
My First Look At Streams In Node.js
Last week, I started to look into Gulp.js as a possible build-system. It seems really cool; but, I immediately felt the pain of not understanding Node.js streams, which are at the core of Gulp.js. As such, I spent the last few days trying to build a Node.js stream. This turned out to be a bear of a task; but, I think I finally got something working! Since I love Regular Expressions, I thought it would be fun to build a stream that takes an input and then outputs matches of the given regular expression pattern.
I started out by building a Writable stream and just logging matches. When I got that working, I tried to add the "Readable" portion of the stream. But, that didn't work - I couldn't "inherit" from both the Writable and Readable classes.
Then, I tried to create a Duplex stream; but, that seemed janky since I had to listen for the "finish" event internally before finalizing the output stream. I think, in a Duplex stream, the input and the output are supposed to coexist with little cross-knowledge.
Finally, I tried a Transform stream, which seemed to be more inline with what I was trying to do. I was producing output based on the input, which is what the transform stream is doing - linking the input to the output. The transform stream also provides a "_flush" method, which gives us an easy hook into the end of the input stream and feels much cleaner than having to bind to the "finish" event internally.
When all was said and done, here's what I came up with. It's not supposed to be perfect - it was just an real-world case for stream investigation. It has clear flaws, like the inability to safely use look-aheads or to safely match across multiple chunks. But, I think it was sufficient enough to teach me the basics of how streams work.
// Include module references.
var fileSystem = require( "fs" );
var stream = require( "stream" );
var util = require( "util" );
var chalk = require( "chalk" );
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// I am a Transform stream (writable/readable) that takes input and finds matches to the
// given regular expression. As each match is found, I push each match onto the output
// stream individually.
function RegExStream( pattern ) {
// If this wasnt' invoked with "new", return the newable instance.
if ( ! ( this instanceof RegExStream ) ) {
return( new RegExStream( pattern ) );
}
// Call super-constructor to set up proper options. We want to set objectMode here
// since each call to read() should result in a single-match, never a partial match
// of the given regular expression pattern.
stream.Transform.call(
this,
{
objectMode: true
}
);
// Make sure the pattern is an actual instance of the RegExp object and not just a
// string. This way, we can treat it uniformly later on.
if ( ! ( pattern instanceof RegExp ) ) {
pattern = new RegExp( pattern, "g" );
}
// Since the patter is passed-in by reference, we need to create a clone of it
// locally. We're doing to be changing the RegExp properties and we need to make
// sure we're not breaking encapsulation by letting the calling scope alter it.
this._pattern = this._clonePattern( pattern );
// I hold the unprocessed portion of the input stream.
this._inputBuffer = "";
}
// Extend the Transform class.
// --
// NOTE: This only extends the class methods - not the internal properties. As such we
// have to make sure to call the Transform constructor (above).
util.inherits( RegExStream, stream.Transform );
// I clone the given regular expression instance, ensuring a unique refernce that is
// also set to include the "g" (global) flag.
RegExStream.prototype._clonePattern = function( pattern ) {
// Split the pattern into the pattern and the flags.
var parts = pattern.toString().slice( 1 ).split( "/" );
var regex = parts[ 0 ];
var flags = ( parts[ 1 ] || "g" );
// Make sure the pattern uses the global flag so our exec() will run as expected.
if ( flags.indexOf( "g" ) === -1 ) {
flags += "g";
}
return( new RegExp( regex, flags ) );
};
// I finalize the internal state when the write stream has finished writing. This gives
// us one more opportunity to transform data and push values onto the output stream.
RegExStream.prototype._flush = function( flushCompleted ) {
logInput( "@flush - buffer:", this._inputBuffer );
var match = null;
// Loop over any remaining matches in the internal buffer.
while ( ( match = this._pattern.exec( this._inputBuffer ) ) !== null ) {
logInput( "Push( _flush ):", match[ 0 ] );
this.push( match[ 0 ] );
}
// Clean up the internal buffer (for memory management).
this._inputBuffer = "";
// Signal the end of the output stream.
this.push( null );
// Signal that the input has been fully processed.
flushCompleted();
};
// I transform the given input chunk into zero or more output chunks.
RegExStream.prototype._transform = function( chunk, encoding, getNextChunk ) {
logInput( ">>> Chunk:", chunk.toString( "utf8" ) );
// Add the chunk to the internal buffer. Since we might be matching values across
// multiple chunks, we need to build up the buffer with each unused chunk.
this._inputBuffer += chunk.toString( "utf8" );
// Since we don't want to keep building a large internal buffer, we want to pair-
// down the content that we no longer need. As such, we're going to keep track of the
// the position of the last relevant index so that we can drop any portion of the
// content that will not be needed in the next chunk-processing.
var nextOffset = null;
var match = null;
// Loop over the matches on the buffered input.
while ( ( match = this._pattern.exec( this._inputBuffer ) ) !== null ) {
// If the current match is within the bounds (exclusive) of the input buffer,
// then we know we haven't matched a partial input. As such, we can safely push
// the match into the output.
if ( this._pattern.lastIndex < this._inputBuffer.length ) {
logInput( "Push:", match[ 0 ] );
this.push( match[ 0 ] );
// The next relevant offset will be after this match.
nextOffset = this._pattern.lastIndex;
// If the current match butts up against the end of the input buffer, we are in
// danger of an invalid match - a match that will actually span across two (or
// more) successive _write() actions. As such, we can't use it until the next
// write (or finish) event.
