
Grouping JOIN Clauses In SQL
Here's something that I have touched on in my blog via examples, but I have never talked about it explicitly. It is the idea of grouping SQL JOIN clauses. Normally, when you join multiple tables together, you simply have one JOIN after another. In some situations, this is not always possible to do in a way that will return accurate data. In rare cases, you have to get creative with your joins to enforce the proper relationships. There are a few ways to do this, one of which is the grouped JOIN.
For example, imagine you had three tables: A, B, and C. You want to join all three tables together (A join B join C) in such a way that the following rules hold true:
You want to get ALL records in table A.
You want to get all records in table B that correspond to table A but ONLY IF there is also a record in table C that corresponds to table B.
Tables A, B, and C as concepts are a little hard to visualize, so let's try and put some real world objects in place. This is just an example I came up with to write the blog post so be sure that it is not the best scenario in which you would use this. Let's say instead we have tables: Company, Contact, and Phone. Each contact is associated with a single company and each phone number is associated to a single contact.
Now, to translate the A,B,C problem into the Company, Contact, Phone problem, we want to select all company records regardless as well as all related contacts but ONLY if those contacts also have a related phone number. Let's walk through some approaches and why they don't quite satisfy our needs.
As always, I need to create and populate some temporary tables that I can run my queries against. For all of the following examples, we are first running this code:
<!--- Create temp tables. --->
<cfsavecontent variable="strCreateSQL">
DECLARE @company TABLE (
id INT,
name VARCHAR( 30 )
);
DECLARE @contact TABLE (
id INT,
name VARCHAR( 30 ),
company_id INT
);
DECLARE @phone TABLE (
name VARCHAR( 30 ),
contact_id INT
);
INSERT INTO @company
(
id,
name
)(
SELECT 1, 'Nylon Technology' UNION ALL
SELECT 2, 'Edit.com' UNION ALL
SELECT 3, 'HotKoko'
);
INSERT INTO @contact
(
id,
name,
company_id
)(
SELECT 1, 'Maria Bello', 1 UNION ALL
SELECT 2, 'Christina Cox', 1 UNION ALL
SELECT 3, 'Julia Stiles', 2 UNION ALL
SELECT 4, 'Julie Ensike', 3
);
INSERT INTO @phone
(
name,
contact_id
)(
SELECT '123-456-1890', 1 UNION ALL
SELECT '123-456-5555', 4
);
</cfsavecontent>
Don't worry about understanding the temp table creation and population. It is secondary to the point of this post.
Approach One
We know that we want to get all the companies and we want to get related contacts, but we don't need to get contacts. This means that the Company-Contact relationship does not need to be enforced and therefore, should be a LEFT OUTER JOIN. Then, let's just say we throw on another LEFT OUTER JOIN to get the phone numbers into contacts. This would look something like this:
<!--- Query for contacts. --->
<cfquery name="qContact" datasource="#REQUEST.DSN.Source#">
<!--- Create temp tables. --->
#PreserveSingleQuotes( strCreateSQL )#
<!---
Query for companies and contacts, but ONLY return
contacts if there is an associated phone number.
--->
SELECT
c.id,
c.name,
( ct.name ) AS contact_name,
( p.name ) AS contact_phone
FROM
@company c
LEFT OUTER JOIN
@contact ct
ON
c.id = ct.company_id
LEFT OUTER JOIN
@phone p
ON
ct.id = p.contact_id
</cfquery>
Running this code, we get the following CFDump output:

Notice that stringing JOIN clauses together (as we might usually do) doesn't work here because we end up returning two contacts, Christina Cox and Julia Stiles, that do not have an associated phone number. This breaks our Contact-Phone relationship rule.
Approach Two
Building on approach one, we might think that to get around this, all we have to do is add a WHERE clause to get rid of the contacts that don't have phone numbers. That would be, we don't want to return any records in which the joined phone number is NULL:
<!--- Query for contacts. --->
<cfquery name="qContact" datasource="#REQUEST.DSN.Source#">
<!--- Create temp tables. --->
#PreserveSingleQuotes( strCreateSQL )#
<!---
Query for companies and contacts, but ONLY return
contacts if there is an associated phone number.
