}
pollQueueForMessages();
It looks recursive, but isn't, as nextTick will enter the function freshly triggered after the current message has finished processing.
@Jeremy,
That setTimeout was supposed to be a setInterval.
@Ben
Is there no way to edit comments here?
@Joseph,
Sorry, comment functionality here is not terribly robust :( Something I've been meaning to work on. Ultimately, I'd love to try to implement some markdown-lite functionality.
@Risto,
So, I just installed node-inspector and v8-profiler for the first time and did some inspecting. I think the cause of the memory leak is the console.log() statements. If I take those out, the stack profiling goes back to zero after polling is complete. Very interesting!
@Ben Nadel
About the memory leak some of you may have received e-mail from Amazon which explained which aws-sdk versions had memory leak with SQS module. With the latest versions this should be fixed. Also the depending of your node version the tls still has some memory leaks, I am using now the latest version of io.js(1.6).
Great article!
I've wanted to play with queues and have been keeping an eye on RabbitMQ but somehow Amazon just feels more reliable.
Will definitely use this on my next node project.
@Holt,
At work, I believe we use RabbitMQ and have a lot of success with it (though I haven't been on those projects personally). Like many other queues, RabbitMQ has a "delivery once" approach, where as Amazon has that deliver *at least once*. This is the one feature I keep getting stuck on.
@Risto,
And now, I just read (on Twitter) that Io.js and Node.js are merging back together. Even change keeps on changing :D Enough to make your head spin.
@Ben Nadal
True, since the last post on Mar 28, the io.js version has already changed from 1.6 to 2.3. The TLS memory leaks seems to have fixed and currently running similar approach has no problems.
@Risto,
Woohoo! One less thing to learn :D
Hi Ben Nadel,
Nice tutorial it is . It saved my life. I want to see the unit test cases for get.js. Could you please help me out in this. Thanks.
Please let me know how to create unit test cases using mocha.js for get.js
@Nanthakumar,
To be honest, I am the last person that should be talking about how to test things. I'm extremely new when it comes to testing code. I try to just write it bug-free the first time (insert sarcasm here :D).
That said, to make this code testable from a unit-level, what I would probably do is actually break out the parts of the code that don't directly tie-in to AWS. In this example, its not so obvious because there is so little code. But, you can imagine a situation in which the code takes the message from the queue and then passes it off to service XYZ for processing. Rather than worrying about testing the SQS directly, I'd worry more about writing tests for the "hand off" service XYZ. That way, you pass it what ever data you want and test the results.
If you really wanted to test the actually SQS interactions, I think that's where you'd have to start talking about mocking and stubbing... but that goes far beyond what I really know about testing, sorry.
Best of luck!
sqs allow MaxNumberOfMessages = 10 ("The maximum number of messages to return. Amazon SQS never returns more messages than this value but may return fewer. ") to fetch messages at once, So is there any way we can run multiple parallel processes
in nodejs which can handle many sqs messages.
Any npm package available for that?
@Abdul,
Good question, you don't need a separate module for that there is already cluster module. The polling would remain same, you need to use cluster workers to consume messages faster.
@Risto,
do you have any working example or any link which help me that will be gr8.
@Risto,
but if i use cluster it will scale depend upon core of cpu. I want to scale more.
Lets assume we can fetch max 10 message from sqs per second. So we can fetch (3600 *10) = 36000 messages per hour. So i want to create multiple parallel process. So as many messages get fetched and handle.
Do you have any solution for that?
@Abdul,
Hello, well the SQS problem is that it's not meant for fast org large amount messages handling. You also could consider other options like Kafka/Amazon Kinesis. Why so? You pay also for polling, if the poll time gets too small you make too many poll requests. That's why I suggested using single master for polling and multiple workers consuming the messages.
It depends on how "heavy work" the consumer workers are doing, you could also scale the cluster more than one per core, x2 x3. Make sure you test it before and find amount of workers that you are able to handle. Instead of using single master for polling yes you could move the polling to workers, but you should also consider a number of requests then made to AWS.
@Risto,
Thanks for you time
I did found out how to change the queue location changing some const in the SQS Class.
I don't know if there is still someone who moderate this website, but thanks for all the hard work.
I was doing the course Lynda Up and Running with Amazon Web Services_2013 and there was a lot of errors in the code, this page did help me a lot to fix them and be able to run the examples to understand the code.