
Reflections On My Client-Side MVC View-Rendering Hackathon
Yesterday, I spent about 10 straight hours exploring client-side MVC View-rendering in my first (of many) solo hackathons. I came up with a UI design, broke it out into HTML and CSS, and then coded a thick-client application on top of it; and, I did all of this under the pretense that the project would end up being a complete failure. As I explained before, I was embracing failure in hopes that it would open my mind up the possibility of new perspectives. So, 10 hours, 3 Monsters, and about 6 Frescas later, what did I learn?
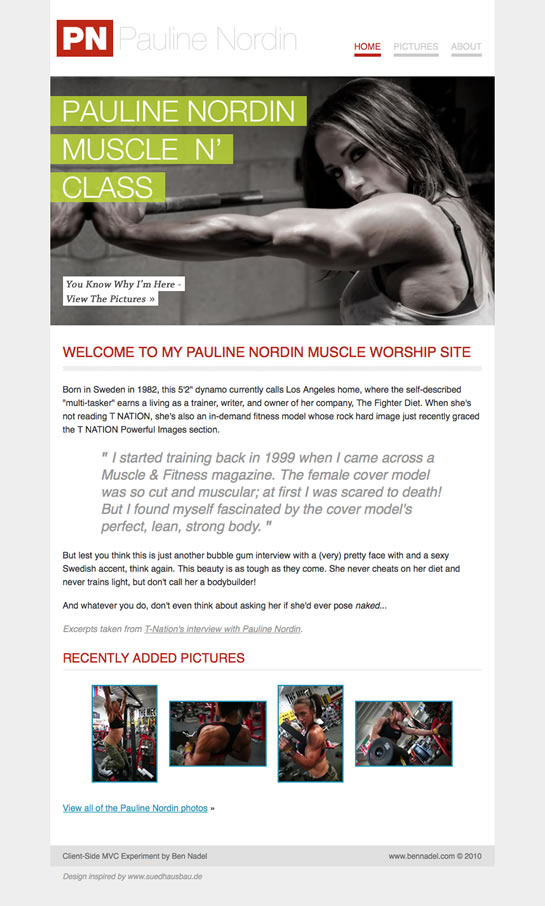
First off, if you want to see what I created, you can view my "Pauline Nordin Muscle Worship" site here. I spent the first 3 hours of the hackathon working on the design and the CSS. I know this upfront effort might sound silly when the goal was to explore Javascript methodologies; but, in order to extract the most insight from the coding, I wanted to try and make entire experience as realistic as possible.
| |
|
|
||
| |
 |
|
||
| |
|
|
You can download the code for the site here. No server-side technology is required - this is HTML and Javascript only.
The goal of the hackathon was relatively simple: I wanted to take the view-rendering approach that I use on the server-side and port it over to the client side. On the server-side, page templates have content placeholders within them. When a request comes in to the server, the controller collects those placeholder variables before it tries to render the selected template. In this way, page rendering is performed using an outside-in approach.
Step 1: Route request to appropriate controller.
Step 2: Collect content variables (often times constructed using database requests).
Step 3: Render template using previously-defined content variables.
On the server-side, this is a really easy approach because every single request starts out with a blank slate. On the client-side, however, things are not so simple. For starters, there is no inherent sense of a new request, so there's no blank slate to start with. Also, on the client-side, you can't swap out the entire HTML page (I don't think) - you can only swap out parts of it. As such, it becomes much more interesting to jump between two different templates that have their own stylesheets.
To account for these differences, I created a root node in the BODY of the application that would act as the main content container. Each template renderer would then append its content to this node as the rendered content of the page. To handle different page templates (ie. standard view, photo view), each template renderer disables all linked stylesheets before it enables its own. In this way, we can have multiple, template-specific stylesheets attached to the HTML page without having to worry about coming up element IDs and Classes that are unique to the entire site.
With this methodology, we only ever have one active stylesheet and one active DOM tree at any given time. And just so I'm clear on this point, I don't mean we're hiding and showing elements - I mean we literally only have one rendered DOM tree at any time; previously rendered pages are completely detached from the DOM every time a new request needs to be rendered.
At first, I thought this approach was a complete pain in the butt; but, I very quickly found out that it has some great benefits. As I stated before, when we conditionally turn stylesheets on and off in the context of a given template, it means that our stylesheets can truly be template-specific without having to worry about naming collisions with unrelated stylesheets. As a flip-side to that coin, it also means that our templates can have template-specific IDs; since we are literally rebuilding the client-side DOM with every "request," it means that template-based IDs will never conflict. In other words, each template can have semantic IDs (ie. #logo) without messing up document queries or causing odd rendering behaviors.