--->
SELECT
c.id,
c.name,
( ct.name ) AS contact_name,
( p.name ) AS contact_phone
FROM
@company c
LEFT OUTER JOIN
@contact ct
ON
c.id = ct.company_id
LEFT OUTER JOIN
@phone p
ON
ct.id = p.contact_id
WHERE
p.name IS NOT NULL
</cfquery>
Running this code, we get the following CFDump output:

This got rid of the NULL phone numbers alright, but it also go rid of the third company, Edit.com, which only has contacts that lack phone numbers. This maintains the Contact-Phone relationship rule but violates the All Companies rule.
Approach Three
Starting to see where this is tricky, right? Let's step back for a second and think about what we are trying to do. We need the Contact-Phone relationship to be always true. This is where we would traditionally use an INNER JOIN. But, at the same time, we don't care if a company has any contacts. This is where we would traditionally use the LEFT OUTER JOIN (which we already have in place). Ok, so now, you might now be tempted to just change the second LEFT OUTER JOIN to an INNER JOIN:
<!--- Query for contacts. --->
<cfquery name="qContact" datasource="#REQUEST.DSN.Source#">
<!--- Create temp tables. --->
#PreserveSingleQuotes( strCreateSQL )#
<!---
Query for companies and contacts, but ONLY return
contacts if there is an associated phone number.
--->
SELECT
c.id,
c.name,
( ct.name ) AS contact_name,
( p.name ) AS contact_phone
FROM
@company c
LEFT OUTER JOIN
@contact ct
ON
c.id = ct.company_id
INNER JOIN
@phone p
ON
ct.id = p.contact_id
</cfquery>
Running this code, we get the following CFDump output:
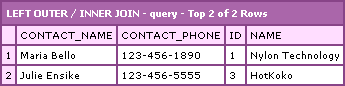
This looks just like the result in approach two. The problem here is that we are now INNER JOINning the result of Company-Contact to Phone. And, since there are only two contacts that have phone numbers, this filters it all down to only two phone numbers and their related records; essentially, this is making the Phone records the limiting factor of the overall query.
Approach Four
Now that we have seen why all of our other approaches have failed, let's take a look at the grouped JOINs approach. We can group JOINs by using parenthesis to prioritize certain joins before other joins are executed. This is similar to PEMDAS in mathematics (where groups equations are evaluated before the equations that involve them). The syntax looks a little funny, but once you get used to it, it's pretty straightforward:
<!--- Query for contacts. --->
<cfquery name="qContact" datasource="#REQUEST.DSN.Source#">
<!--- Create temp tables. --->
#PreserveSingleQuotes( strCreateSQL )#
<!---
Query for companies and contacts, but ONLY return
contacts if there is an associated phone number.
--->
SELECT
c.id,
c.name,
( ct.name ) AS contact_name,
( p.name ) AS contact_phone
FROM
@company c
LEFT OUTER JOIN
(
@contact ct
INNER JOIN
@phone p
ON
ct.id = p.contact_id
)
ON
c.id = ct.company_id
</cfquery>
Notice here that we are grouping the JOIN between the Contact and Phone tables. Notice also that this JOIN is an INNER JOIN because we only want to get contacts that have associated phone numbers. Once that group has been processed, we are then LEFT OUTER JOINing its result to the Company table. You will notice that in the ON clause of the LEFT OUTER JOIN, we can refer to the table aliasing created in the grouped join. You might be tempted to move that ON clause into the group, but it won't work.
Running this code, we get the following CFDump output:
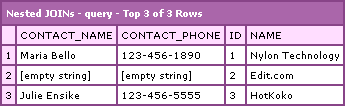
Now, you can see that we are returning all three companies which enforces are All Companies rule, and, we are only returning contacts who have a phone number. This satisfies all the rules that our query has to follow with minimal effort (if you know how to do it).