} else {
logInput( "Need to defer '" + match[ 0 ] + "' since its at end of the chunk." );
// The next relevant offset will be BEFORE this match (since we haven't
// transformed it yet).
nextOffset = match.index;
}
}
// If we have successfully consumed a portion of the input, we need to reduce the
// current input buffer to be only the unused portion.
if ( nextOffset !== null ) {
this._inputBuffer = this._inputBuffer.slice( nextOffset );
// If no match was found at all, then we can reset the internal buffer entirely. We
// know we won't need to be matching across chunks.
} else {
this._inputBuffer = "";
}
// Reset the regular expression so that it can pick up at the start of the internal
// buffer when the next chunk is ready to be processed.
this._pattern.lastIndex = 0;
// Tell the source that we've fully processed this chunk.
getNextChunk();
};
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// Create an input stream from the file system.
var inputStream = fileSystem.createReadStream( "./input.txt" );
// Create a Regular Expression stream that will run through the input and find matches
// for the given pattern - "words".
var regexStream = inputStream.pipe( new RegExStream( /\w+/i ) );
// When the regex stream is ready, start reading-in word matches.
regexStream.on(
"readable",
function() {
var content = null;
// Since the RegExStream operates on "object mode", we know that we'll get a
// single match with each .read() call.
while ( content = this.read() ) {
logOutput( "Pattern match: " + content.toString( "utf8" ) );
}
}
);
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// I log the given input values with a distinct color.
function logInput() {
var chalkedArguments = Array.prototype.slice.call( arguments ).map(
function( value ) {
return( chalk.magenta( value ) );
}
);
console.log.apply( console, chalkedArguments );
}
// I log the given output values with a distinct color.
function logOutput() {
var chalkedArguments = Array.prototype.slice.call( arguments ).map(
function( value ) {
return( chalk.bgMagenta.white( value ) );
}
);
console.log.apply( console, chalkedArguments );
}
The file that I am piping into the RegExStream contains the following content:
How funky is your chicken? How loose is your goose?
And, when we run the above Node.js file, using "\w+" as the regular expression pattern, we get the following console output:
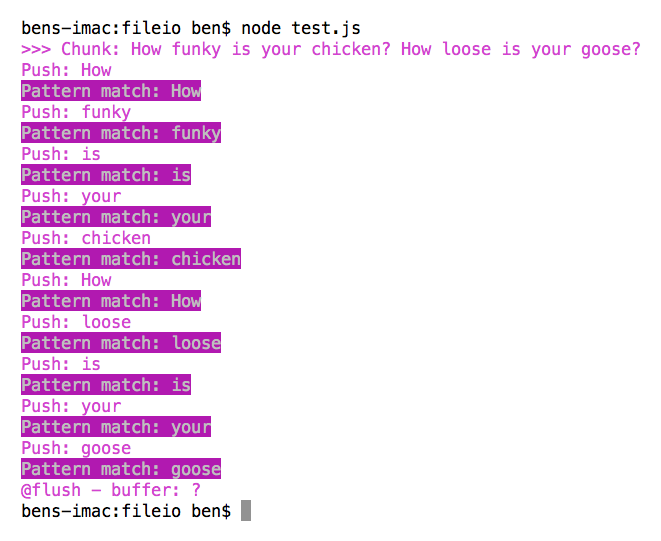
Very cool stuff!
Now that I have a better understanding of Streams in Node.js, I think I can start to make some sense of the way Gulp.js is operating. Clearly, there's still going to be a lot of blind-spots; but, at least now I'll have some insight into why I couldn't even get a simple gulp-less plugin to work!
Want to use code from this post? Check out the license.

Reader Comments
I'd *strongly* recommend this series for learning more about Node streams:
http://nodeschool.io/#stream-adventure
Actually, *all* the courses are worth your time.
@Ray,
Thanks for the link. I think I've heard of them, but have definitely never seen that site before. This looks like some really good content. Awesome sauce!
@All,
This post uses a Node.js Transform stream that I constructed by explicitly extending stream.Transform and defining prototype methods. It seems that this kind of stuff - in Gulp.js - is often encapsulated using the Through2 module. As such, I wanted to refactor this experiment using Through2:
www.bennadel.com/blog/2663-node-js-transform-streams-vs-through2-streams.htm
It does [just about] the same thing, and compares the approach using explicit prototypal inheritance vs. through2 encapsulation.
Hey man,
Just searching on the web kinda way to parse some weird sentences coming into a stream... On 'data' event, I need to reconize and gather sentences like #.*#, and I want to re-chunk them for that.
Your stuff seems to fit my needs, so would it be ok to reuse it ? If yes, is that hosted anywhere or should I just c/p that ?
Thanks =)
Why not use regexp.source instead of regexp.tostring to dup?