As all of this is taking place, the controllers are using an "event collection" object to keep track of data. This event collection contains the content variables for the template as well as the name of the template that is being rendered. Since data in a client-side application can be obtained asynchronously, the individual controllers never return information back to the main controller - that would assume synchronous rendering. Rather, the main controller passes a "render" callback method through to the targeted module controller. Then, only after the module controller has completed its sub-content collection, it can call the render callback and pass-in the augmented event collection to aide in the final template rendering.
All in all, this was a really fun experiment. My brain was totally fried by the end of the day; but, I think I got some really valuable experience out of it. I know I'm having trouble articulating exactly what that "valuable experience" is but, I think that has more to do with my information overload rather than lack of value.
A Few More Poorly Articulated Thoughts
Page offset: one of the nice behaviors provided by web browsers is the ability to remember your page offset (scroll) as you go backwards / forwards in your navigation history. Although my thick-client application made use of history-based navigation, I found the page offset to be completely unreliable. I am not sure how to fix this.
Slave to the URL: while this is not really relevant to my goals, one thing I did not want to do is become a slave to the URL. Meaning, I didn't want my application to respond to URL changes; rather, I wanted my application to respond to events which then might cause a change in URL. In other words, I wanted URL hash changes to be a fallout of the event, not the cause of it. To achieve this behavior, I would have had to intercept more UI interactions.
Request vs. State: in this experiment, I refer to rendering "requests." To me, a request is anything that can be logically mapped to a given URL. This does not include states of a page. So, for example, a "user detail" view would be a "request;" but, a "delete confirmation" modal window on that user detail would be a "state" of that page and therefore could not be gotten to by URL alone.
RESTful requests: because we are using the location hash to represent a given request, we have to use RESTful representations. This means that a requested resource must be entirely defined by the resource path without the aide of any query string variables.
GET vs. POST: while it makes sense on the server-side to route both GET and POST requests, the default behavior of the web browser makes routing POST requests on the client-side significantly more complex. You can certainly do it if you want to; however, it would require you to build a routing mechanism that does not depend on the URL. Ultimately, this is probably the best routing approach in the long run, but it requires more UI management.
Progressive enhancement: this is not relevant to progressive enhancement of a web site - that's a completely different conversation altogether. We're not talking about building a site with some Javascript-enabled UI efficiencies added onto it - we're talking about thick-client applications.
Reader Comments
Ben,
You know what I love about you doing stuff like this? Although I currently have absolutely no need for this currently, in fact I can't even imagine what I would use this for at our company. I still store stuff like this in a part of my brain, labeled "Cool and Possibly Useful info" One day one of our developers will walk in my office and detail a problem he/she has been working on and can't find the solution too. I will remember an article like this that you have done, and casually remark, "Oh yes, I know what you need to do, Ben Nadel blogged about something like that" Quick google search.... Yup here it is! The best part is they look at me like am some kind of genius.
Keep it up mad professor!
Did you check out Sammy, it's an MVC that I have really been enjoying.
http://code.quirkey.com/sammy/
+1 for Sammy.
@Tim,
Ha ha, awesome :) I look forward to that.
@Alex, @James,
I played around with Sammy a while back after watching Aaron's preso at last year's jQuery Conference. It looks cool and I definitely got some good stuff out of it. I wasn't sure how I felt about POST-routing; it's probably time that I go back and look into it again (now that I have some more experience).
This sounds interesting. But assume you're building a high-traffic site. Normally in such circumstances we'd use some cache on the server-side to mitigate the large number of requests. In a CSVR (client-side view rendering) scenario you can still cache the output of the calls for data on a per page basis, but you can't cache the processing of that data. ANy thoughts? Are browsers fast enough (and server-side component instantiation slow enough) that caching the server-side is good enough?
A minor enhancement proposal - there's a native hashchange event in the latest versions of several browsers (FF, IE, Safari/Webkit), this way such a page feels even faster.
I've blogged about this feature here: http://cfstuff.blogspot.com/2010/09/native-hashchange-event-good-bye.html
@Howard,
I am not sure that I completely understand what you are asking. When you have a thick-client, you still need to actually "process" data on the server. The real difference is that the server starts to act simply like an API and the client starts to handle more of the "work flow" that the user experiences. So, you can cache a lot of the client; but, if you actually need to mutate / augment persistent data, you still need to hit the server to process that.
Please clarify if I am totally off-base on what you are asking.
@Hansjoerg,
The hashChange event is definitely very cool. I had no idea that existed until I started playing with my CorMVC project; at that point, I started getting weird duplication errors in browsers that apparently supported it (I was faking it at the time with a setInterval() approach).
Do you know what version of IE started supporting this event?
Thanks for the code... What you did in 10 hours took me several days... Well, it's not quite exactly the same but it's the way of programming ;-) Will help me understanding javascript even better...
@Booosh,
Very cool - if we're both going in the same direction, then maybe it's a good sign that we're on the right track?If you have any feedback, I'd be all ears; this rich-client-side is so very interesting to me.