In approach four, I talk about "processing groups" and intermediary results, but I don't actually know what is going on behind the scenes. For all I know, the join grouping just gets translated into backend logic that the SQL server is following when it joins all three tables together.
Alternate Approaches Without JOIN Grouping
Another way that I can thing of doing this is to join the Contact and Phone table as part of a sub select to which the Company table is then joined:
<!--- Query for contacts. --->
<cfquery name="qContact" datasource="#REQUEST.DSN.Source#">
<!--- Create temp tables. --->
#PreserveSingleQuotes( strCreateSQL )#
<!---
Query for companies and contacts, but ONLY return
contacts if there is an associated phone number.
--->
SELECT
c.id,
c.name,
t.contact_name,
t.contact_phone
FROM
@company c
LEFT OUTER JOIN
(
SELECT
ct.company_id,
( ct.name ) AS contact_name,
( p.name ) AS contact_phone
FROM
@contact ct
INNER JOIN
@phone p
ON
ct.id = p.contact_id
) AS t
ON
c.id = t.company_id
</cfquery>
This accomplishes the same thing, and is sort of doing the same thing (in terms of intermediary results) if you think about it, but look at it. Not pretty. Not only do we have to create an inline result set that, itself, has to be aliased, we also have to worry about selecting all the columns we want to return in the INNER JOIN and then our primary query has to query columns from that intermediary table with the intermediary table alias. I think you will find that once you are comfortable with the grouped JOIN, it is a much more elegant and maintainable solution.
Another alternate solution, and perhaps the most unattractive solution (in my opinion), is to turn the whole query on its head and do a RIGHT OUTER JOIN to the company table:
<!--- Query for contacts. --->
<cfquery name="qContact" datasource="#REQUEST.DSN.Source#">
<!--- Create temp tables. --->
#PreserveSingleQuotes( strCreateSQL )#
<!---
Query for companies and contacts, but ONLY return
contacts if there is an associated phone number.
--->
SELECT
c.id,
c.name,
( ct.name ) AS contact_name,
( p.name ) AS contact_phone
FROM
@phone p
INNER JOIN
@contact ct
ON
p.contact_id = ct.id
RIGHT OUTER JOIN
@company c
ON
ct.company_id = c.id
</cfquery>
Here, we are first doing an INNER JOIN between the Phone and Contact which enforces our second rule. Then, we do a RIGHT OUTER JOIN to the company table which gets all the companies and any intermediary Contact-Phone results. This will get you the same results as above. The syntax here is very simple, but it's the approach that makes me feel very uncomfortable; we want to get Company records and yet, Company is the last table from which we are querying. This is more of a personal issue, but I feel that my "primary" content table should first. This way, your mentality matches the SQL statement. Don't twist your logic to conform to JOIN rules - use better syntax to align with your vision.... but that's just personal.
JOIN grouping is pretty powerful and can get you out of those sticky situations that involve mixed table relationship rules. I hope this was informative in some way.
Want to use code from this post? Check out the license.
Reader Comments
I'm not sure why, but the right join makes the most sense to me. I do the transaction pretty much exactly as you have it...inner joins first followed by left and right joins. It just seems logical to me. You get the results you want from inner joining the first tables, then from that result, you right join that on the 3rd table, and so on. It may be the way I think about the tables. I'll start with one then add more and more until I get the result I want.
Ben,
Another great post!
Very well laid out and extremely well documented!
I know it take a lot of time to write such detailed examples on these types of issues, so I just wanted to say thanks!
--
Ken
@Gareth,
I think the use of RIGHT OUTER JOIN vs. JOIN grouping is purely personal. I think I just don't like it because I think in a very top-down approach to most things. In a query like this, I think, Ok the primary data is Company, so let's get that first; then, let's get everything else that needs to be found.
By selecting the phone and contact information first, my brain just gets confused about what we are trying to do. But again, this is all just very personal; it's like my use of white space in the code - I love a lot of white space because that's how I can read it. Other people hate it - doesn't make it right or wrong one way or the other. As long as you're getting the right results :)
@Ken,
Thanks a lot for the feedback. Glad this stuff gets appreciated, and especially on a post like this, which actually did take a good amount of time with the images and all the different SQL sets. Most posts go much quicker.
very nice post, very informative, i got much from here
Good Job
Regards
Ali Raza
Lahore Pakistan
I know that you said that you found the RIGHT OUTER JOIN to be unattractive but I would like to go further in saying that a RIGHT OUTER JOIN is *never* necessary and should always be avoided. The only use I have ever had for a ROJ is when I wanted to quickly change a query to see what the results might change.
Also, why did you wrap the forth approaches nested join in parenthesis? This is unnecessary in any RDBMS I have encountered, but I do not know if there was a reason for this. As far as I know, as long as your joins are nested, the order of operations is implied and easily interpreted by any developer as long as the nested join is indented.
@Tyler,
To be quite honest, I learned it using the parenthesis and never tried it without them. After reading your comment, however, I did just that and it worked fine. I am going to leave in the parenthesis as I think it adds another level of clarity. That is just personal, of course, not necessarily a best practice; I am just a fan of visual cues for functionality. Same with math; I would rather see:
1 + (5 * 3)
... even though:
1 + 5 * 3
... is the same equation. To me, the parens just say "Take notice! Some functionality is happening over here and I want it to be clear". But again, its just personal.
As far as right outer joins are concerned, as I have stated, they don't sit well with me and my desire to have a top-down approach to data selection; however, I would be curious if you could expand upon your beliefs as they seem strong (and I don't mean that in a bad way).
@Ben
My beliefs are strong but just as with you RIGHT OUTER JOINS to me just don't make sense. It is a convention nothing more, but a convention that would make me scowl at any fellow developer who passed off code to me that has ROJs in it.
@Tyler,
But why would you "scowl" at the fellow developer? I have never had a reason not to use right outer joins, other than there are other methods for doing the same thing. I find it much more straight forward and clearer in my mind to use a right outer join on a table than to use grouped joins. e.g. inner join first 2 tables (now we have the "left" table), now get results from a 3rd table ("right" table) and join on the inner-joined tables, but only return results that are contained in the 3rd table. This makes perfect sense to me, and doesn't appear to have any detractors other than some people like to do it one way, and others, like myself, like to do it the correct way :p :D (kidding) Like Ben said, it all seems a personal choice, which is probably why it was created this way.
Ben, you rule. This blog post really helped me understand how to formulate a query that I'd been staring at for ages. Mine was slightly more complicated, I had 5 tables to join with a similar rule to your example.
SELECT A.ID AS CategoryID, A.Name AS CategoryName,
B.ID AS SubCategoryID, B.Name AS SubCategoryName, B.Number AS SubCategoryNumber,
C.ID, C.Name,
D.ID AS D_ID, D.Data,
E.ID AS ScoreID , E.Score
FROM Table1 A
INNER JOIN Table2 B
ON A.ID = B.CategoryID
LEFT OUTER JOIN
(
Table3 C
INNER JOIN Table4 D
ON C.ID = D.KeyIndicatorID
AND D.School = #URL.ID#
)
ON B.ID = C.SubCategoryID
LEFT OUTER JOIN Table5 E
ON B.ID = E.SubCategoryID
AND E.School = #URL.ID#
ORDER BY A.ID, B.ID, C.OrderBy, C.ID
@Duncan,
Glad to help out. I have become a big fan of grouping my joins. I think it makes nice statements about "cohesive units" of data. For example, I might group the joining of a Contact to ContactInformation, thereby stating that the resultant record is the "full contact" information.
Nice! Great post and well taught. Congratulations
thanks Ben. I have been searching for a high quality explanation to nested joins and this example is excellent. Keep up the good posts.
Really nice explanation thanks a lot for sharing with us,Good Work Keep it up...
Excellent post! Solved in 2 min a problem I worked for some hours on...
Yes, excellent! I've always been using the derived table alternative for years, but this is clearly more elegant.